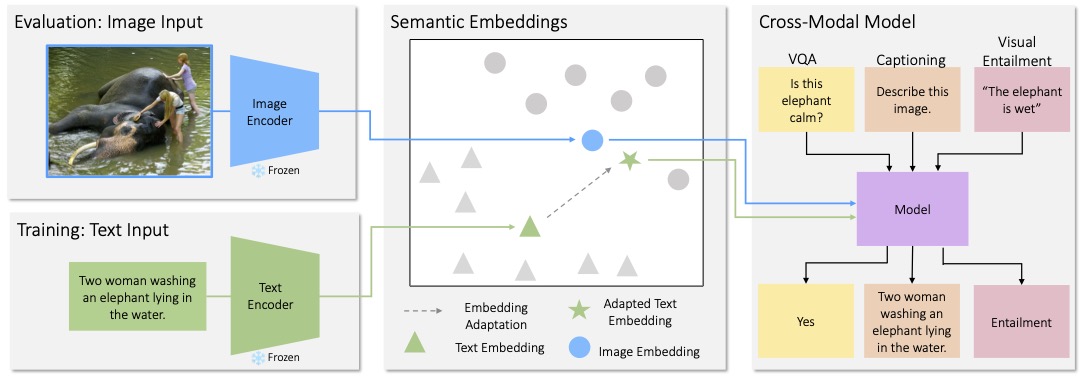
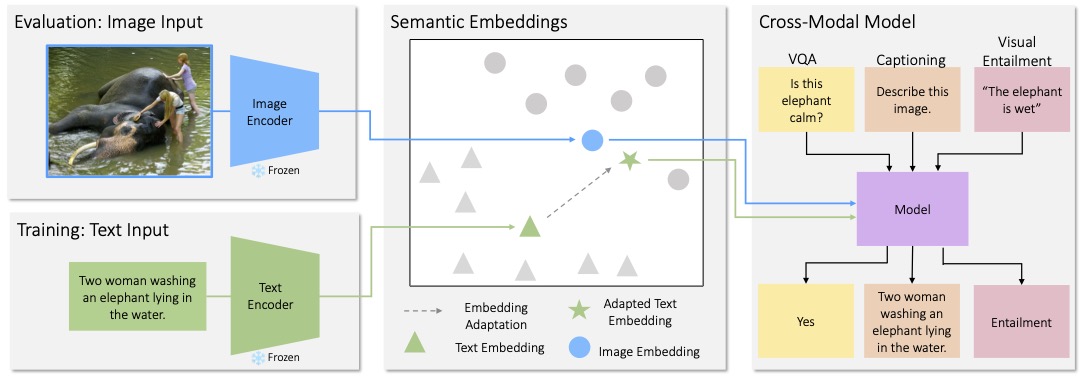
Many high-level skills that are required for computer vision tasks, such as parsing questions, comparing and contrasting semantics, and writing descriptions, are also required in other domains such as natural language processing. In this project, we ask whether it is possible to learn those skills from textual data and then transfer them to vision tasks without ever training on visual training data. Key to our approach is exploiting the joint embedding space of contrastively trained vision and language encoders. In practice, there can be systematic differences between embedding spaces for different modalities in contrastive models, and we analyze how these differences affect our approach and study strategies to mitigate this concern. We produce models using only text training data on four representative tasks: image captioning, visual entailment, visual question answering and visual news, and evaluate them on standard benchmarks using images. We find these models generally perform close to models trained on images, while surpassing prior work for captioning and visual entailment in this text only setting by over 9 points, and outperforming all prior work on visual news by over 30 points. We also showcase a variety of stylistic image captioning models that are trained using no image data and no human-curated language data, but instead using readily-available text data from books, the web, or language models.
We use Vision and Language models trained with a contrastive loss. These models learn to embed text and images into a shared space such that vectors for matching images and captions are close together, and vectors for unrelated images and captions are far apart. We propose a method called Cross modaL transfer On Semantic Embeddings (CLOSE) to take advantage of these learned embeddings. During training, the text inputs are encoded into a vector using the (frozen) text encoder from a contrastive model, which is then used as an input to a language model. During testing, the visual input is embedded with a (frozen) image encoder and used in place of the text embedding. Because these encoders were explicitly trained to produce embeddings that encode semantics in similar ways, learning to read and process the text vector should naturally translate to the ability to read and process the image vector.
Although we focus on text-to-image transfer in this project, our approach is applicable to other contrastive models such as point clouds, videos and audios, potentially allowing transfer between many other modalities.
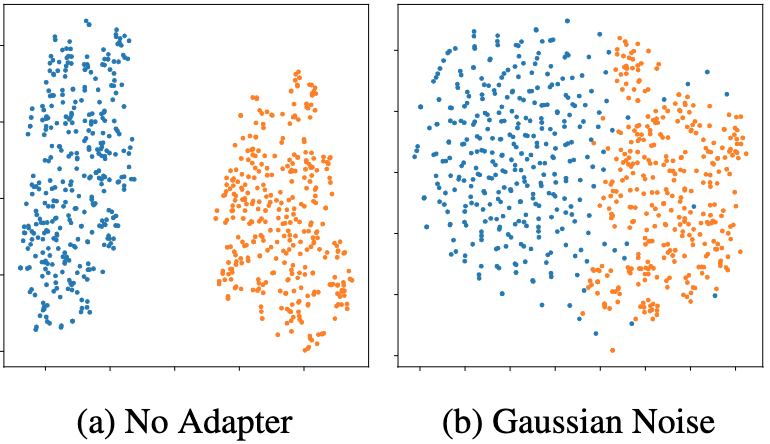
One potential difficulty with this approach is that, while contrastive embeddings do share some structure between modalities, there can still be significant differences between the image and text vectors in practice. This phenomenon is known as the modality gap. For example, on COCO captions the average cosine similarity between an image and paired caption is only 0.26, while the average similarity between two unrelated captions is 0.35. The root cause is that cross-entropy loss used by contrastive models only requires paired image and text vectors to be close relative to random image and text pairs, which does not necessarily mean they are close in absolute terms.
To address this issue, we introduce Gaussian noise that is drawn from a standard normal distribution to the text vectors during training. Intuitively, this noise helps to spread out the text vectors, making them occupy the empty space between the text and image clusters, and also potentially cross the modality gap to overlap with the image vectors. It therefore increases our chance of sampling unseen data points from an otherwise low probabilty space with only text data. The noise also encourages the model to be more robust to minor changes or variations to the input vectors, and thus be better prepared for the shift caused by switching from text to image vectors.
Text-to-image transfer is a relatively unexplored setting, so we conduct extensive experiments to establish that CLOSE can handle this domain shift without much performance drop. We compare models trained with CLOSE on text alone to models trained with images and text on four vision-and-language tasks: captioning, visual questioning answering (VQA), visual entailment (VE), and visual news captioning (VN). We find the text-only models generally perform reasonably close to the versions trained with images, showing that CLOSE can effectively transfer many skills across modalities. We surpass the previous best method in captioning by 17 CIDEr (78.2 vs. 95.4) and visual entailment by 9 points (66.6 vs. 75.9), making our method state-of-the-art for these settings by a large margin. There are no prior results for VQA and visual news in this text-only setting, but we are still able to surpass the previous best benchmark model trained with images in visual news (50.5 vs 80.8 CIDEr).
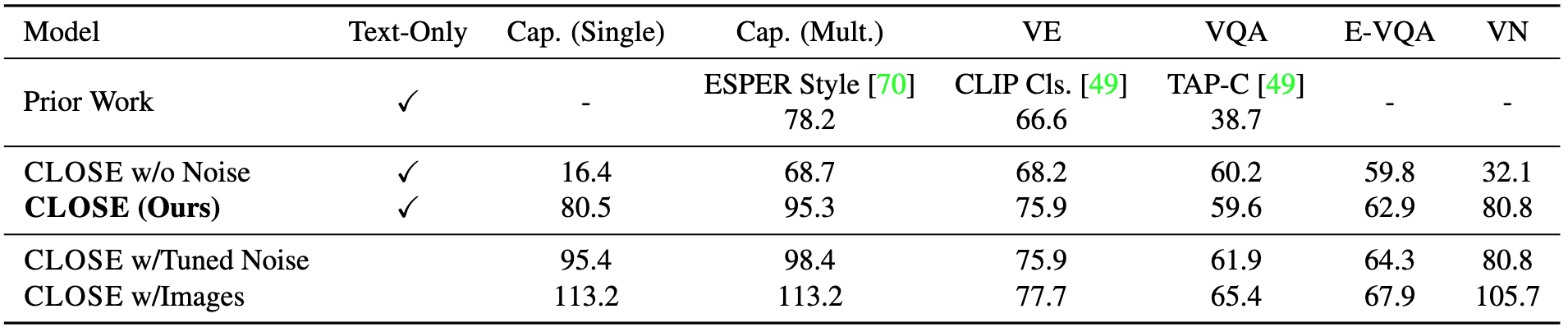
The model without noise is shown to emphasize the important role played by Gaussian noise to address the modality gap. In the last row, we also train the model using the same architecture but with image data so we can see clearly the amount of performance drop when swapping images with text.
Note these numbers are reported using the original CLIP model and they can be further improved by using a better CLIP model such as OpenCLIP, EVA-CLIP, etc. We report some of the comparisons in the appendix of the paper.
We propose two adapters that further modify the text vectors being used during training and analyze if they help boost CLOSE's performance, and our answer is positive:
We learn the modality shift by training a linear model to minimize the Euclidean distance between the adapted text vector and its paired image vector. We continue to add Gaussian noise after applying this model.
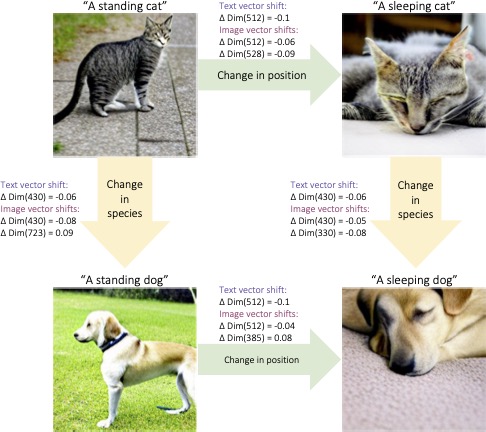
Even in principle, we do not expect there to be a perfect one-to-one mapping between text and image vectors because an image vector can be similar to many different text vectors that describe different parts or details of the image. This motivates us to approach the problem from the perspective of better understanding how text is distributed around its related images and vice versa. We perform a small case study by selecting four image/caption pairs that represent two different semantic changes, and then examine how the image or text vectors shift according to these changes. We observe that the text vectors move in a more consistent manner when the species or positions of the animals are changed, while the image vectors shift in more inconsistent directions. This is likely due to minor changes in the image semantics, such as slight modifications in the animals' appearance, background, or camera position, that are not captured in the text but are naturally encoded in the images. As a result, a shift in the text vector does not translate to an accurately predictable shift in the paired image vector. More generally, this inconsistency reflects the fact that images often capture more details than text, and thus are rarely beautifully aligned with their text counterparts.
Question: Will adding noise impose a limit on the resolution that the model can work at?
To clarify, the concern of potential resolution drop due to noise is more valid if we trained models directly on images and we added noise to images, which is different from what we do. In that hypothesized scenario, the noise could provide regularization effect and therefore could still improve the performance of the resulting model (if it had been tuned to achieve a good resolution vs. regularization tradeoff). Here we only train on text data, and because text and image vectors are so different themselves (see the prior section on modality gap), a reasonably scaled noise can only help.
It is still interesting to study how much granularity in the vector embeddings that CLOSE can capture. We find that, by feeding the above four images to CLOSE, it is able to distinguish the small differences in the image semantics and produce accurate captions. Respectively for each image, the predicted captions are: a standing cat -> a cat that is standing on the sidewalk; a sleeping cat -> a cat that is laying down on a bed; a standing dog -> a dog that is standing in the grass; a sleeping dog -> a dog is curled up on a rag.
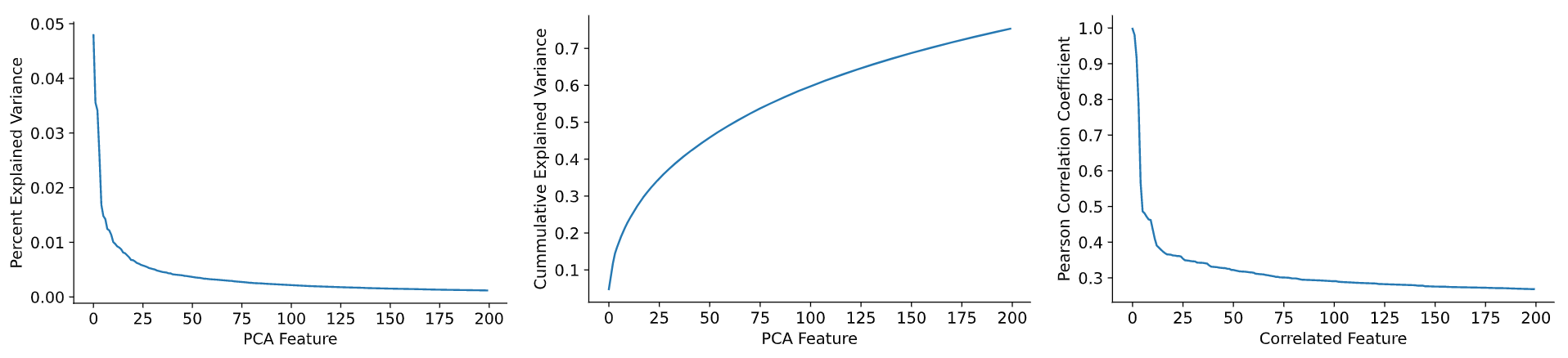
We further analyze how image and text vectors typically differ by computing the differences between image/text pairs in an auxiliary corpus of COCO. We center these differences and apply PCA. The first two plots in the figure below show that the first few directions explain a large portion of the variance and thus the differences often occur in similar directions. The third plot, which shows the Pearson correlation coefficient for the most related features, confirms with our intuition that a number of these features are highly correlated.
Indeed, image/text pairs tend to move in a structured manner that follows a particular "shape". We capture this subtle relationship by studying the covariance matrix of the differences between text-image vectors. We then modify our Gaussian noise that is added to the text during training to better simulate this co-movement.
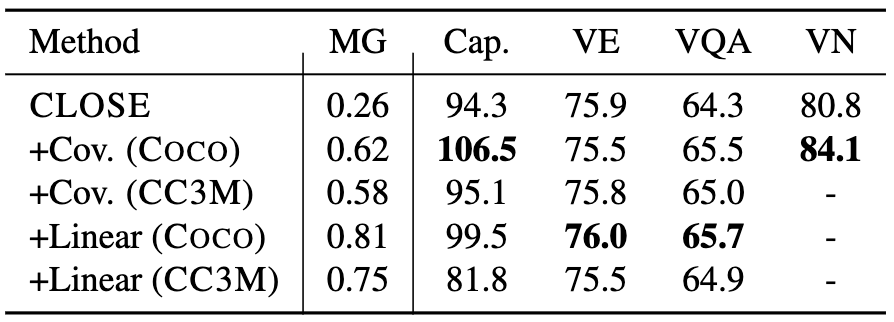
The following table shows the results of applying the aforementioned adapters. We observe large improvements on captioning, modest improvements on VQA and visual news, and similar performance on visual entailment.
Using the first row as a baseline, we see that a smaller gap does not always correspond to a better performance. So what is missing here? Is there a limit on the amount of performance gain we can get if we only try to close the modality gap as defined earlier? If so, maybe we should consider matching higher moments as well? For example the second row also tries to make the difference of the variances smaller.
In this section, we present some qualitative examples from manually scraped web images for stylistic captioning and from the test set of visual news. Details of the experiment setup can be found in the paper.

We demonstrate that a diverse range of natural language data sources can be used to learn different styles (here we show four), each of which uses a different method of collecting training data. The ego-centric captioner learns to use a variety of first-person language while accurately describing the image; The uplifting captioner is able to add warm and optimistic details to its caption; The character-based captioner uses the correct names and image content, while sometimes making up plausible events that could give additional context to the image as if it was a scene in a book or a movie; The reviews captioner uses a variety of language to write positive reviews of the items or the scene in the picture.

We observe that close to 50% of time, the predicted captions can be more descriptive (i.e. they can include more details), indicating there is room for this visual news captioner to grow. However, the majority of captions provided by human are brief as well, so let's not blame CLOSE for being terse because that is all what it has been learning from. There are also some cases in which the predicted captions are better than the ones provided by human (the target captions). But overall, the general sense of both the news images and articles are present in the predicted captions.