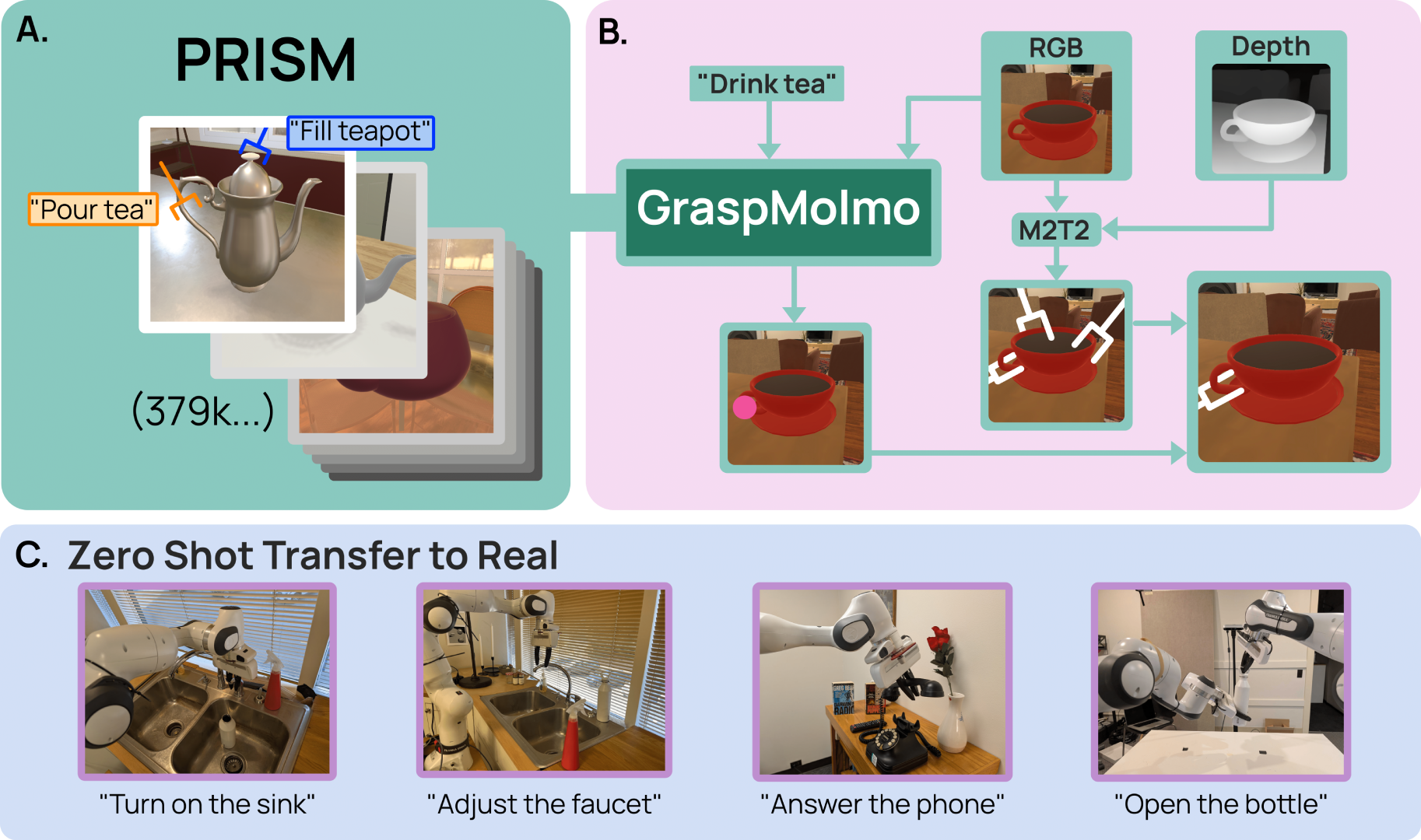
We present GraspMolmo, a generalizable open-vocabulary task-oriented grasping (TOG) model. GraspMolmo predicts semantically appropriate, stable grasps conditioned on a natural language instruction and... a single RGB-D frame. For instance, given “pour me some tea,” GraspMolmo selects a grasp on a teapot handle rather than its body. Unlike prior TOG methods, which are limited by small datasets, simplistic language, and uncluttered scenes, GraspMolmo learns from PRISM, a novel large-scale synthetic dataset of 379k samples featuring cluttered environments and diverse, realistic task descriptions. We fine-tune the Molmo visual-language model on this data, enabling GraspMolmo to generalize to novel open-vocabulary instructions and objects. In challenging real-world evaluations, GraspMolmo achieves state-of-the-art results, with a 70% prediction success on complex tasks, compared to the 35% achieved by the next best alternative. GraspMolmo also demonstrates the ability to predict semantically correct bimanual grasps zero-shot. We release our synthetic dataset, code, model, and benchmarks to accelerate research in task-semantic robotic manipulation, which, along with videos, are available at the project website.
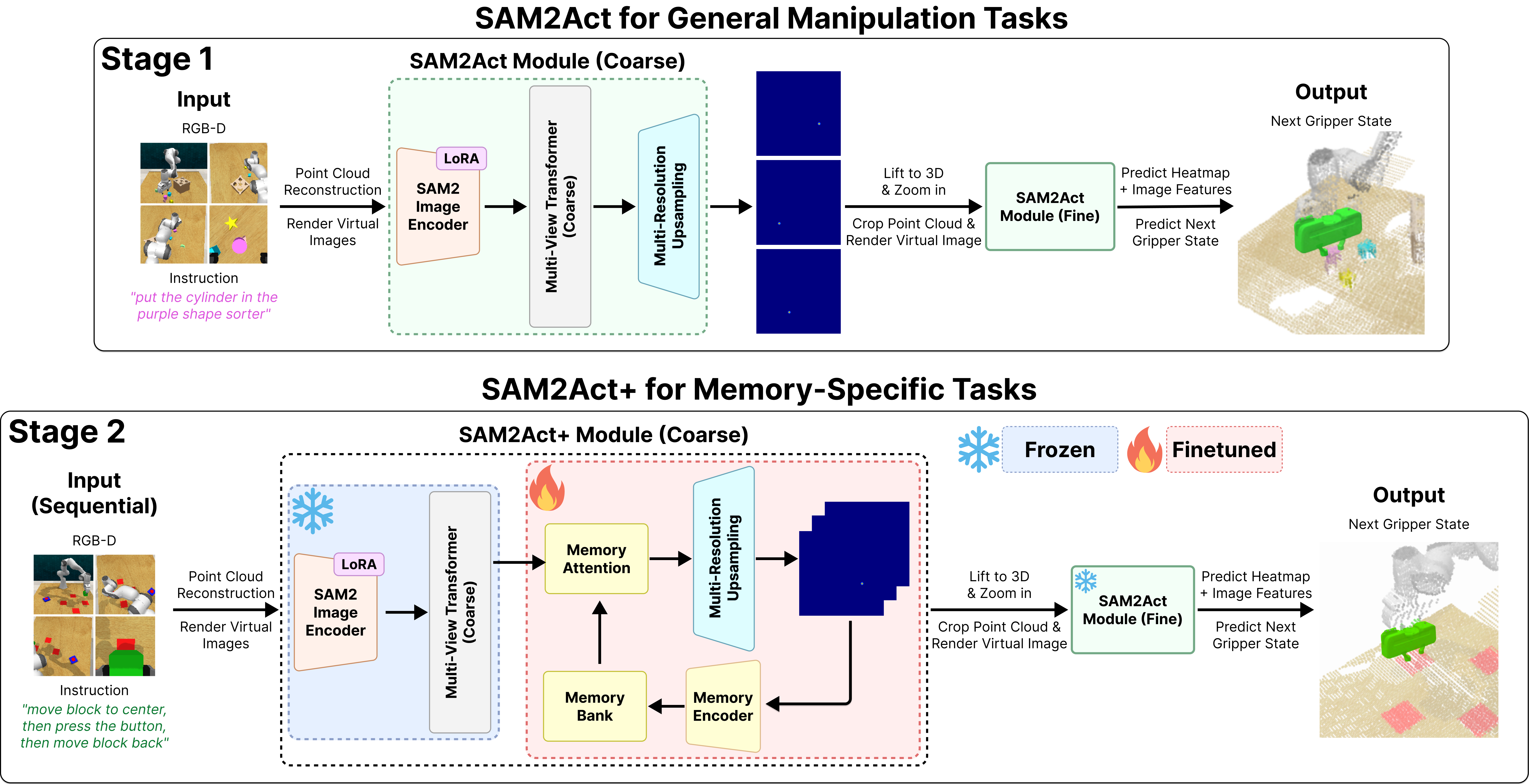
Robotic manipulation systems operating in diverse, dynamic environments must exhibit three critical abilities: multitask interaction, generalization to unseen scenarios, and spatial memory. While si... gnificant progress has been made in robotic manipulation, existing approaches often fall short in generalization to complex environmental variations and addressing memory-dependent tasks. To bridge this gap, we introduce SAM2Act, a multi-view robotic transformer-based policy that leverages multi-resolution upsampling with visual representations from large-scale foundation model. SAM2Act achieves a state-of-the-art average success rate of 86.8% across 18 tasks in the RLBench benchmark, and demonstrates robust generalization on The Colosseum benchmark, with only a 4.3% performance gap under diverse environmental perturbations. Building on this foundation, we propose SAM2Act+, a memory-based architecture inspired by SAM2, which incorporates a memory bank, an encoder, and an attention mechanism to enhance spatial memory. To address the need for evaluating memory-dependent tasks, we introduce MemoryBench, a novel benchmark designed to assess spatial memory and action recall in robotic manipulation. SAM2Act+ achieves an average success rate of 94.3% on memory-based tasks in MemoryBench, significantly outperforming existing approaches and pushing the boundaries of memory-based robotic systems.
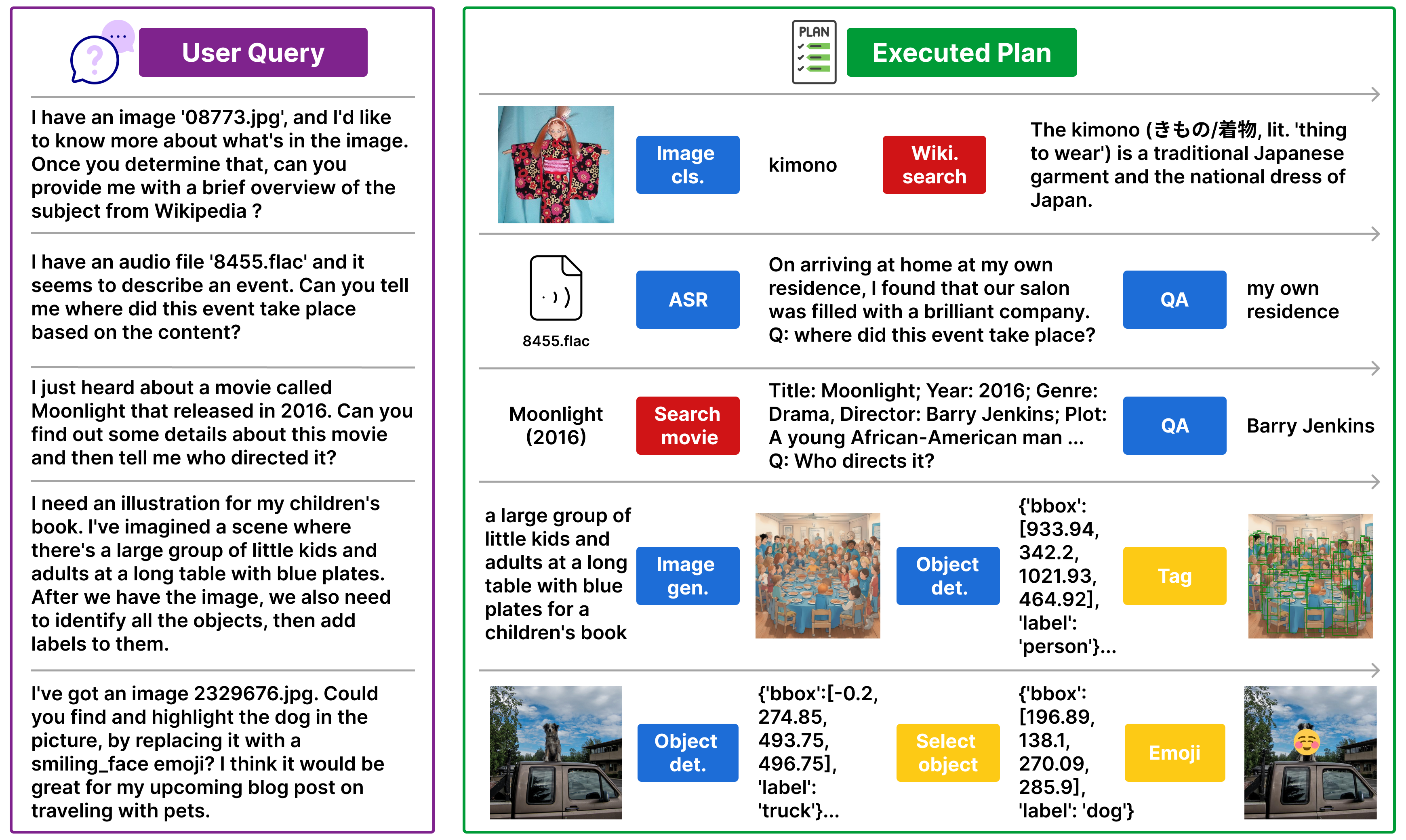
Real-world multi-modal problems are rarely solved by a single machine learning model and often require multi-step computational plans that involve stitching several models. Tool-augmented LLMs hold tr... emendous promise for automating the generation of such computational plans. However, the lack of standardized benchmarks for evaluating LLMs as planners for multi-step multi-modal tasks has prevented a systematic study of planner design decisions. To answer these questions and more, we introduce m&ms: a benchmark containing 4K+ multi-step multi-modal tasks involving 33 tools that include multi-modal ML models, (free) public APIs, and image processing modules. For each of these task queries, we provide automatically generated plans using this realistic toolset. We further provide a high-quality subset of 1,565 task plans that are human-verified and correctly executable. m&ms tasks are granular in difficulty, with 70 queries that require a single tool, 159 need two tools, and 653 need three tools. In terms of tools, there are 33 unique tools in total across three different categories, of which 13 are multi-modal machine learning models on HuggingFace, 11 are image processing modules from VisProg, and 9 are free public APIs from RapidAPI. Our final dataset includes 317 representative tool sequences where each sequence consists of a mix of tools across categories and maps to multiple unique queries.

Existing image editing models struggle to meet real-world demands. Despite excelling in academic benchmarks, they have yet to be widely adopted for real user needs. Datasets that power these models of... ten use artificial edits, lacking the scale and ecological validity necessary to address the true diversity of user requests. We introduce RealEdit, a large-scale image editing dataset with authentic user requests and human-made edits sourced from Reddit. RealEdit includes a test set of 9,300 examples to evaluate models on real user requests. Our results show that existing models fall short on these tasks, highlighting the need for realistic training data. To address this, we introduce 48,000 training examples and train our RealEdit model, achieving substantial gains—outperforming competitors by up to 165 Elo points in human judgment and 92% relative improvement on the automated VIEScore metric. We deploy our model on Reddit, testing it on new requests, and receive positive feedback. Beyond image editing, we explore RealEdit's potential in detecting edited images by partnering with a deepfake detection non-profit. Finetuning their model on RealEdit data improves its F1-score by 14 percentage points, underscoring the dataset's value for broad applications.
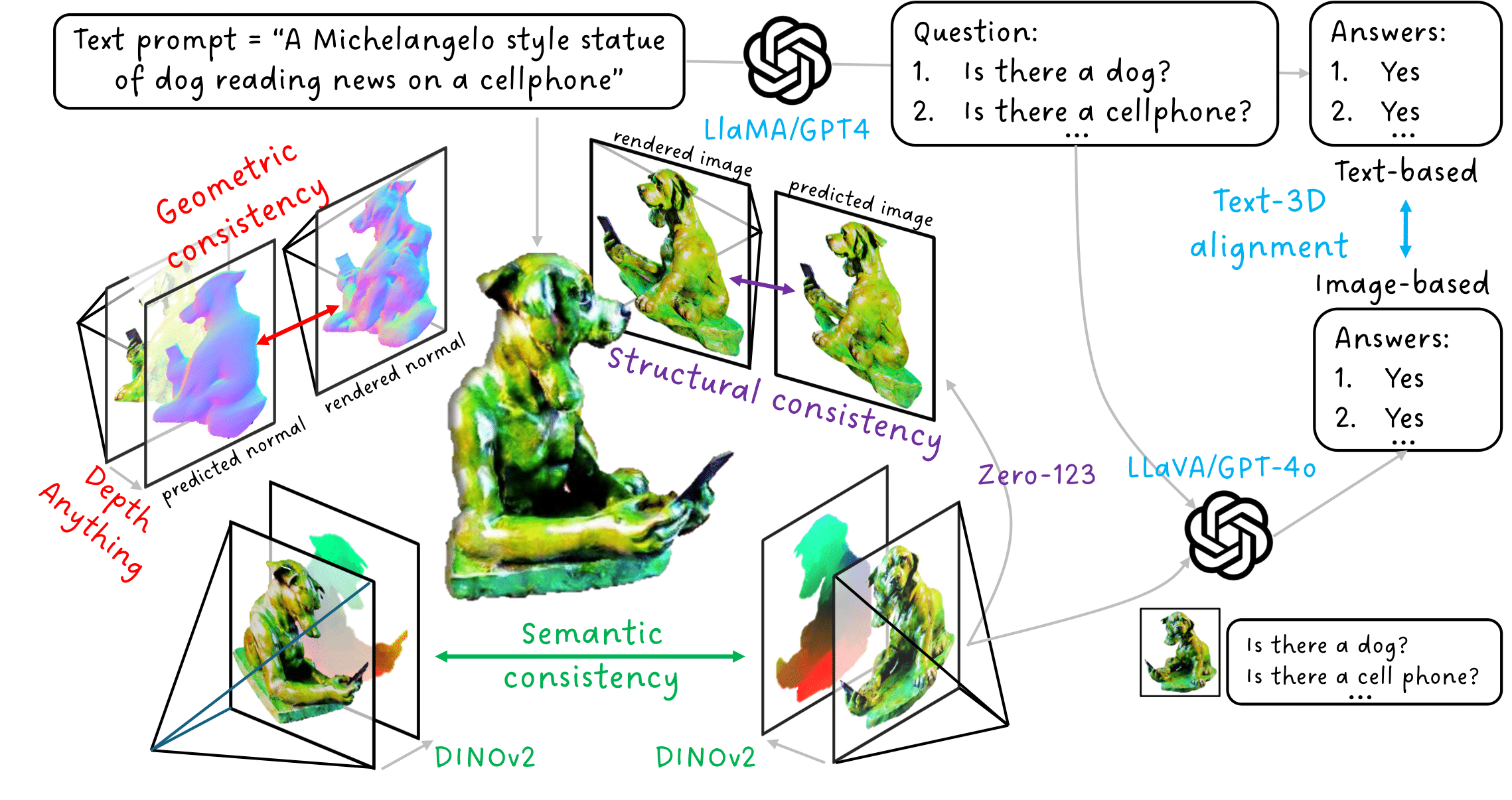
Despite significant advancements in 3D generation, current systems often struggle to produce high-quality 3D assets that are visually appealing and geometrically and semantically consistent across mul... tiple viewpoints. Existing evaluation metrics frequently overlook geometric quality or rely on black-box multimodal large language models for coarse assessments. We introduce Eval3D, a fine-grained, interpretable evaluation tool designed to assess the quality of generated 3D assets based on various distinct yet complementary criteria. Our key insight is that many desired properties of 3D generation, such as semantic and geometric consistency, can be effectively captured by measuring the consistency among various foundation models and tools. Eval3D leverages a diverse set of models and tools as probes to evaluate inconsistencies in generated 3D assets across different aspects. Compared to prior work, Eval3D provides pixel-wise measurements, enables accurate 3D spatial feedback, and aligns more closely with human judgments. We comprehensively evaluate existing 3D generation models using Eval3D and highlight the limitations and challenges of current models.
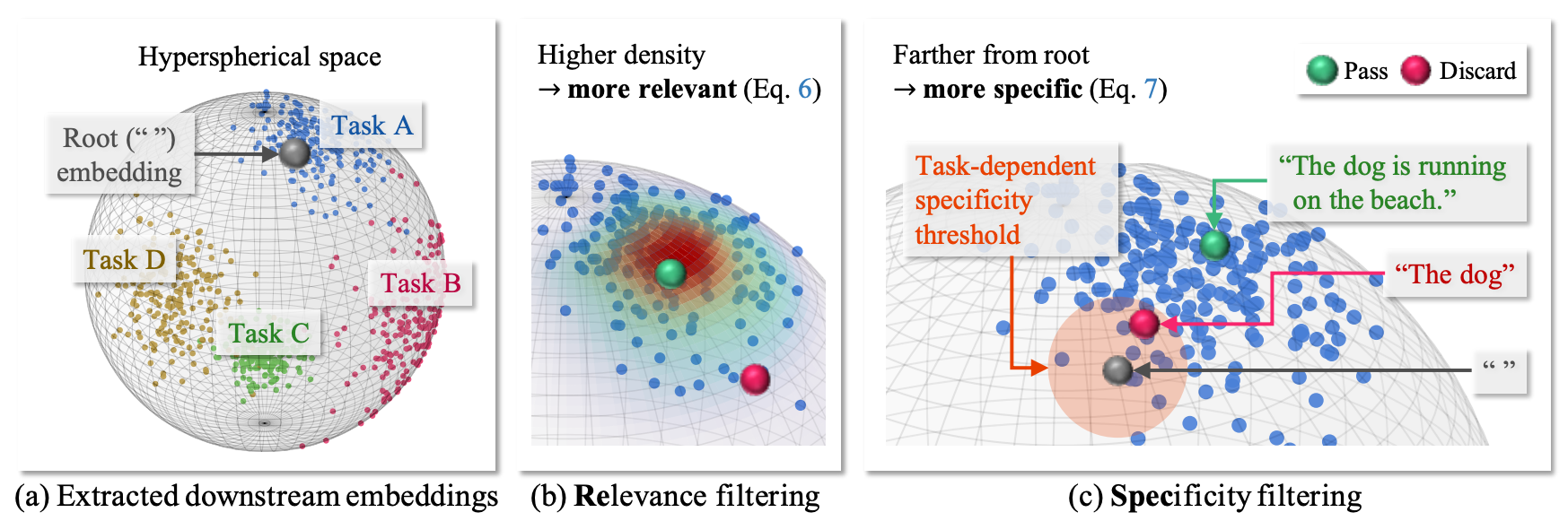
The rapid growth of video-text data presents challenges in storage and computation during training. Online learning, which processes streaming data in real-time, offers a promising solution to these i... ssues while also allowing swift adaptations in scenarios demanding real-time responsiveness. We propose ReSpec, a Relevance and Specificity-based online filtering framework that selects data based on four criteria: (i) modality alignment for clean data, (ii) task relevance for target-focused data, (iii) specificity for informative and detailed data, and (iv) efficiency for low-latency processing. Relevance is determined by the probabilistic alignment of incoming data with downstream tasks, while specificity employs the distance to a root embedding representing the least specific data as an efficient proxy for informativeness. By establishing reference points from target task data, ReSpec filters incoming data in real-time, eliminating the need for extensive storage and compute. Evaluating on large-scale datasets WebVid2M and VideoCC3M, ReSpec attains state-of-the-art performance on five zero-shot video retrieval tasks, using as little as 5% of the data while incurring minimal compute.
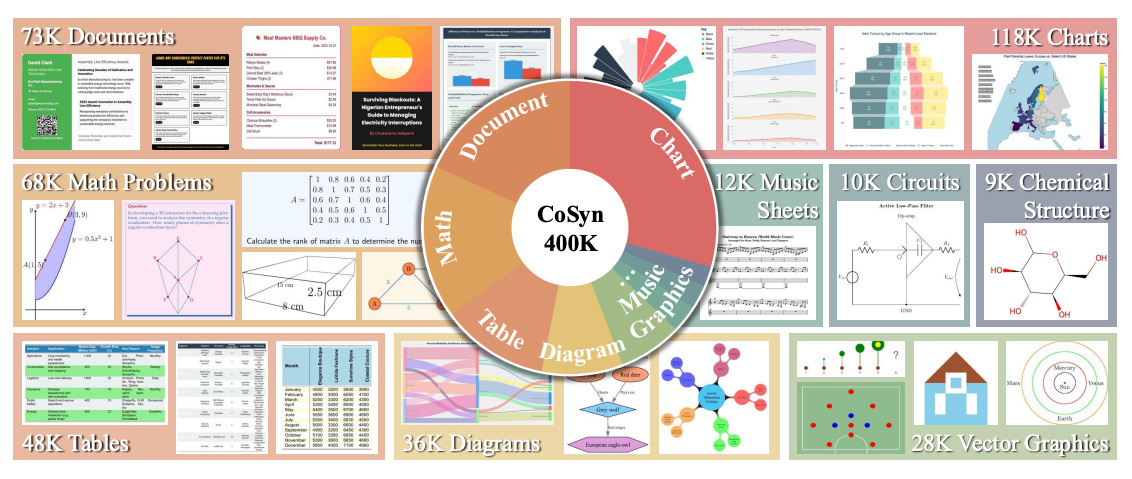
Reasoning about images with rich text, such as charts and documents, is a critical application of vision-language models (VLMs). However, VLMs often struggle in these domains due to the scarcity of di... verse text-rich vision-language data. To address this challenge, we present CoSyn, a framework that leverages the coding capabilities of text-only large language models (LLMs) to automatically create synthetic text-rich multimodal data. Given input text describing a target domain (e.g., "nutrition fact labels"), CoSyn prompts an LLM to generate code (Python, HTML, LaTeX, etc.) for rendering synthetic images. With the underlying code as textual representations of the synthetic images, CoSyn can generate high-quality instruction-tuning data, again relying on a text-only LLM. Using CoSyn, we constructed a dataset comprising 400K images and 2.7M rows of vision-language instruction-tuning data. Comprehensive experiments on seven benchmarks demonstrate that models trained on our synthetic data achieve state-of-the-art performance among competitive open-source models, including Llama 3.2, and surpass proprietary models such as GPT-4V and Gemini 1.5 Flash. Furthermore, CoSyn can produce synthetic pointing data, enabling VLMs to ground information within input images, showcasing its potential for developing multimodal agents capable of acting in real-world environments.
Modern robots vary significantly in shape, size, and sensor configurations used to perceive and interact with their environments. However, most navigation policies are embodiment-specific; a policy le... arned using one robot's configuration does not typically gracefully generalize to another. Even small changes in the body size or camera viewpoint may cause failures. With the recent surge in custom hardware developments, it is necessary to learn a single policy that can be transferred to other embodiments, eliminating the need to (re)train for each specific robot. In this paper, we introduce RING (Robotic Indoor Navigation Generalist), an embodiment-agnostic policy, trained solely in simulation with diverse randomly initialized embodiments at scale. Specifically, we augment the AI2-THOR simulator with the ability to instantiate robot embodiments with controllable configurations, varying across body size, rotation pivot point, and camera configurations. In the visual object-goal navigation task, RING achieves robust performance on real unseen robot platforms (Stretch RE-1, LoCoBot, Unitree's Go1), achieving an average of 72.1% and 78.9% success rate across 5 embodiments in simulation and 4 robot platforms in the real world.
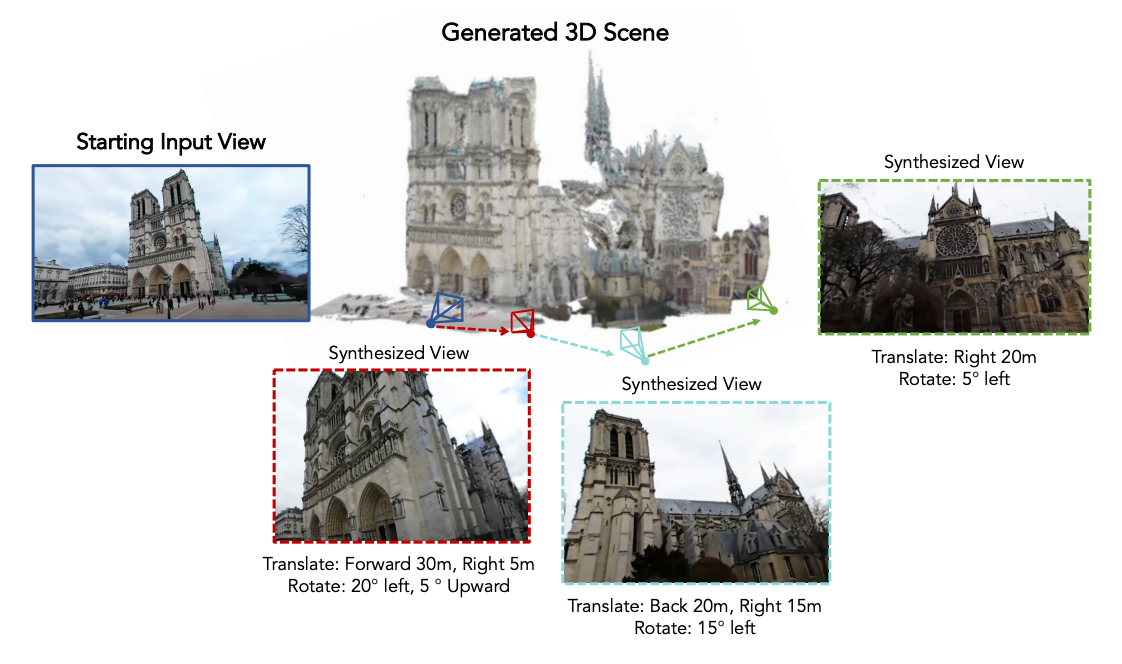
Three-dimensional (3D) understanding of objects and scenes plays a key role in humans' ability to interact with the world and has been an active area of research in computer vision, graphics, and robo... tics. Large-scale synthetic and object-centric 3D datasets have proven effective in training models with 3D understanding of objects. However, applying a similar approach to real-world objects and scenes is challenging due to a lack of large-scale data. Videos are a potential source for real-world 3D data, but finding diverse yet corresponding views of the same content has been difficult at scale. Furthermore, standard videos come with fixed viewpoints, determined at the time of capture, restricting the ability to access scenes from a variety of perspectives. We argue that large-scale 360 videos can address these limitations by providing scalable corresponding frames from diverse views. In this paper, we introduce 360-1M, a 360 video dataset, and a process for efficiently finding corresponding frames from diverse viewpoints at scale. We train our diffusion-based model, Odin, on 360-1M. Empowered by the largest real-world, multi-view dataset to date, Odin is able to freely generate novel views of real-world scenes. Unlike previous methods, Odin can move the camera through the environment, enabling the model to infer the geometry and layout of the scene. Additionally, we show improved performance on standard novel view synthesis and 3D reconstruction benchmarks.
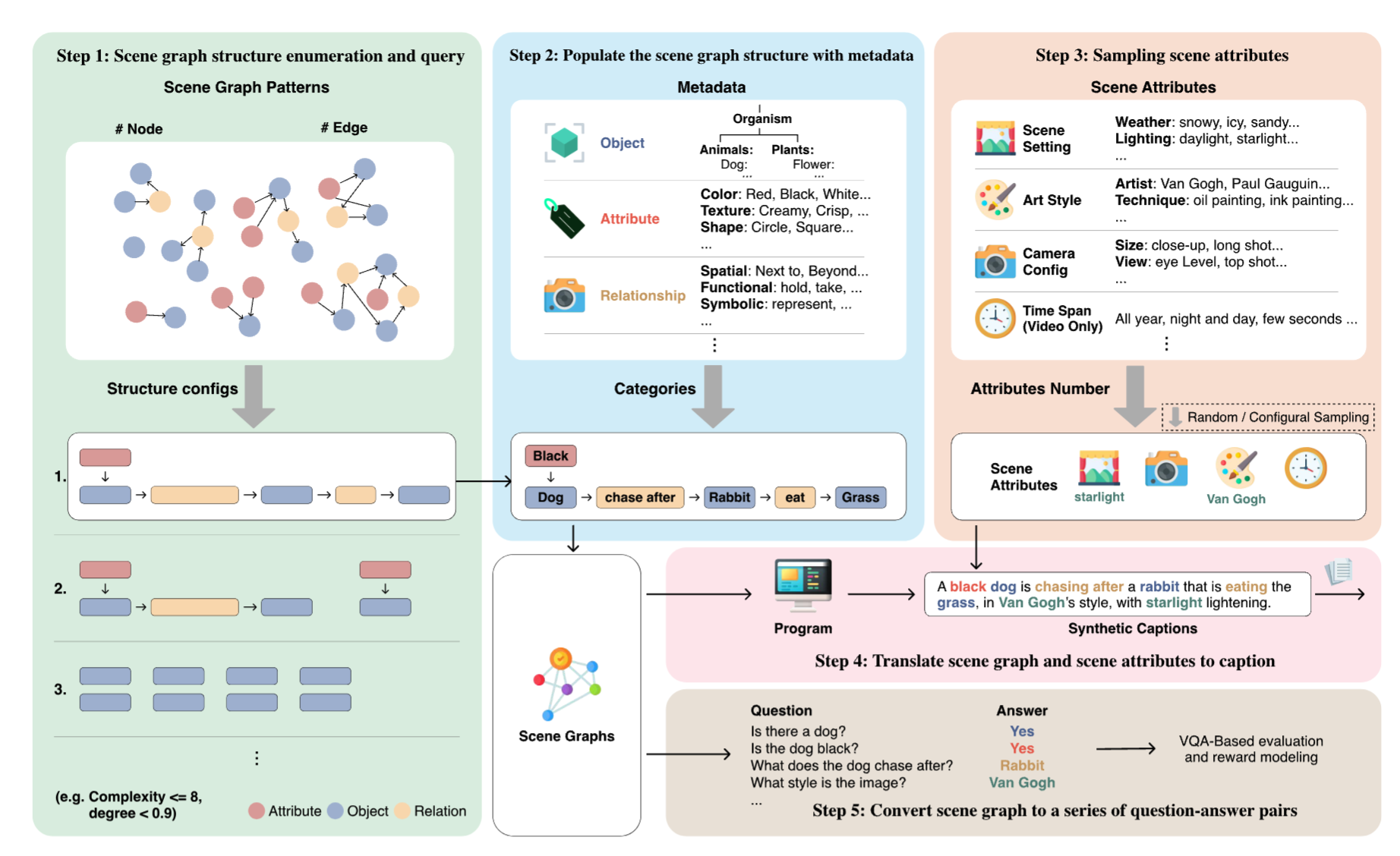
DALL-E and Sora have gained attention by producing implausible images, such as "astronauts riding a horse in space." Despite the proliferation of text-to-vision models that have inundated the internet... with synthetic visuals, from images to 3D assets, current benchmarks predominantly evaluate these models on real-world scenes paired with captions. We introduce Generate Any Scene, a framework that systematically enumerates scene graphs representing a vast array of visual scenes, spanning realistic to imaginative compositions. Generate Any Scene leverages 'scene graph programming', a method for dynamically constructing scene graphs of varying complexity from a structured taxonomy of visual elements. This taxonomy includes numerous objects, attributes, and relations, enabling the synthesis of an almost infinite variety of scene graphs. Using these structured representations, Generate Any Scene translates each scene graph into a caption, enabling scalable evaluation of text-to-vision models through standard metrics. We conduct extensive evaluations across multiple text-to-image, text-to-video, and text-to-3D models, presenting key findings on model performance. We find that DiT-backbone text-to-image models align more closely with input captions than UNet-backbone models. Text-to-video models struggle with balancing dynamics and consistency, while both text-to-video and text-to-3D models show notable gaps in human preference alignment. We demonstrate the effectiveness of Generate Any Scene by conducting three practical applications leveraging captions generated by Generate Any Scene: 1) a self-improving framework where models iteratively enhance their performance using generated data, 2) a distillation process to transfer specific strengths from proprietary models to open-source counterparts, and 3) improvements in content moderation by identifying and generating challenging synthetic data.

Spatial perception is a fundamental component of intelligence. While many studies highlight that large multimodal language models (MLMs) struggle to reason about space, they only test for static spati... al reasoning, such as categorizing the relative positions of objects. Meanwhile, real-world deployment requires dynamic capabilities like perspective-taking and egocentric action recognition. As a roadmap to improving spatial intelligence, we introduce SAT, Spatial Aptitude Training, which goes beyond static relative object position questions to more dynamic tasks. SAT contains 218K question-answer pairs for 22K synthetic scenes across a training and testing set. Generated using a photo-realistic physics engine, our dataset can be arbitrarily scaled and easily extended to new actions, scenes, and 3D assets. We find that even MLMs that perform relatively well on static questions struggle to accurately answer dynamic spatial questions. Further, we show that SAT instruction-tuning data improves not only dynamic spatial reasoning on SAT but also zero-shot performance on existing real-image spatial benchmarks: 23% on CVBench, 8% on the harder BLINK benchmark, and 18% on VSR. When instruction-tuned on SAT, our 13B model matches larger proprietary MLMs like GPT4-V and Gemini-3-1.0 in spatial reasoning.

We introduce OneDiffusion, a versatile, large-scale diffusion model that seamlessly supports bidirectional image synthesis and understanding across diverse tasks. It enables conditional generation fro... m inputs such as text, depth, pose, layout, and semantic maps, while also handling tasks like image deblurring, upscaling, and reverse processes such as depth estimation and segmentation. OneDiffusion allows for multi-view generation, camera pose estimation, and instant personalization using sequential image inputs. Our model takes a straightforward yet effective approach by treating all tasks as frame sequences with varying noise scales during training, allowing any frame to act as a conditioning image at inference time. Our unified training framework removes the need for specialized architectures, supports scalable multi-task training, and adapts smoothly to any resolution, enhancing both generalization and scalability. Experimental results demonstrate competitive performance across tasks in both generation and prediction such as text-to-image, multiview generation, ID preservation, depth estimation, and camera pose estimation despite a relatively small training dataset.
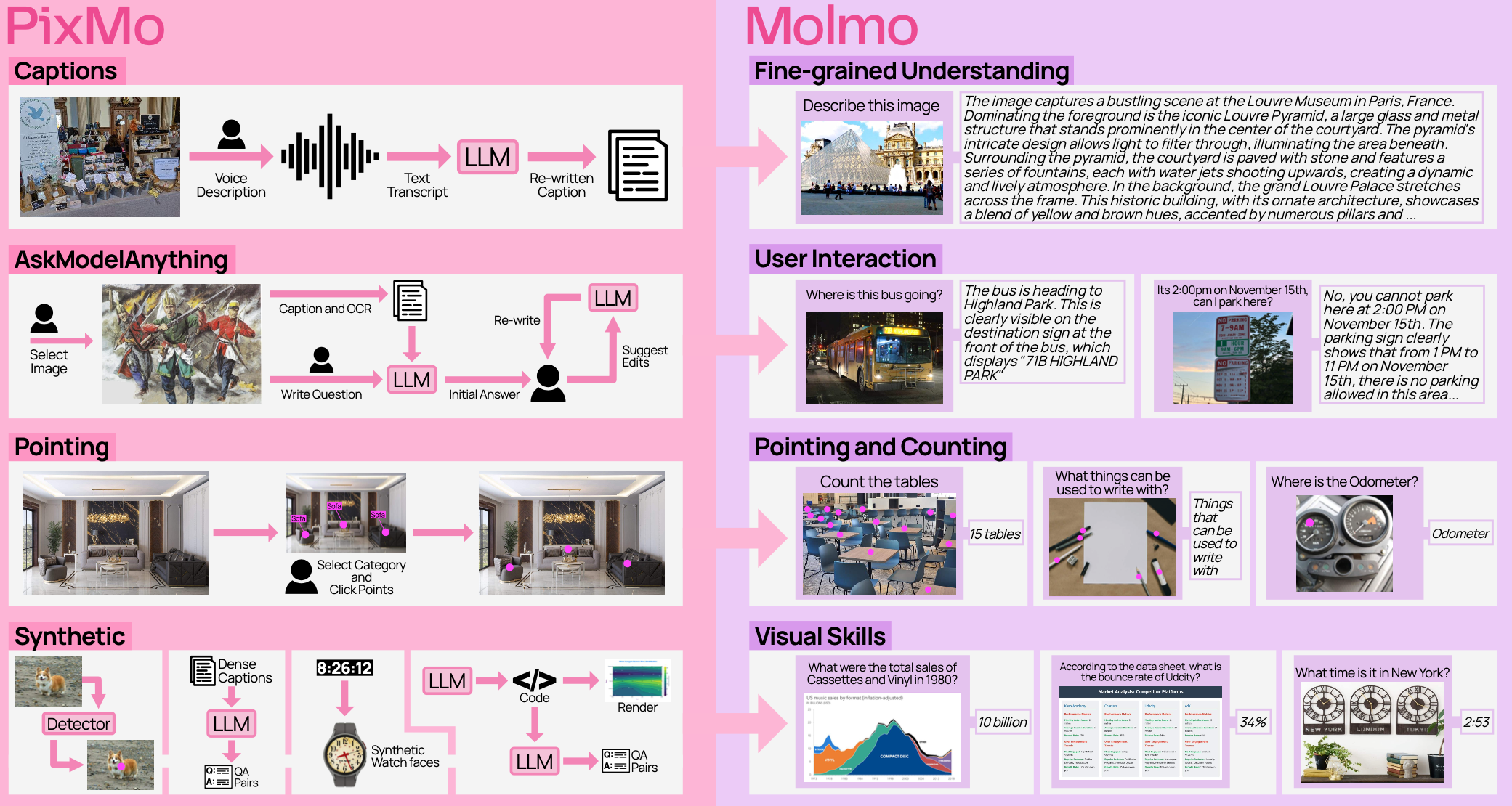
Today's most advanced vision-language models (VLMs) remain proprietary, with open-weight models often relying on synthetic data from these closed systems. This reliance has limited the community's und... erstanding of building performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key contribution is a collection of new datasets called PixMo, including a dataset of highly detailed image captions for pre-training, a free-form image Q&A dataset for fine-tuning, and an innovative 2D pointing dataset, all collected without the use of external VLMs. Our best-in-class 72B model not only outperforms others in the class of open weight and data models but also surpasses larger proprietary models, including Claude 3.5 Sonnet and Gemini 1.5 Pro and Flash, second only to GPT-4o based on both academic benchmarks and a large human evaluation. Our model weights, new datasets, and source code are available at the project website.
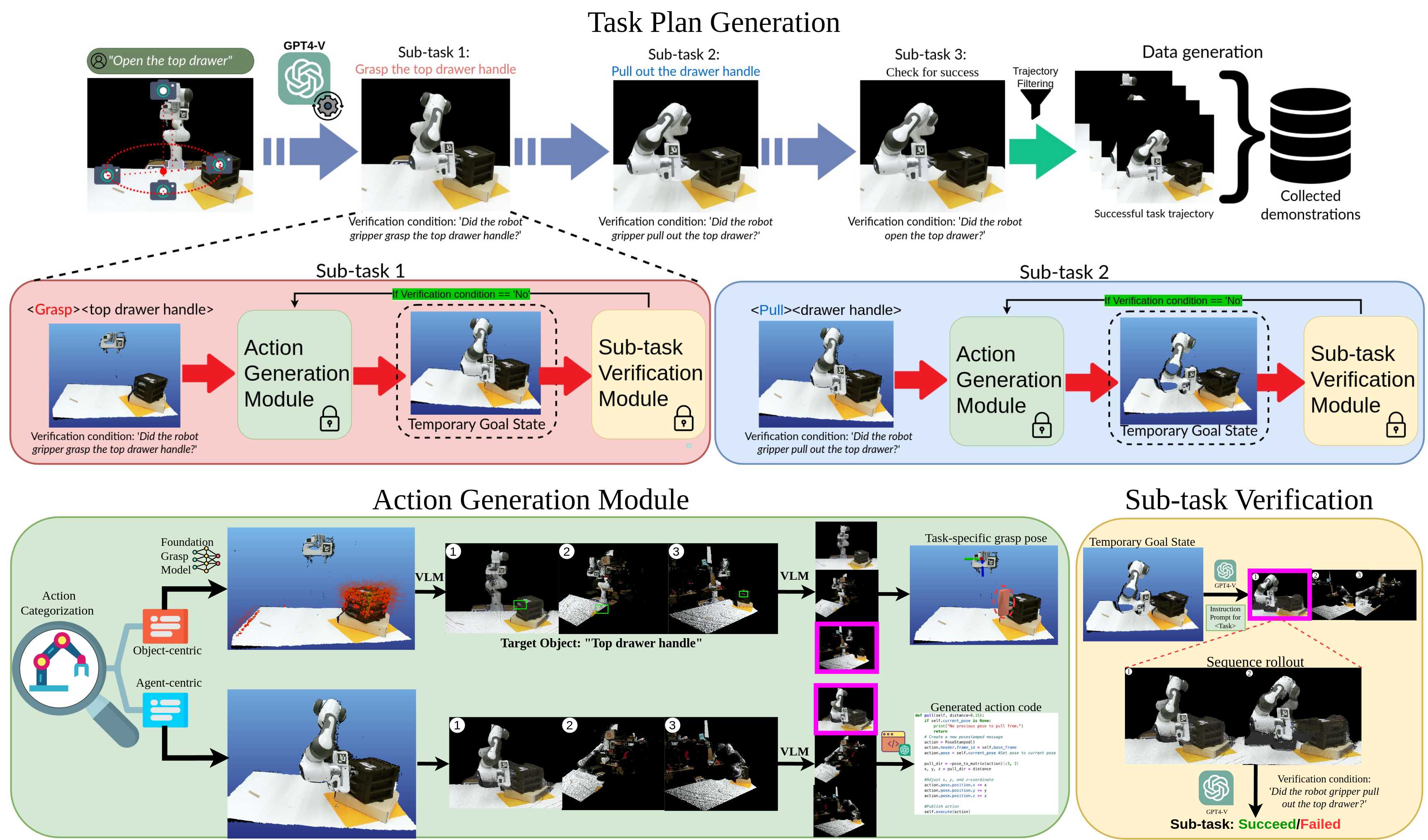
Large-scale endeavors like Open-X-Embodiment and widespread community efforts have contributed to growing the scale of robot demonstration data. However, there is still an opportunity to improve the q... uality, quantity, and diversity of robot demonstration data. Although vision-language models have been shown to automatically generate demonstration data, their utility has been limited to environments with privileged state information, they require hand-designed skills, and are limited to interactions with few object instances. We propose Manipulate-Anything, a scalable automated generation method for real-world robotic manipulation. Unlike prior work, our method can operate in real-world environments without any privileged state information, hand-designed skills, and can manipulate any static object. We evaluate our method using two setups. First, Manipulate-Anything successfully generates trajectories for all 7 real-world and 14 simulation tasks, significantly outperforming existing methods like VoxPoser. Second, Manipulate-Anything's demonstrations can train more robust behavior cloning policies than training with human demonstrations, or from data generated by VoxPoser, Scaling-up, and Code-As-Policies. We believe Manipulate-Anything can be a scalable method for both generating data for robotics and solving novel tasks in a zero-shot setting.
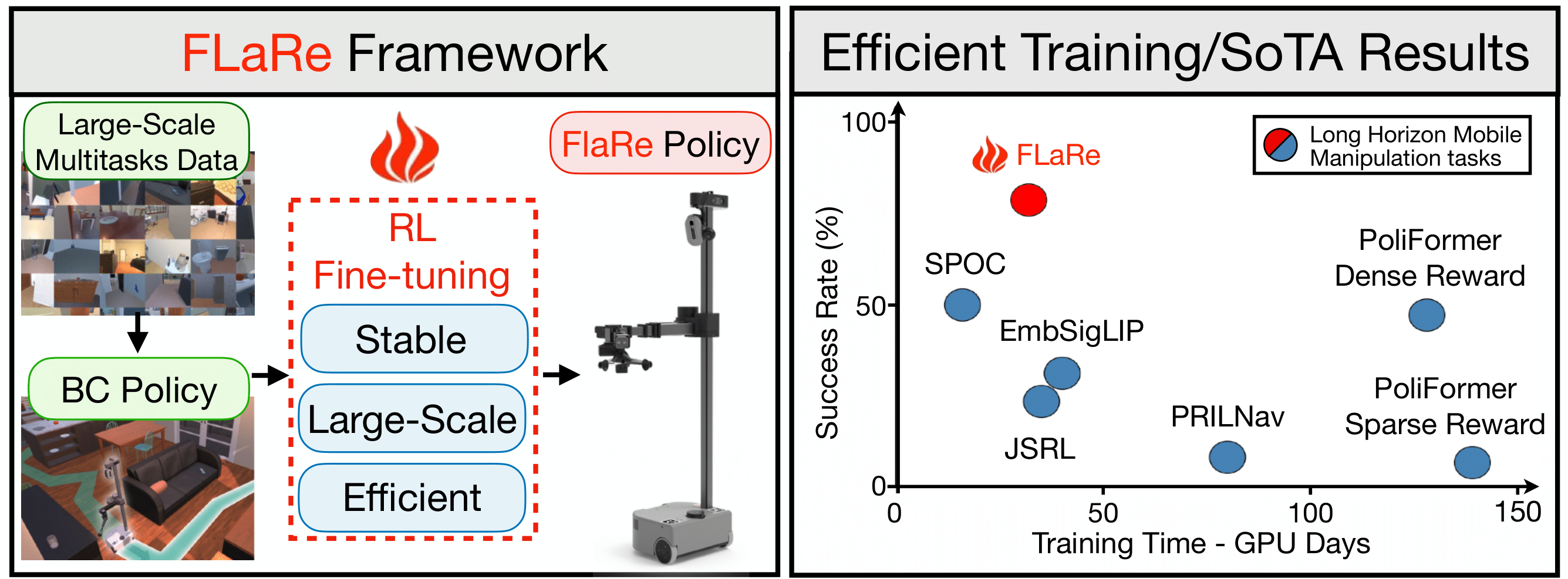
In recent years, the robotics field has initiated several efforts toward building generalist robot policies through large-scale multi-task Behavior Cloning. However, direct deployments of these polici... es have led to unsatisfactory performance, where the policy struggles with unseen states and tasks. We propose FLaRe, a large-scale Reinforcement Learning fine-tuning framework that integrates robust pre-trained representations, large-scale training, and gradient stabilization techniques. Our method aligns pre-trained policies towards task completion, achieving state-of-the-art performance both on previously demonstrated and entirely novel tasks and embodiments. Specifically, on a set of long-horizon mobile manipulation tasks, FLaRe achieves an average success rate of 79.5% in unseen environments, with absolute improvements of +23.6% in simulation and +30.7% on real robots over prior state-of-the-art methods. By utilizing only sparse rewards, our approach enables generalization to new capabilities beyond the pretraining data with minimal human effort. Moreover, we demonstrate rapid adaptation to new embodiments and behaviors with less than a day of fine-tuning.
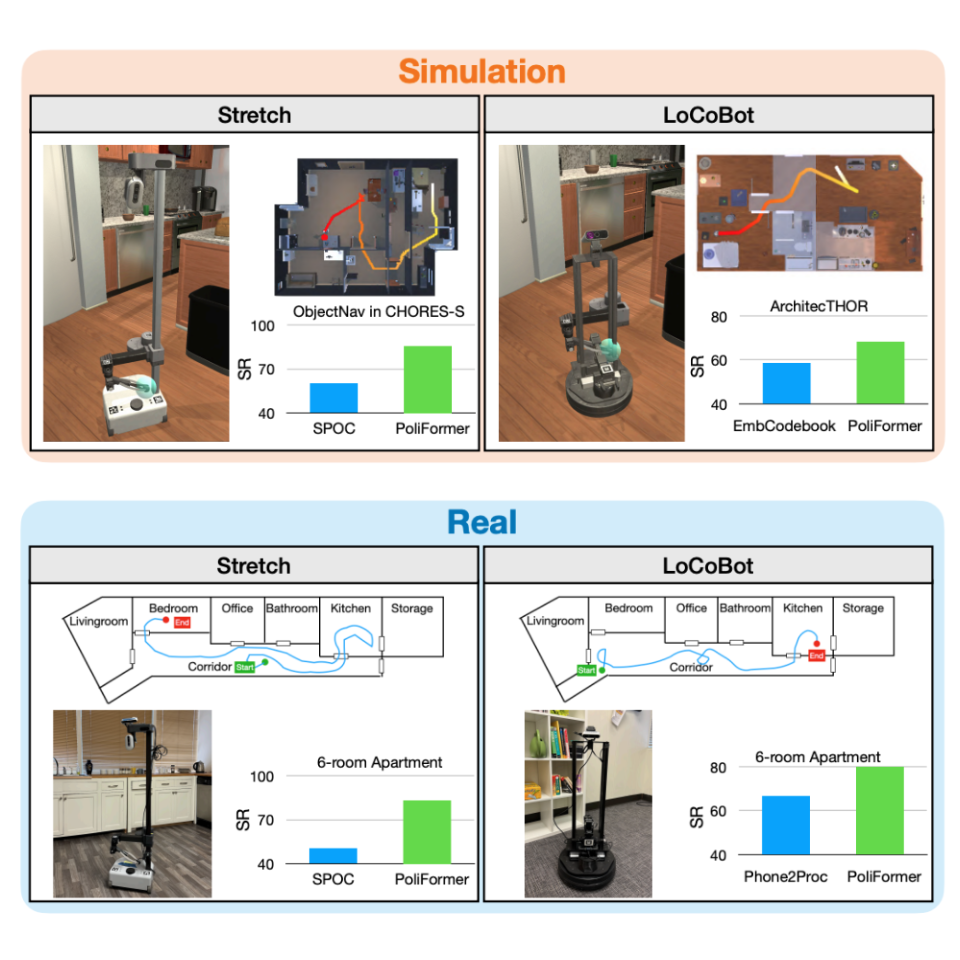
We present PoliFormer (Policy Transformer), an RGB-only indoor navigation agent trained end-to-end with reinforcement learning at scale that generalizes to the real world without adaptation despite be... ing trained purely in simulation. PoliFormer uses a foundational vision transformer encoder with a causal transformer decoder enabling long-term memory and reasoning. It is trained for hundreds of millions of interactions across diverse environments, leveraging parallelized, multi-machine rollouts for efficient training with high throughput. PoliFormer is a masterful navigator, producing state-of-the-art results across two distinct embodiments, the LoCoBot and Stretch RE-1 robots, and four navigation benchmarks. It breaks through the plateaus of previous work, achieving an unprecedented 85.5% success rate in object goal navigation on the CHORES-S benchmark, a 28.5% absolute improvement. PoliFormer can also be trivially extended to a variety of downstream applications such as object tracking, multi-object navigation, and open-vocabulary navigation with no finetuning.
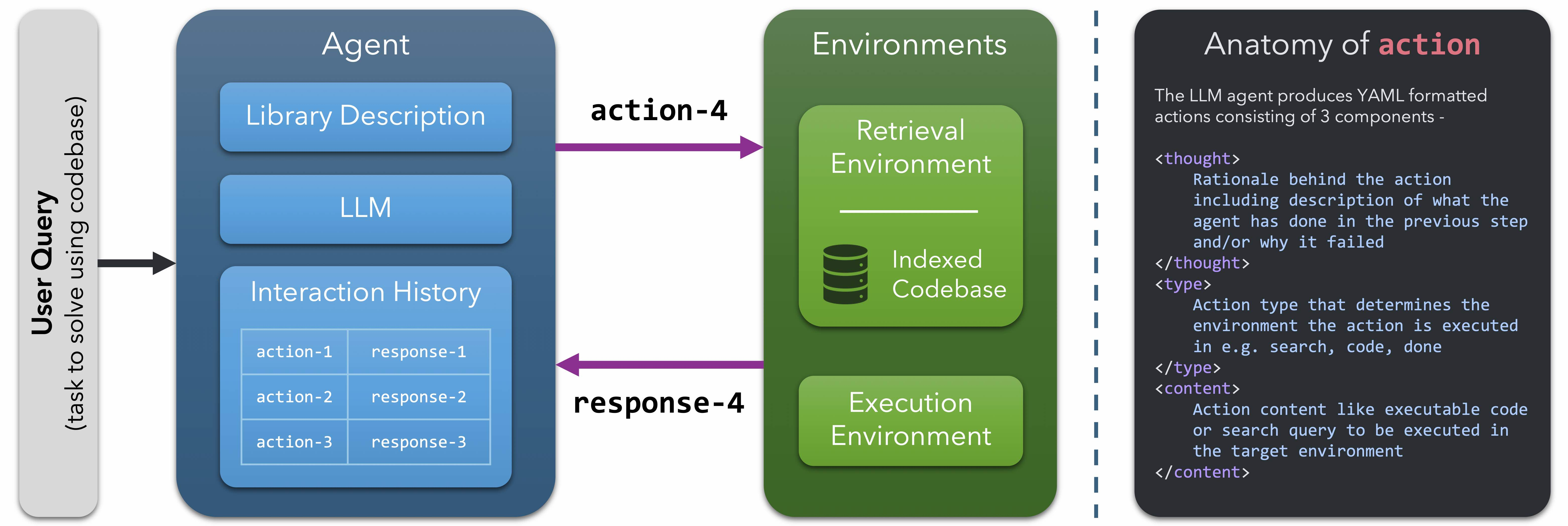
We present CodeNav, an LLM agent that navigates and leverages previously unseen code repositories to solve user queries. In contrast to tool-use LLM agents that require "registration" of all relevant... tools via manual descriptions within the LLM context, CodeNav automatically indexes and searches over code blocks in the target codebase, finds relevant code snippets, imports them, and uses them to iteratively generate a solution with execution feedback. To highlight the core capabilities of CodeNav, we first showcase three case studies where we use CodeNav for solving complex user queries using three diverse codebases. Next, on three benchmarks, we quantitatively compare the effectiveness of code-use (which only has access to the target codebase) to tool-use (which has privileged access to all tool names and descriptions). Finally, we study the effect of varying kinds of tool and library descriptions on code-use performance, as well as investigate the advantage of the agent seeing source code as opposed to natural descriptions of code. All code will be made open source under a permissive license.
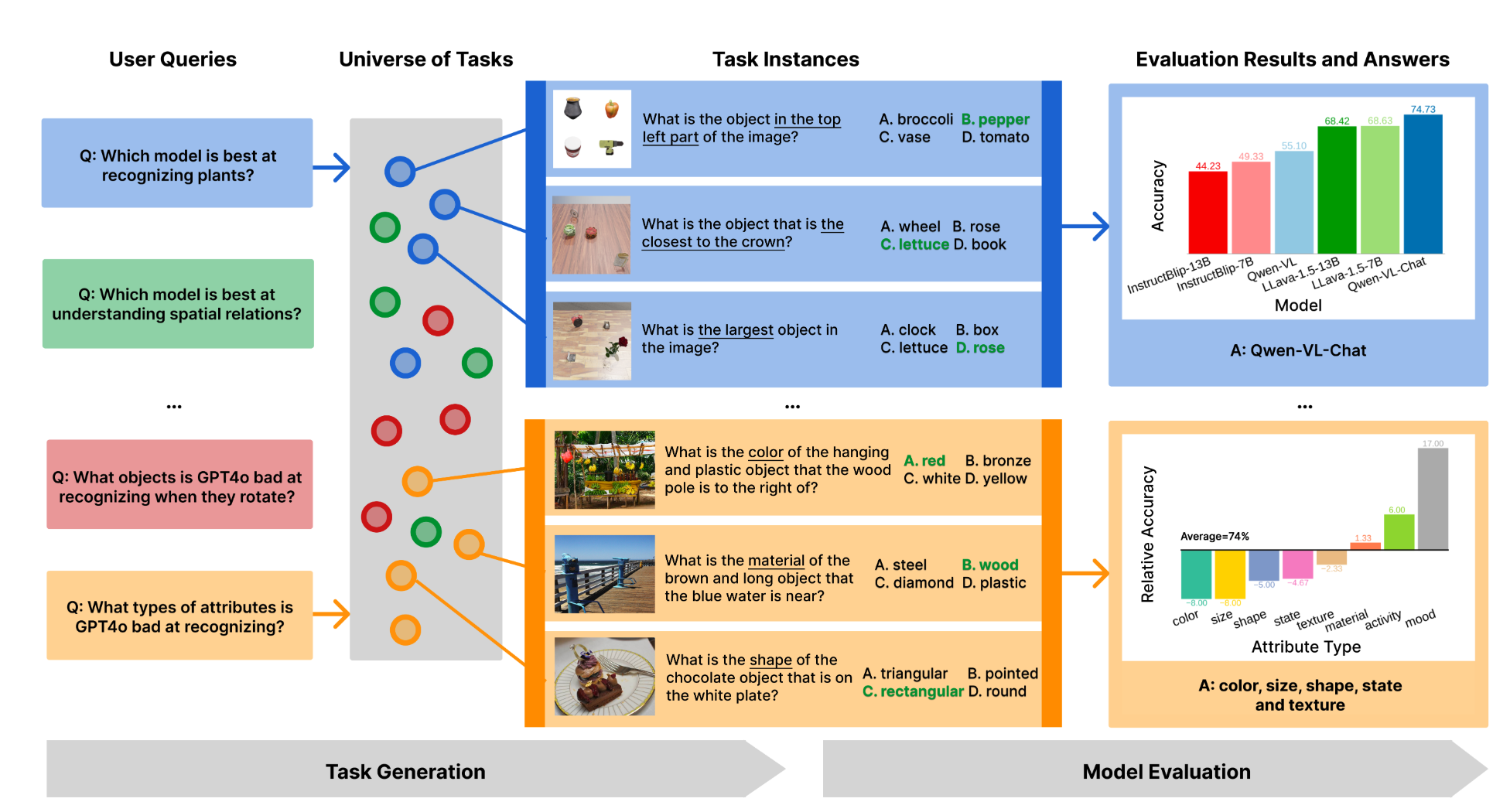
Task-Me-Anything introduces a benchmark generation engine tailored to evaluate large multimodal language models (MLMs) based on user-specific needs. Unlike traditional static benchmarks, this system d... ynamically constructs benchmarks by leveraging an extensible taxonomy of visual assets, including 113K images, 10K videos, 2K 3D object assets, over 365 object categories, 655 attributes, and 335 relationships. This enables the generation of approximately 750 million image/video question-answering pairs focused on assessing MLMs' perceptual capabilities. The framework allows users to specify computational budgets and query for tasks that closely resemble their applications. It includes programmatic task generators and algorithms to approximate model performance efficiently without exhaustive evaluations. An interactive graphical user interface facilitates user interaction, offering insights into model performance across various tasks, highlighting surprising model behaviors, and supporting query-centric investigations. Evaluations reveal that open-source MLMs excel in object and attribute recognition but face challenges in spatial and temporal understanding. Individual models exhibit unique strengths and weaknesses, with larger models generally performing better, though exceptions exist. Notably, GPT-4o demonstrates difficulties in recognizing rotating/moving objects and distinguishing colors. Task-Me-Anything's flexible and comprehensive approach provides a valuable tool for developers to assess and select MLMs aligned with their specific requirements.
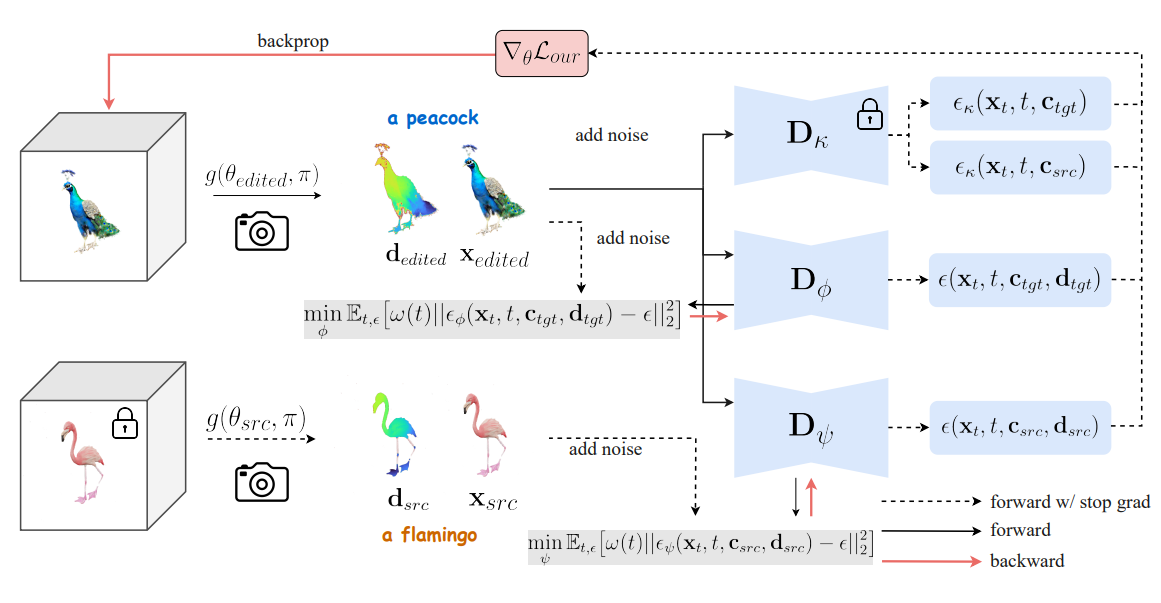
We present Piva (Preserving Identity with Variational Score Distillation), a novel optimization-based method for editing images and 3D models using diffusion models. Inspired by the Delta Denoising... Score (DDS) method for 2D image editing, we identify its limitations in both 2D and 3D contexts, such as detail loss and over-saturation. To address these issues, we introduce an additional score distillation term that enforces identity preservation, resulting in a more stable editing process. Our approach gradually optimizes Neural Radiance Field (NeRF) models to match target prompts while retaining crucial input characteristics. We demonstrate the effectiveness of our method in zero-shot image and neural field editing, successfully altering visual attributes, adding structural elements, translating shapes, and achieving competitive results on standard 2D and 3D editing benchmarks. Notably, our method imposes no constraints like masking or pre-training, making it compatible with a wide range of pre-trained diffusion models and offering a versatile, user-friendly editing experience.
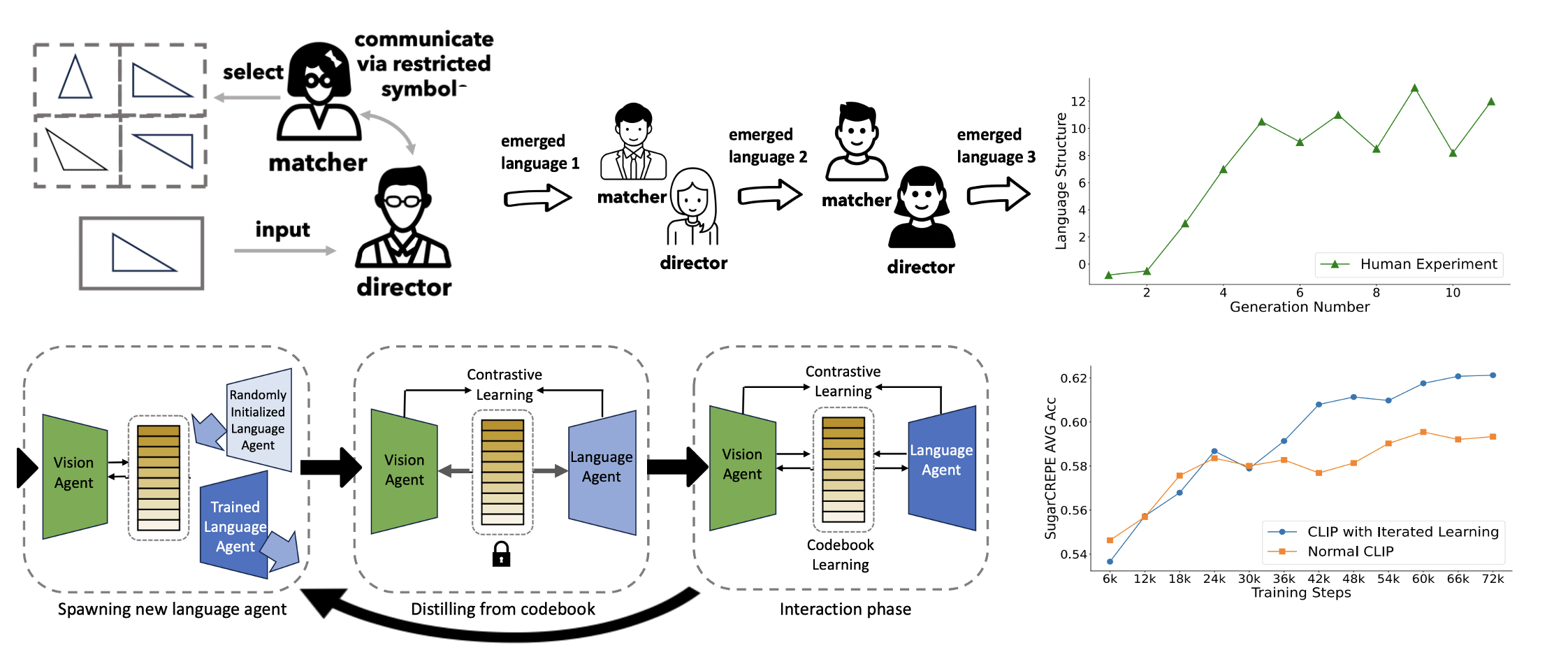
A fundamental characteristic common to both human vision and natural language is their compositional nature. Despite performance gains from large-scale pretraining, state-of-the-art vision-language... models often struggle with compositionality, failing to distinguish between images with subtle differences in arrangement or attributes. Prior work suggests that compositionality doesn't naturally arise with increased model size or training data. This paper introduces a new iterated training algorithm inspired by cognitive science research on cultural transmission—the process of teaching a new generation—which incentivizes the development of compositional languages. By reframing vision-language contrastive learning as the Lewis Signaling Game between a vision agent and a language agent, and operationalizing cultural transmission by iteratively resetting one of the agent's weights during training, our approach induces representations that become "easier to learn," a property of compositional languages. Our model, trained on CC3M and CC12M datasets, improves standard CLIP performance by 4.7% and 4.0%, respectively, on the SugarCrepe benchmark.
Traditional computer vision tasks focus on identifying visible elements within an image. This work introduces the task of Semantic Placement (SP), which involves predicting plausible locations for obj... ects that are not present in the image, based on visual context. For instance, given a living room image and the object "cushion," the model predicts where a cushion would likely be placed, such as on a sofa. To tackle this, the authors developed an automated pipeline that removes objects from images via inpainting, creating paired datasets of images with and without specific objects. This approach resulted in a dataset of approximately 1.3 million images across nine object categories. They trained a model named CLIP-UNet on this dataset, which outperformed existing vision-language models and semantic priors in predicting SP masks. User studies showed that CLIP-UNet's predictions were preferred over baselines in both real and simulated environments. The study demonstrates the potential of SP predictions in applications like assistive robotics and augmented reality, enabling systems to reason about object placement in human-centric environments.
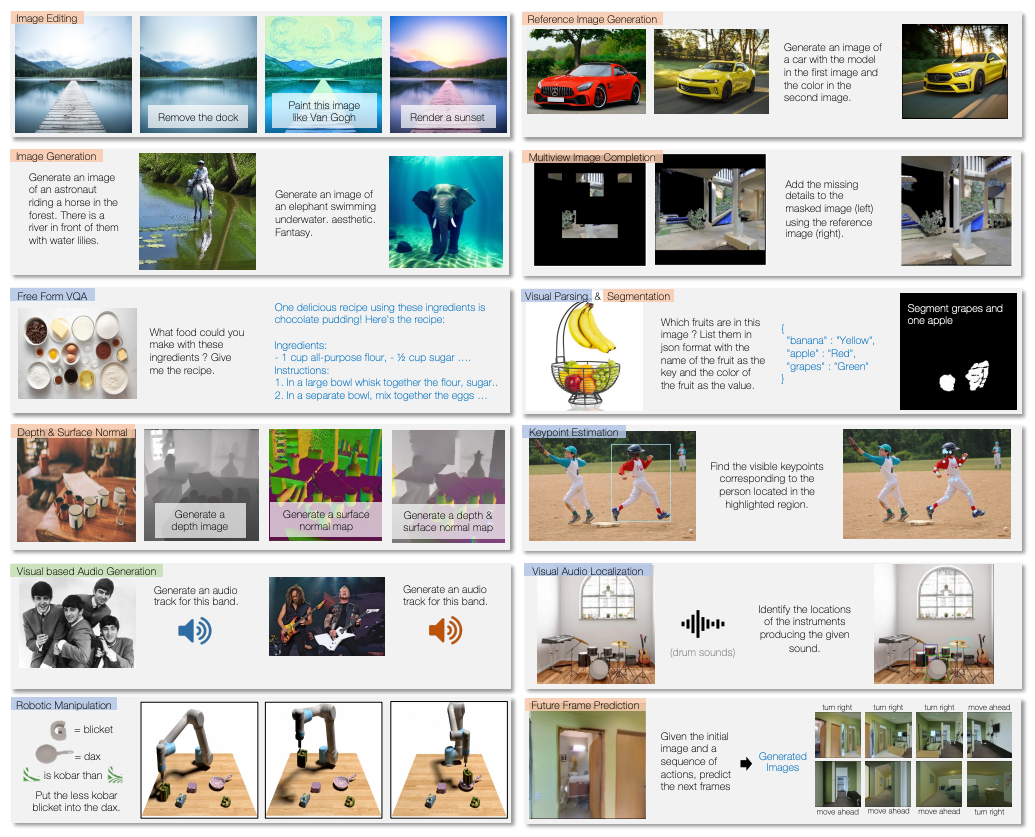
Unified-IO 2 is an autoregressive multimodal model capable of understanding and generating across various modalities, including images, text, audio, and actions. By tokenizing different inputs and out... puts into a shared semantic space, the model processes them using a single encoder-decoder transformer architecture. The model was trained from scratch on a large, diverse multimodal corpus, employing a multimodal mixture of denoisers objective to handle the complexity of varied data types. To enhance its capabilities, Unified-IO 2 was fine-tuned on 120 datasets with prompts and augmentations, enabling it to learn a wide array of skills such as multimodal instruction following. Unified-IO 2 achieves state-of-the-art performance on the GRIT benchmark and demonstrates strong results across more than 35 benchmarks, encompassing tasks in image and text understanding, video and audio processing, and robotic manipulation. The model and its resources have been made publicly available to support further research.
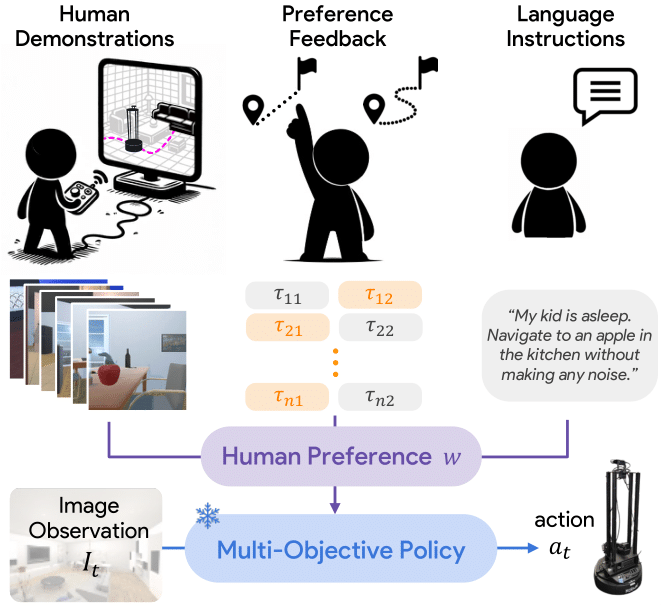
Customizing robotic behaviors to align with diverse human preferences is an underexplored challenge in embodied AI. In this paper, we present Promptable Behaviors, a novel framework that facilitates e... fficient personalization of robotic agents to diverse human preferences in complex environments. We employ multi-objective reinforcement learning to train a single policy adaptable to a broad spectrum of preferences. To infer human preferences, we introduce three distinct methods leveraging different types of interactions: (1) human demonstrations, (2) preference feedback on trajectory comparisons, and (3) language instructions. We evaluate the proposed method in personalized object-goal navigation and flee navigation tasks within ProcTHOR and RoboTHOR environments. Our results demonstrate the ability to prompt agent behaviors to satisfy human preferences in various scenarios.

3D simulated environments play a critical role in Embodied AI, but their creation requires expertise and extensive manual effort, restricting their diversity and scope. To mitigate this limitation, we... present Holodeck, a system that generates 3D environments to match a user-supplied prompt fully automatedly. Holodeck can generate diverse scenes, e.g., arcades, spas, and museums, adjust the designs for styles, and can capture the semantics of complex queries such as apartment for a researcher with a cat and office of a professor who is a fan of Star Wars. Holodeck leverages a large language model (i.e., GPT-4) for common sense knowledge about what the scene might look like and uses a large collection of 3D assets from Objaverse to populate the scene with diverse objects. To address the challenge of positioning objects correctly, we prompt GPT-4 to generate spatial relational constraints between objects and then optimize the layout to satisfy those constraints. Our large-scale human evaluation shows that annotators prefer Holodeck over manually designed procedural baselines in residential scenes and that Holodeck can produce high-quality outputs for diverse scene types. We also demonstrate an exciting application of Holodeck in Embodied AI, training agents to navigate in novel scenes like music rooms and daycares without human-constructed data, which is a significant step forward in developing general-purpose embodied agents.
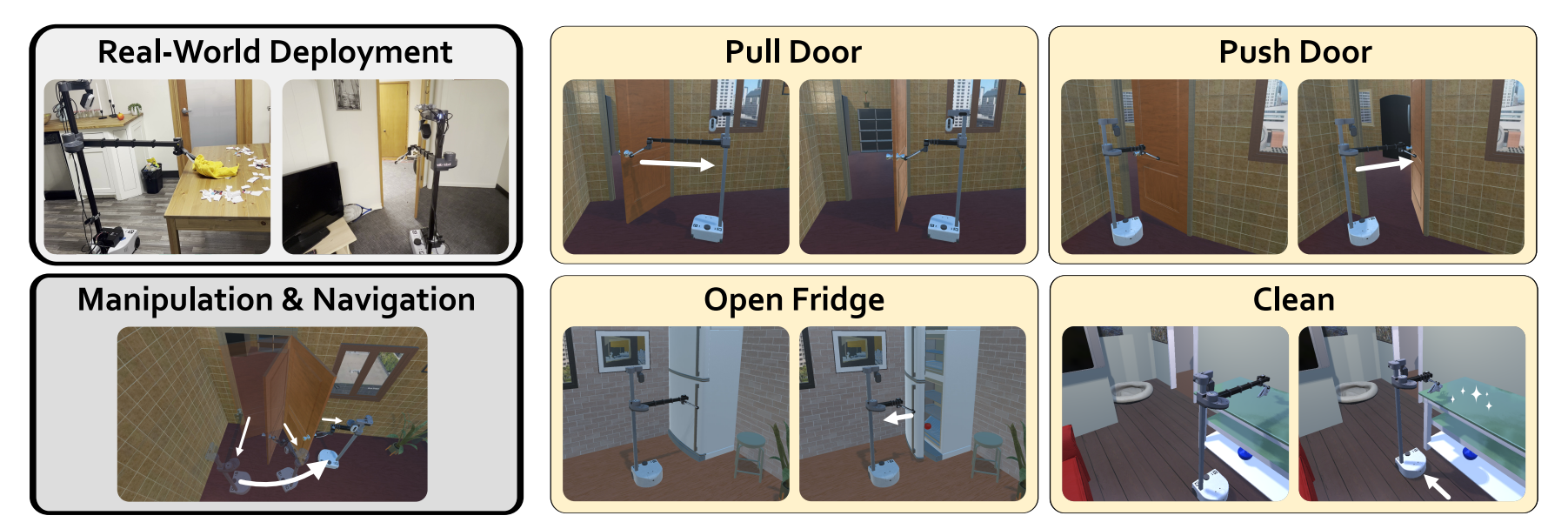
Recent advancements in robotics have enabled robots to navigate complex scenes or manipulate diverse objects independently. However, robots often struggle with household tasks requiring coordinated be... haviors, such as opening doors. Traditional approaches that separate navigation and manipulation are insufficient for tasks demanding simultaneous actions. To address this, we introduce HarmonicMM, an end-to-end learning method that jointly optimizes navigation and manipulation. Trained in procedurally generated simulated environments, HarmonicMM demonstrates notable improvements over existing techniques in everyday tasks and successfully transfers to real-world settings without additional tuning. Our contributions include a new benchmark for mobile manipulation and the successful deployment using only RGB visual observation in a real unseen apartment, highlighting the potential for practical indoor robot deployment in daily life.

Reinforcement learning (RL) with dense rewards and imitation learning (IL) with human-generated trajectories are the most widely used approaches for training modern embodied agents. RL requires extens... ive reward shaping and auxiliary losses and is often too slow and ineffective for long-horizon tasks. While IL with human supervision is effective, collecting human trajectories at scale is extremely expensive. In this work, we show that imitating shortest-path planners in simulation produces agents that, given a language instruction, can proficiently navigate, explore, and manipulate objects in both simulation and in the real world using only RGB sensors (no depth map or GPS coordinates). This surprising result is enabled by our end-to-end, transformer-based, SPOC architecture, powerful visual encoders paired with extensive image augmentation, and the dramatic scale and diversity of our training data: millions of frames of shortest-path-expert trajectories collected inside approximately 200,000 procedurally generated houses containing 40,000 unique 3D assets. Our models, data, training code, and newly proposed 10-task benchmarking suite CHORES are available in https://spoc-robot.github.io.
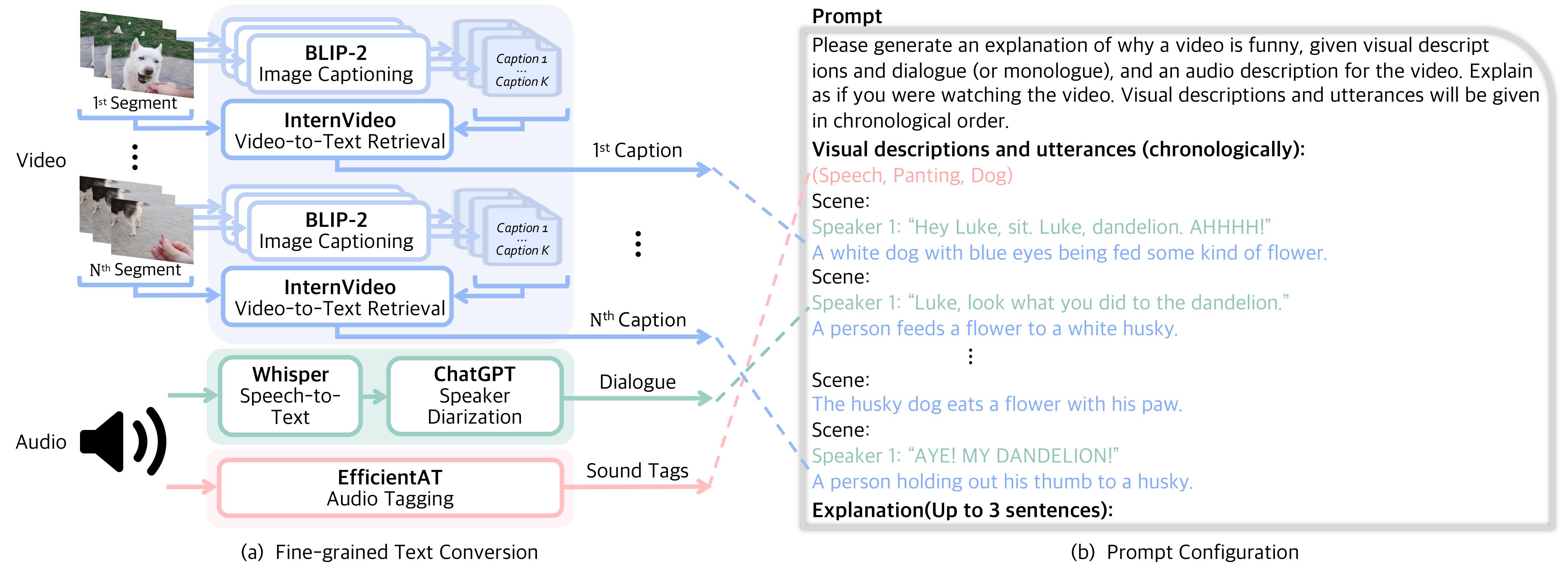
As short-form funny videos on social networks are gaining popularity, it becomes demanding for AI models to understand them for better communication with humans. Unfortunately, previous video humor da... tasets target specific domains, such as speeches or sitcoms, and mostly focus on verbal cues. We curate a user-generated dataset of 10K multimodal funny videos from YouTube, called ExFunTube. Using a video filtering pipeline with GPT-3.5, we verify both verbal and visual elements contributing to humor. After filtering, we annotate each video with timestamps and text explanations for funny moments. Our ExFunTube is unique over existing datasets in that our videos cover a wide range of domains with various types of humor that necessitate a multimodal understanding of the content. Also, we develop a zero-shot video-to-text prompting to maximize video humor understanding of large language models (LLMs). With three different evaluation methods using automatic scores, rationale quality experiments, and human evaluations, we show that our prompting significantly improves LLMs' ability for humor explanation.
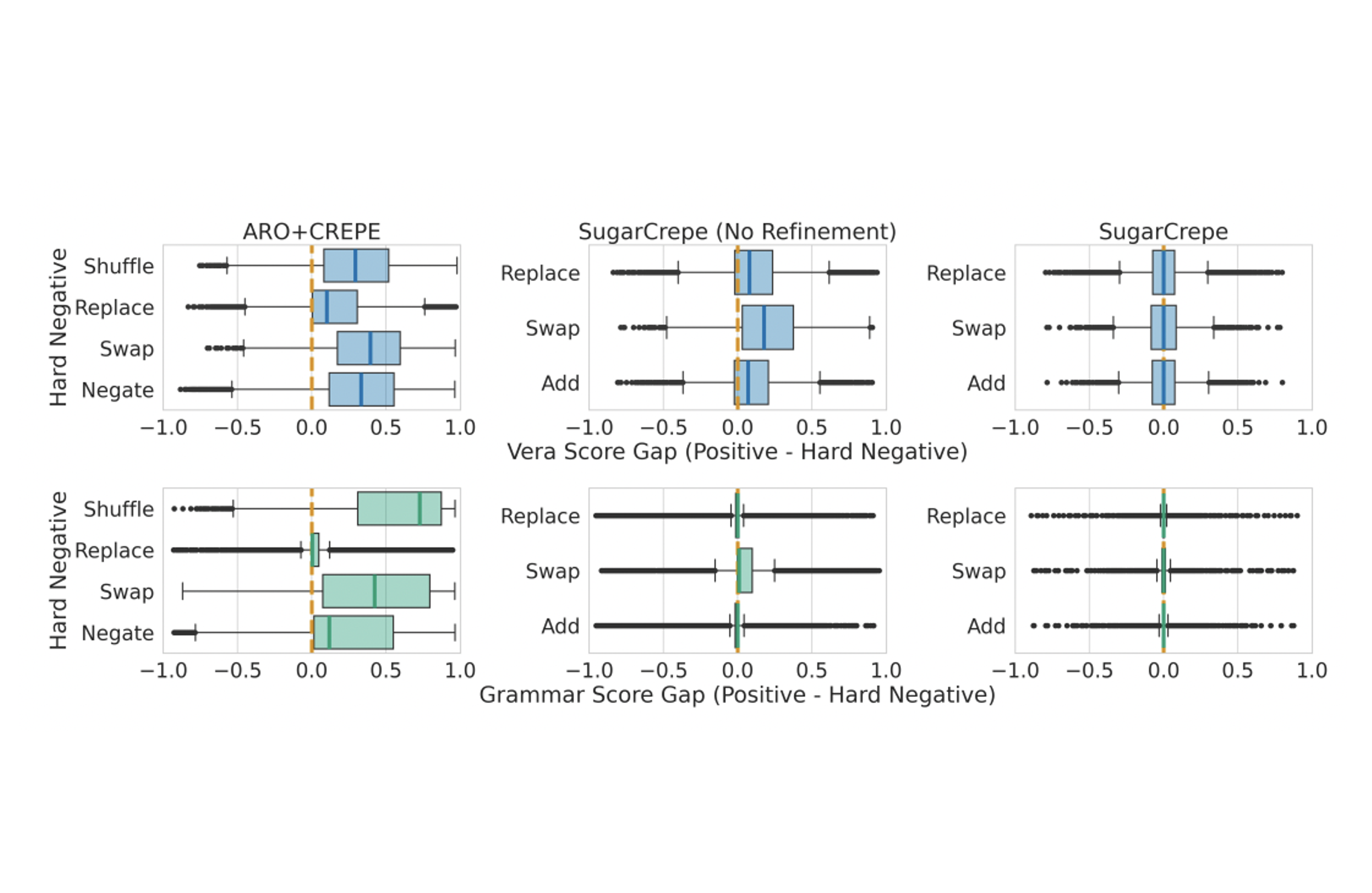
In recent years, a surge of new benchmarks to measure compositional understanding of vision-language models has permeated the machine learning ecosystem. Given an image, these benchmarks probe a model... 's ability to identify its associated caption amongst a set of compositional distractors. Surprisingly, we find significant biases in all these benchmarks, rendering them hackable. This hackability is so dire that blind models with no access to the image outperform state-of-the-art vision-language models. To remedy this rampant vulnerability, we introduce SugarCrepe, a new benchmark for vision-language compositionality evaluation. We employ large language models, instead of rule-based templates used in previous benchmarks, to generate fluent and sensical hard negatives, and utilize an adversarial refinement mechanism to maximally reduce biases. We re-evaluate state-of-the-art models and recently proposed compositionality-inducing strategies, and find that their improvements were hugely overestimated, suggesting that more innovation is needed in this important direction.

Natural language processing and 2D vision models have attained remarkable proficiency on many tasks primarily by escalating the scale of training data. However, 3D vision tasks have not seen the same... progress, in part due to the challenges of acquiring high-quality 3D data. In this work, we present Objaverse-XL, a dataset of over 10 million 3D objects. Our dataset comprises deduplicated 3D objects from a diverse set of sources, including manually designed objects, photogrammetry scans of landmarks and everyday items, and professional scans of historic and antique artifacts. Representing the largest scale and diversity in the realm of 3D datasets, Objaverse-XL enables significant new possibilities for 3D vision. Our experiments demonstrate the improvements enabled with the scale provided by Objaverse-XL. We show that by training Zero123 on novel view synthesis, utilizing over 100 million multi-view rendered images, we achieve strong zero-shot generalization abilities. We hope that releasing Objaverse-XL will enable further innovations in the field of 3D vision at scale.

Existing image editing tools, while powerful, typically disregard the underlying 3D geometry from which the image is projected. As a result, edits made using these tools may become detached from the g... eometry and lighting conditions that are at the foundation of the image formation process. In this work, we formulate the newt ask of language-guided 3D-aware editing, where objects in an image should be edited according to a language instruction in context of the underlying 3D scene. To promote progress towards this goal, we release OBJECT: a dataset consisting of 400K editing examples created from procedurally generated 3D scenes. Each example consists of an input image, editing instruction in language, and the edited image. We also introduce 3DIT : single and multi-task models for four editing tasks. Our models show impressive abilities to understand the 3D composition of entire scenes, factoring in surrounding objects, surfaces, lighting conditions, shadows, and physically-plausible object configurations. Surprisingly, training on only synthetic scenes from OBJECT, editing capabilities of 3DIT generalize to real-world images.

Remote sensing images are useful for a wide variety of planet monitoring applications, from tracking deforestation to tackling illegal fishing. The Earth is extremely diverse -- the amount of potentia... l tasks in remote sensing images is massive, and the sizes of features range from several kilometers to just tens of centimeters. However, creating generalizable computer vision methods is a challenge in part due to the lack of a large-scale dataset that captures these diverse features for many tasks. In this paper, we present SatlasPretrain, a remote sensing dataset that is large in both breadth and scale, combining Sentinel-2 and NAIP images with 302M labels under 137 categories and seven label types. We evaluate eight baselines and a proposed method on SatlasPretrain, and find that there is substantial room for improvement in addressing research challenges specific to remote sensing, including processing image time series that consist of images from very different types of sensors, and taking advantage of long-range spatial context. Moreover, we find that pre-training on SatlasPretrain substantially improves performance on downstream tasks, increasing average accuracy by 18% over ImageNet and 6% over the next best baseline. The dataset, pre-trained model weights, and code are available at https://satlas-pretrain.allen.ai/.

We present VISPROG, a neuro-symbolic approach to solving complex and compositional visual tasks given natural language instructions. VISPROG avoids the need for any task-specific training. Instead, it... uses the in-context learning ability of large language models to generate python-like modular programs, which are then executed to get both the solution and a comprehensive and interpretable rationale. Each line of the generated program may invoke one of several off-the-shelf computer vision models, image processing routines, or python functions to produce intermediate outputs that may be consumed by subsequent parts of the program. We demonstrate the flexibility of VISPROG on 4 diverse tasks - compositional visual question answering, zero-shot reasoning on image pairs, factual knowledge object tagging, and language-guided image editing. We believe neuro-symbolic approaches like VISPROG are an exciting avenue to easily and effectively expand the scope of AI systems to serve the long tail of complex tasks that people may wish to perform.

Massive data corpora like WebText, Wikipedia, Conceptual Captions, WebImageText, and LAION have propelled recent dramatic progress in AI. Large neural models trained on such datasets produce impressiv... e results and top many of today's benchmarks. A notable omission within this family of large-scale datasets is 3D data. Despite considerable interest and potential applications in 3D vision, datasets of high-fidelity 3D models continue to be mid-sized with limited diversity of object categories. Addressing this gap, we present Objaverse 1.0, a large dataset of objects with 800K+ (and growing) 3D models with descriptive captions, tags, and animations. Objaverse improves upon present day 3D repositories in terms of scale, number of categories, and in the visual diversity of instances within a category. We demonstrate the large potential of Objaverse via four diverse applications: training generative 3D models, improving tail category segmentation on the LVIS benchmark, training open-vocabulary object-navigation models for Embodied AI, and creating a new benchmark for robustness analysis of vision models. Objaverse can open new directions for research and enable new applications across the field of AI.
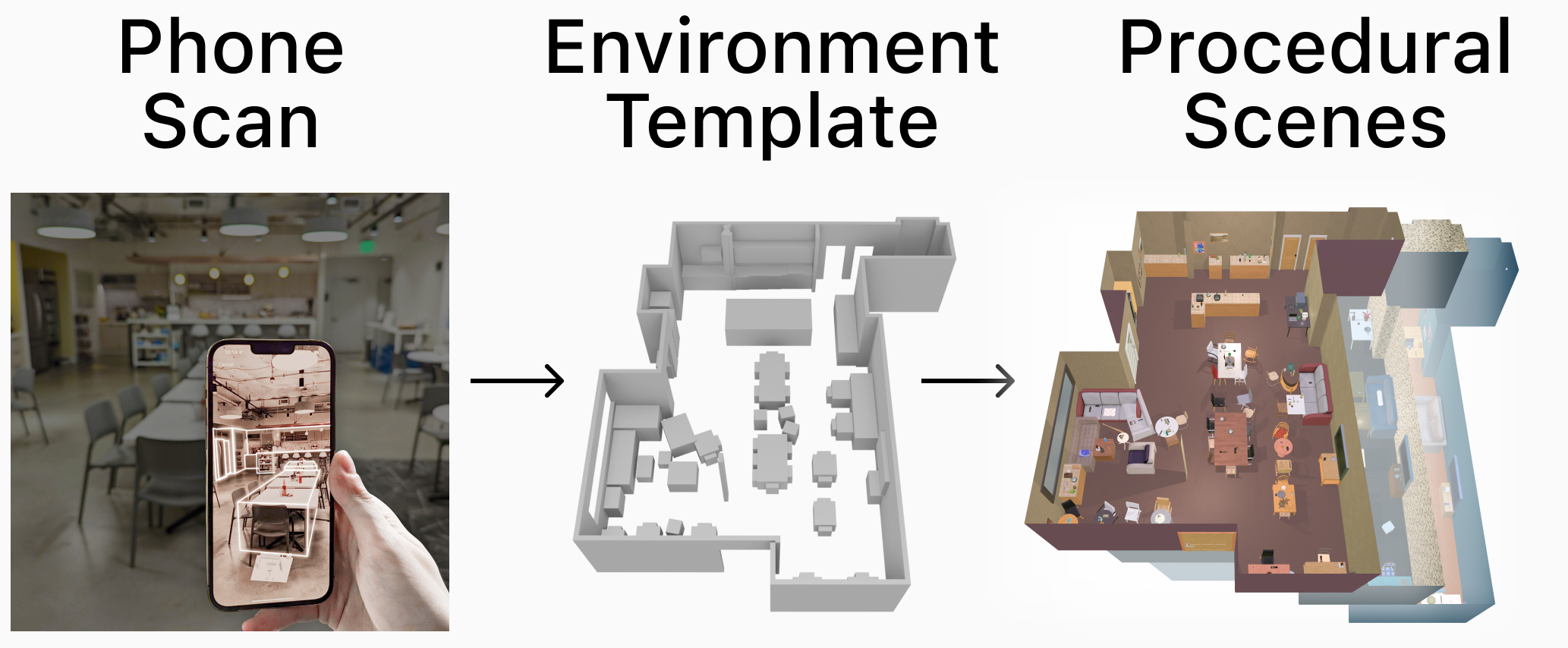
Training embodied agents in simulation has become mainstream for the embodied AI community. However, these agents often struggle when deployed in the physical world due to their inability to generaliz... e to real-world environments. In this paper, we present Phone2Proc, a method that uses a 10-minute phone scan and conditional procedural generation to create a distribution of training scenes that are semantically similar to the target environment. The generated scenes are conditioned on the wall layout and arrangement of large objects from the scan, while also sampling lighting, clutter, surface textures, and instances of smaller objects with randomized placement and materials. Leveraging just a simple RGB camera, training with Phone2Proc shows massive improvements from 34.7% to 70.7% success rate in sim-to-real ObjectNav performance across a test suite of over 200 trials in diverse real-world environments, including homes, offices, and RoboTHOR. Furthermore, Phone2Proc's diverse distribution of generated scenes makes agents remarkably robust to changes in the real world, such as human movement, object rearrangement, lighting changes, or clutter.
An embodied agent may encounter settings that dramatically alter the impact of actions: a move ahead action on a wet floor may send the agent twice as far as it expects and using the same action with... a broken wheel might transform the expected translation into a rotation. To address this problem, we propose to model the impact of actions on-the-fly using latent embeddings. By combining these latent action embeddings with a novel, transformer-based, policy head, we design an Action Adaptive Policy (AAP).
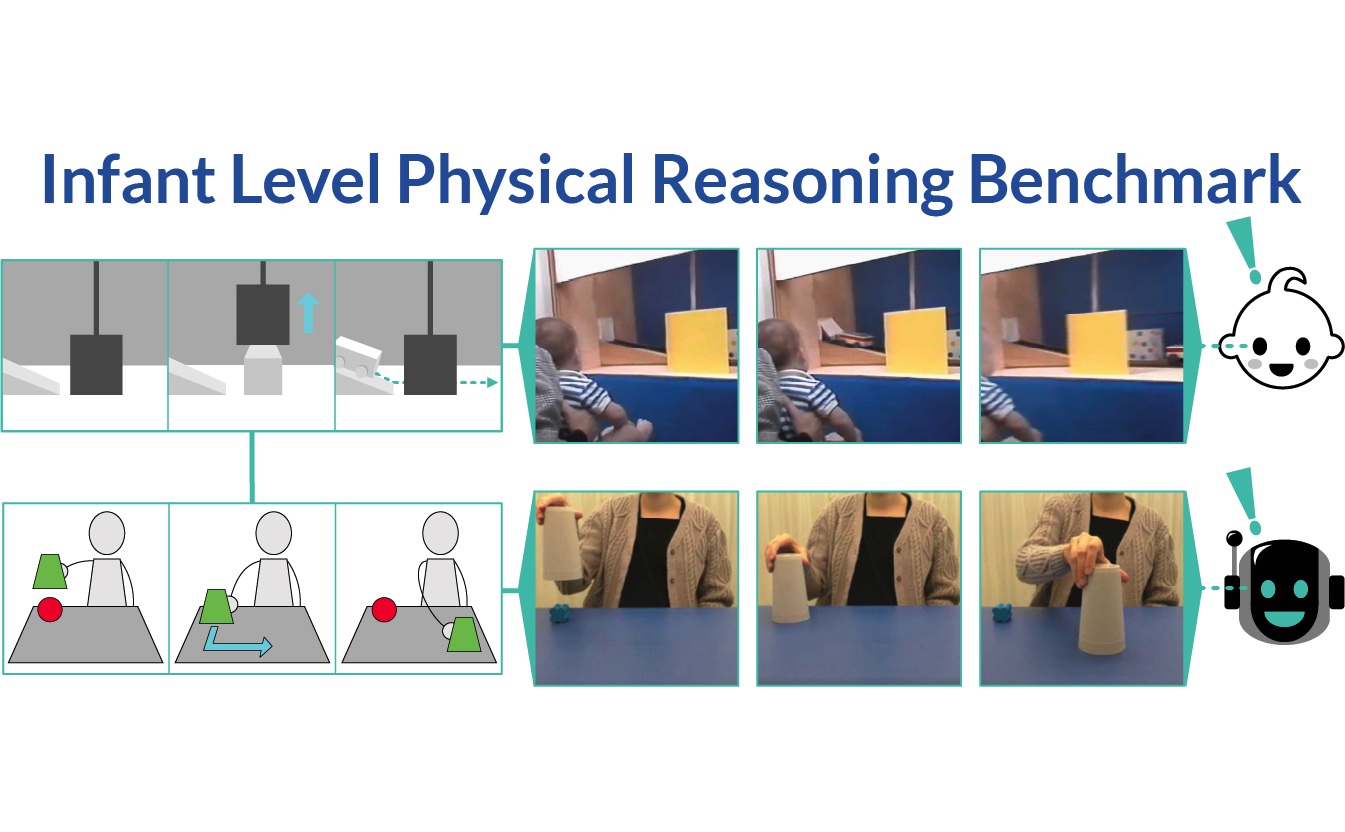
To what extent do modern AI systems comprehend the physical world? We introduce the open-access Infant-Level Physical Reasoning Benchmark (InfLevel) to gain insight into this question. We evaluate ten... neural-network architectures developed for video understanding on tasks designed to test these models' ability to reason about three essential physical principles which researchers have shown to guide human infants' physical understanding. We explore the sensitivity of each AI system to the continuity of objects as they travel through space and time, to the solidity of objects, and to gravity. We find strikingly consistent results across 60 experiments with multiple systems, training regimes, and evaluation metrics: current popular visual-understanding systems are at or near chance on all three principles of physical reasoning. We close by suggesting some potential ways forward.
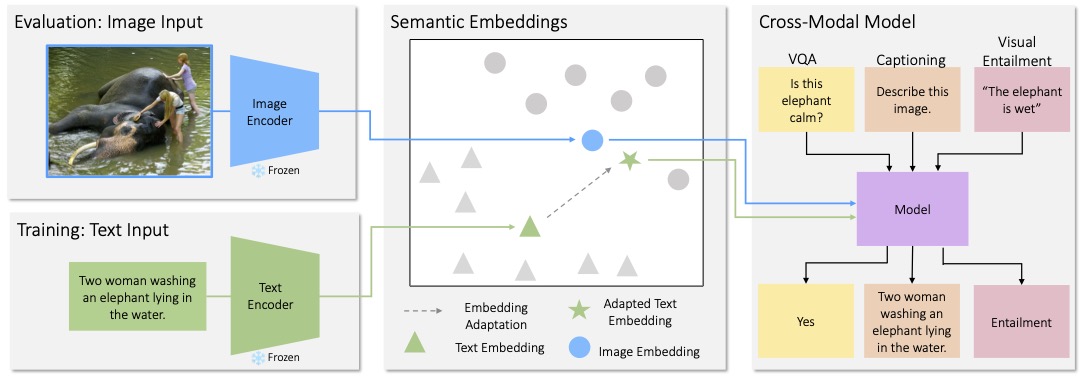
Many high-level skills that are required for computer vision tasks, such as parsing questions, comparing and contrasting semantics, and writing descriptions, are also required in other domains such as... natural language processing. In this paper, we ask whether this makes it possible to learn those skills from text data and then use them to complete vision tasks without ever training on visual training data. Key to our approach is exploiting the joint embedding space of contrastively trained vision and language encoders. In practice, there can be systematic differences between embedding spaces for different modalities in contrastive models, and we analyze how these differences affect our approach and study a variety of strategies to mitigate this concern. We produce models using only text training data on three tasks: image captioning, visual entailment and visual question answering, and evaluate them on standard benchmarks using images. We find that this kind of transfer is possible and results in only a small drop in performance relative to models trained on images. We also showcase a variety of stylistic image captioning models that were trained using no image data and no human-curated language data, but instead text data from books, the web, or language models.
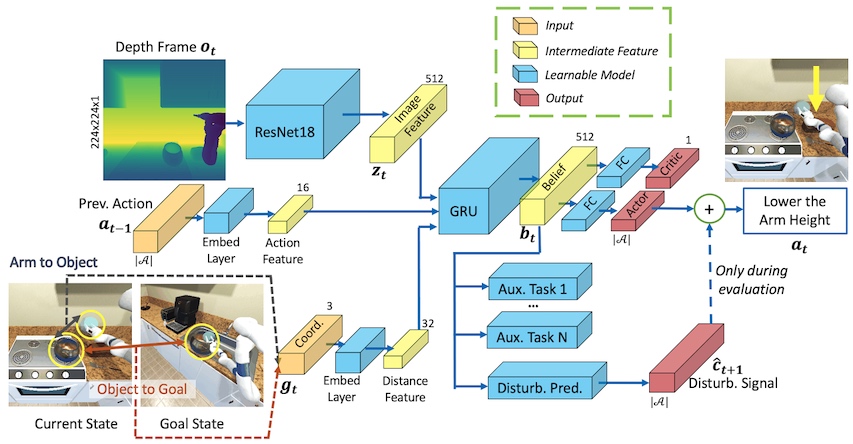
Embodied AI has shown promising results on an abundance of robotic tasks in simulation, including visual navigation and manipulation. The prior work generally pursues high success rates with shortest... paths while largely ignoring the problems caused by collision during interaction. This lack of prioritization is understandable: in simulated environments there is no inherent cost to breaking virtual objects. As a result, well-trained agents frequently have catastrophic collision with objects despite final success. In the robotics community, where the cost of collision is large, collision avoidance is a long-standing and crucial topic to ensure that robots can be safely deployed in the real world. In this work, we take the first step towards collision/disturbance-free embodied AI agents for visual mobile manipulation, facilitating safe deployment in real robots. We develop a new disturbance-avoidance methodology at the heart of which is the auxiliary task of disturbance prediction. When combined with a disturbance penalty, our auxiliary task greatly enhances sample efficiency and final performance by knowledge distillation of disturbance into the agent. Our experiments on ManipulaTHOR show that, on testing scenes with novel objects, our method improves the success rate from 61.7% to 85.6% and the success rate without disturbance from 29.8% to 50.2% over the original baseline. Extensive ablation studies show the value of our pipelined approach.

Embodied AI agents continue to become more capable every year with the advent of new models, environments, and benchmarks, but are still far away from being performant and reliable enough to be deploy... ed in real, user-facing, applications. In this paper, we ask: can we bridge this gap by enabling agents to ask for assistance from an expert such as a human being? To this end, we propose the ASK4HELP policy that augments agents with the ability to request, and then use expert assistance. Ask4Help policies can be efficiently trained without modifying the original agent parameters and learn a desirable trade-off between task performance and the amount of requested help, thereby reducing the cost of querying the expert. We evaluate ASK4HELP on two different tasks : object goal navigation and room rearrangement and see substantial improvements in performance using minimal help. On object navigation, an agent that achieves a 52% success rate is raised to 86% with 13% help and for rearrangement, the state-of-the-art model with a 7% success rate is dramatically improved to 90.4% using 39% help. Human trials with ASK4HELP demonstrate the efficacy of our approach in practical scenarios.

Massive datasets and high-capacity models have driven many recent advancements in computer vision and natural language understanding. This work presents a platform to enable similar success stories in... Embodied AI. We propose ProcTHOR, a framework for procedural generation of Embodied AI environments. ProcTHOR enables us to sample arbitrarily large datasets of diverse, interactive, customizable, and performant virtual environments to train and evaluate embodied agents across navigation, interaction, and manipulation tasks. We demonstrate the power and potential of ProcTHOR via a sample of 10,000 generated houses and a simple neural model. Models trained using only RGB images on ProcTHOR, with no explicit mapping and no human task supervision produce state-of-the-art results across 6 embodied AI benchmarks for navigation, rearrangement, and arm manipulation, including the presently running Habitat 2022, AI2-THOR Rearrangement 2022, and RoboTHOR challenges. We also demonstrate strong 0-shot results on these benchmarks, via pre-training on ProcTHOR with no fine-tuning on the downstream benchmark, often beating previous state-of-the-art systems that access the downstream training data.
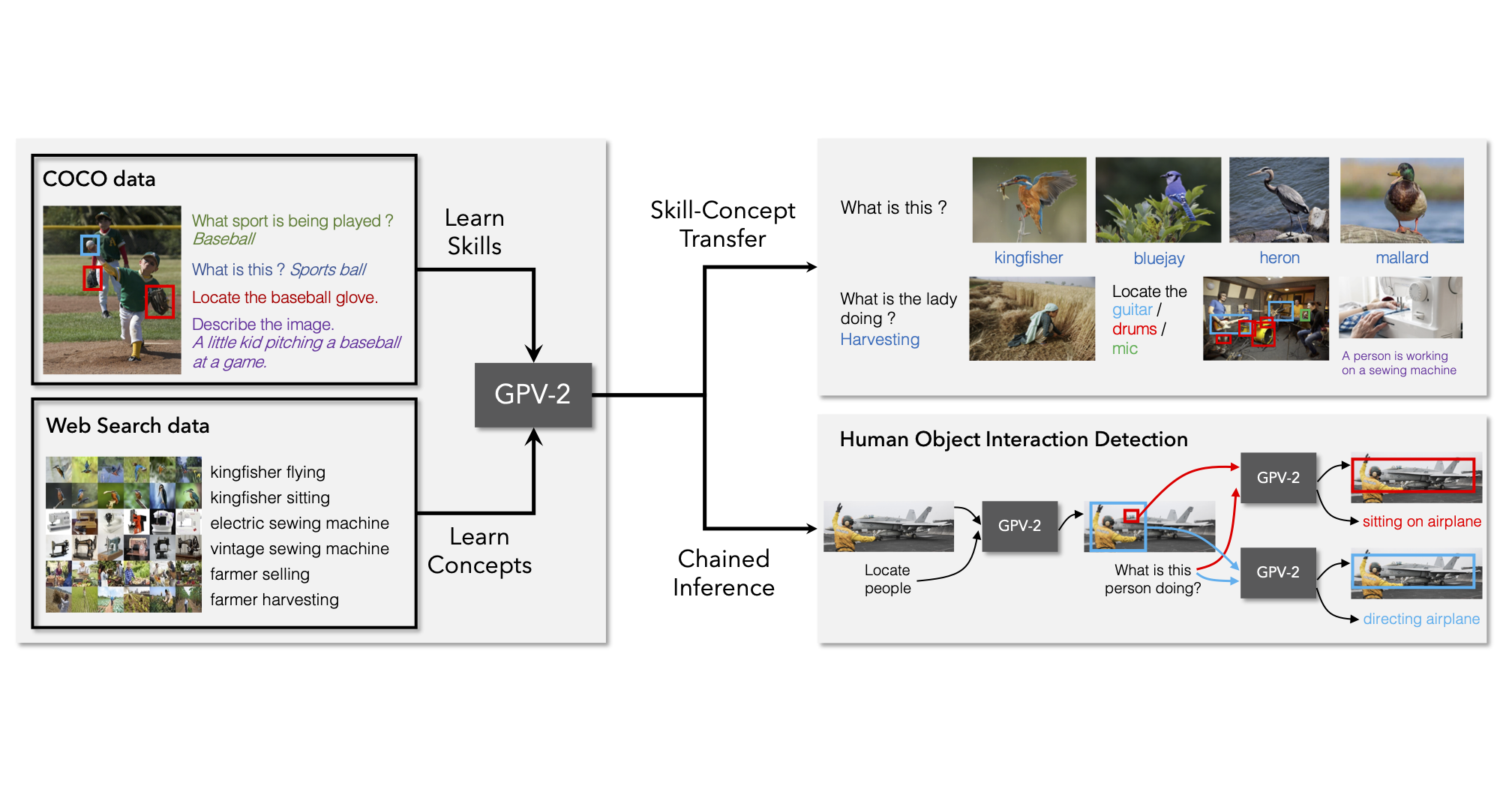
General purpose vision (GPV) systems are models that are designed to solve a wide array of visual tasks without requiring architectural changes. Today, GPVs primarily learn both skills and concepts fr... om large fully supervised datasets. Scaling GPVs to tens of thousands of concepts by acquiring data to learn each concept for every skill quickly becomes prohibitive. This work presents an effective and inexpensive alternative: learn skills from fully supervised datasets, learn concepts from web image search results, and leverage a key characteristic of GPVs -- the ability to transfer visual knowledge across skills. We use a dataset of 1M+ images spanning 10k+ visual concepts to demonstrate webly-supervised concept expansion for two existing GPVs (GPV-1 and VL-T5) on 3 benchmarks - 5 COCO based datasets (80 primary concepts), a newly curated series of 5 datasets based on the OpenImages and VisualGenome repositories (~500 concepts) and the Web-derived dataset (10k+ concepts). We also propose a new architecture, GPV-2 that supports a variety of tasks -- from vision tasks like classification and localization to vision+language tasks like QA and captioning to more niche ones like human-object interaction recognition. GPV-2 benefits hugely from web data, outperforms GPV-1 and VL-T5 across these benchmarks, and does well in a 0-shot setting at action and attribute recognition.
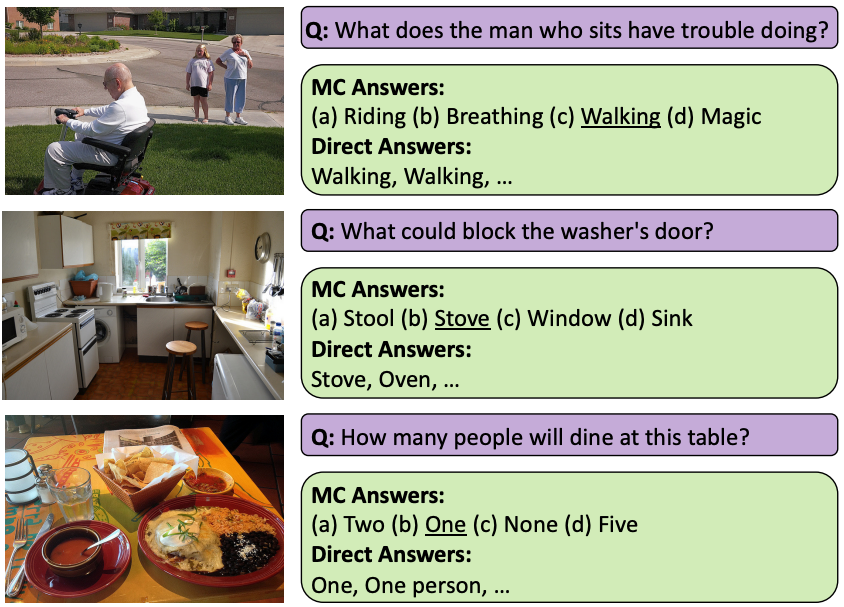
The Visual Question Answering (VQA) task aspires to provide a meaningful testbed for the development of AI models that can jointly reason over visual and natural language inputs. Despite a proliferati... on of VQA datasets, this goal is hindered by a set of common limitations. These include a reliance on relatively simplistic questions that are repetitive in both concepts and linguistic structure, little world knowledge needed outside of the paired image, and limited reasoning required to arrive at the correct answer. We introduce A-OKVQA, a crowdsourced dataset composed of a diverse set of about 25K questions requiring a broad base of commonsense and world knowledge to answer. In contrast to the existing knowledge-based VQA datasets, the questions generally cannot be answered by simply querying a knowledge base, and instead require some form of commonsense reasoning about the scene depicted in the image. We demonstrate the potential of this new dataset through a detailed analysis of its contents and baseline performance measurements over a variety of state-of-the-art vision–language models.
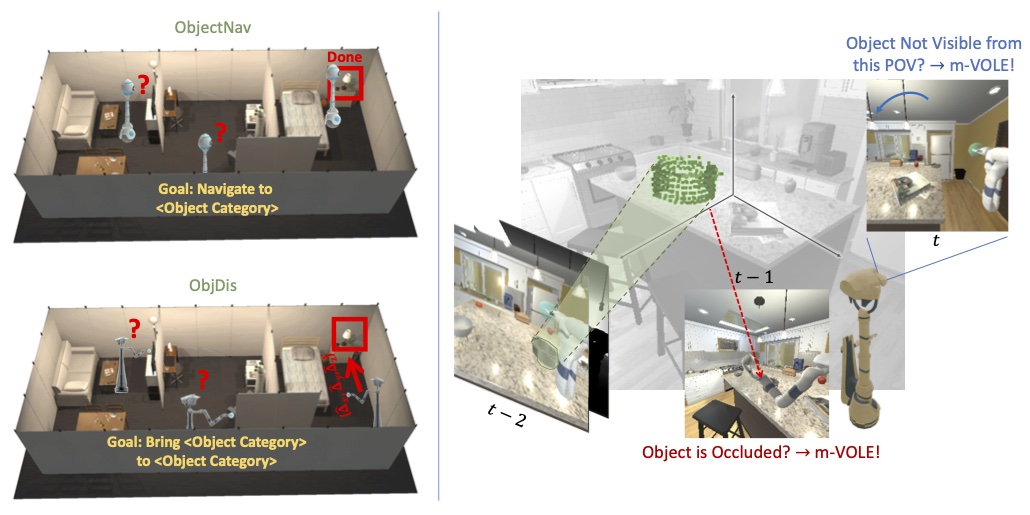
Object manipulation is a critical skill required for Embodied AI agents interacting with the world around them. Training agents to manipulate objects, poses many challenges. These include occlusion of... the target object by the agent's arm, noisy object detection and localization, and the target frequently going out of view as the agent moves around in the scene. We propose Manipulation via Visual Object Location Estimation (m-VOLE), an approach that explores the environment in search for target objects, computes their 3D coordinates once they are located, and then continues to estimate their 3D locations even when the objects are not visible, thus robustly aiding the task of manipulating these objects throughout the episode. Our evaluations show a massive 3x improvement in success rate over a model that has access to the same sensory suite but is trained without the object location estimator, and our analysis shows that our agent is robust to noise in depth perception and agent localization. Importantly, our proposed approach relaxes several assumptions about idealized localization and perception that are commonly employed by recent works in navigation and manipulation -- an important step towards training agents for object manipulation in the real world.
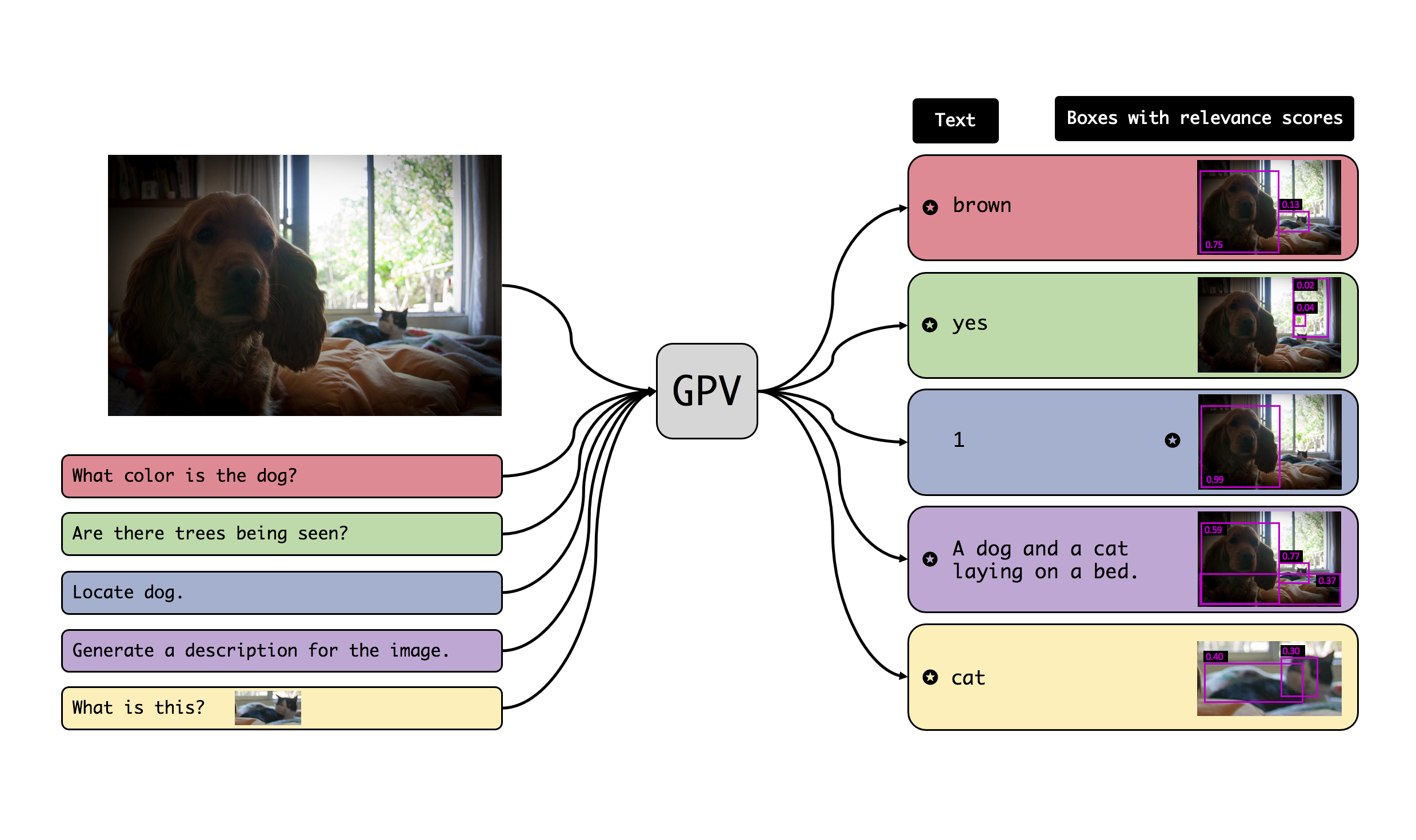
A special purpose learning system assumes knowledge of admissible tasks at design time. Adapting such a system to unforeseen tasks requires architecture manipulation such as adding an output head for... each new task or dataset. In this work, we propose a task-agnostic vision-language system that accepts an image and a natural language task description and outputs bounding boxes, confidences, and text. The system supports a wide range of vision tasks such as classification, localization, question answering, captioning, and more. We evaluate the system's ability to learn multiple skills simultaneously, to perform tasks with novel skill-concept combinations, and to learn new skills efficiently and without forgetting.
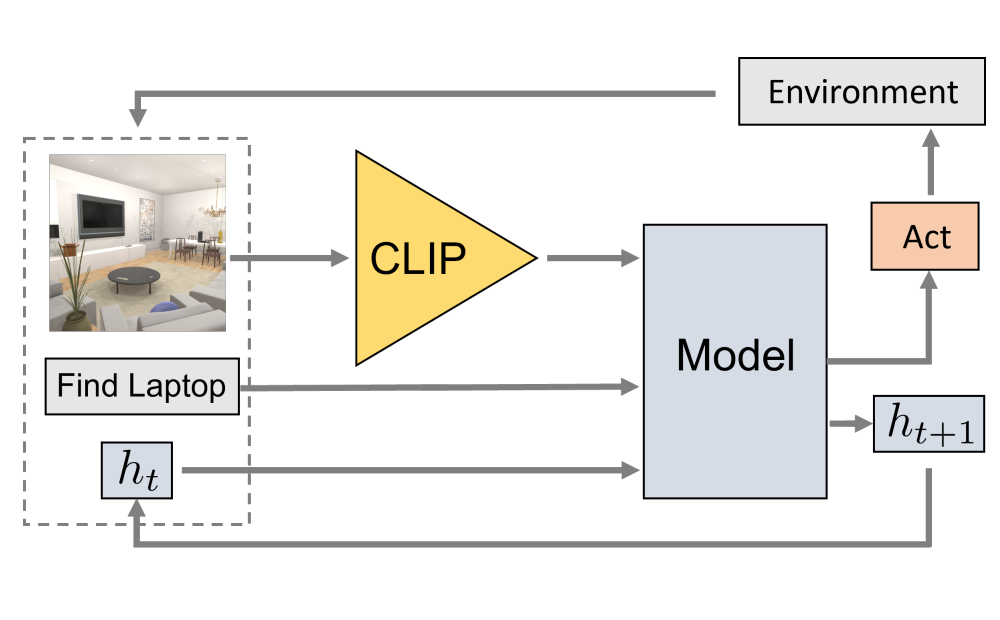
Contrastive language image pretraining (CLIP) encoders have been shown to be beneficial for a range of visual tasks from classification and detection to captioning and image manipulation. We investiga... te the effectiveness of CLIP visual backbones for Embodied AI tasks. We build incredibly simple baselines, named EmbCLIP, with no task specific architectures, inductive biases (such as the use of semantic maps), auxiliary tasks during training, or depth maps — yet we find that our improved baselines perform very well across a range of tasks and simulators. EmbCLIP tops the RoboTHOR ObjectNav leaderboard by a huge margin of 20 pts (Success Rate). It tops the iTHOR 1-Phase Rearrangement leaderboard, beating the next best submission, which employs Active Neural Mapping, and more than doubling the % Fixed Strict metric (0.08 to 0.17). It also beats the winners of the 2021 Habitat ObjectNav Challenge, which employ auxiliary tasks, depth maps, and human demonstrations, and those of the 2019 Habitat PointNav Challenge. We evaluate the ability of CLIP's visual representations at capturing semantic information about input observations — primitives that are useful for navigation-heavy embodied tasks — and find that CLIP's representations encode these primitives more effectively than ImageNet-pretrained backbones. Finally, we extend one of our baselines, producing an agent capable of zero-shot object navigation that can navigate to objects that were not used as targets during training.
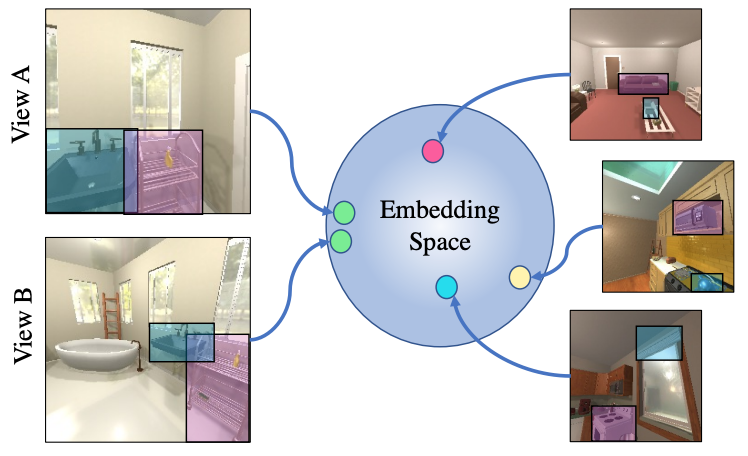
We propose Continuous Scene Representations (CSR), a scene representation constructed by an embodied agent navigating within a space, where objects and their relationships are modeled by continuous va... lued embeddings. Our method captures feature relationships between objects, composes them into a graph structure on-the-fly, and situates an embodied agent within the representation. Our key insight is to embed pair-wise relationships between objects in a latent space. This allows for a richer representation compared to discrete relations (e.g., [support], [next-to]) commonly used for building scene representations. CSR can track objects as the agent moves in a scene, update the representation accordingly, and detect changes in room configurations. Using CSR, we outperform state-of-the-art approaches for the challenging downstream task of visual room rearrangement, without any task specific training. Moreover, we show the learned embeddings capture salient spatial details of the scene and show applicability to real world data.
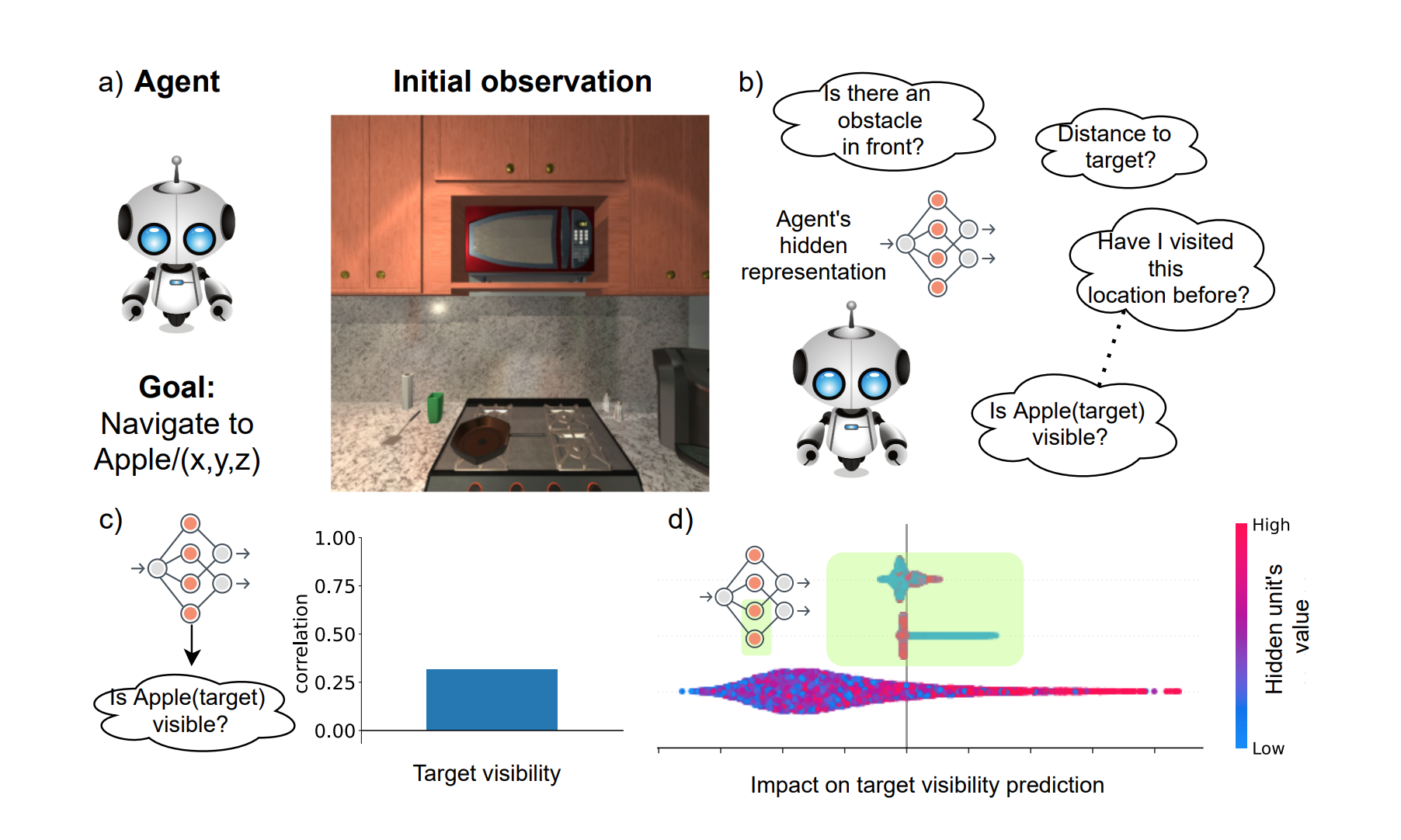
Today's state of the art visual navigation agents typically consist of large deep learning models trained end to end. Such models offer little to no interpretability about the learned skills or the ac... tions of the agent taken in response to its environment. While past works have explored interpreting deep learning models, little attention has been devoted to interpreting embodied AI systems, which often involve reasoning about the structure of the environment, target characteristics and the outcome of one's actions. In this paper, we introduce the Interpretability System for Embodied agEnts (iSEE) for Point Goal and Object Goal navigation agents. We use iSEE to probe the dynamic representations produced by these agents for the presence of information about the agent as well as the environment. We demonstrate interesting insights about navigation agents using iSEE, including the ability to encode reachable locations (to avoid obstacles), visibility of the target, progress from the initial spawn location as well as the dramatic effect on the behaviors of agents when we mask out critical individual neurons.
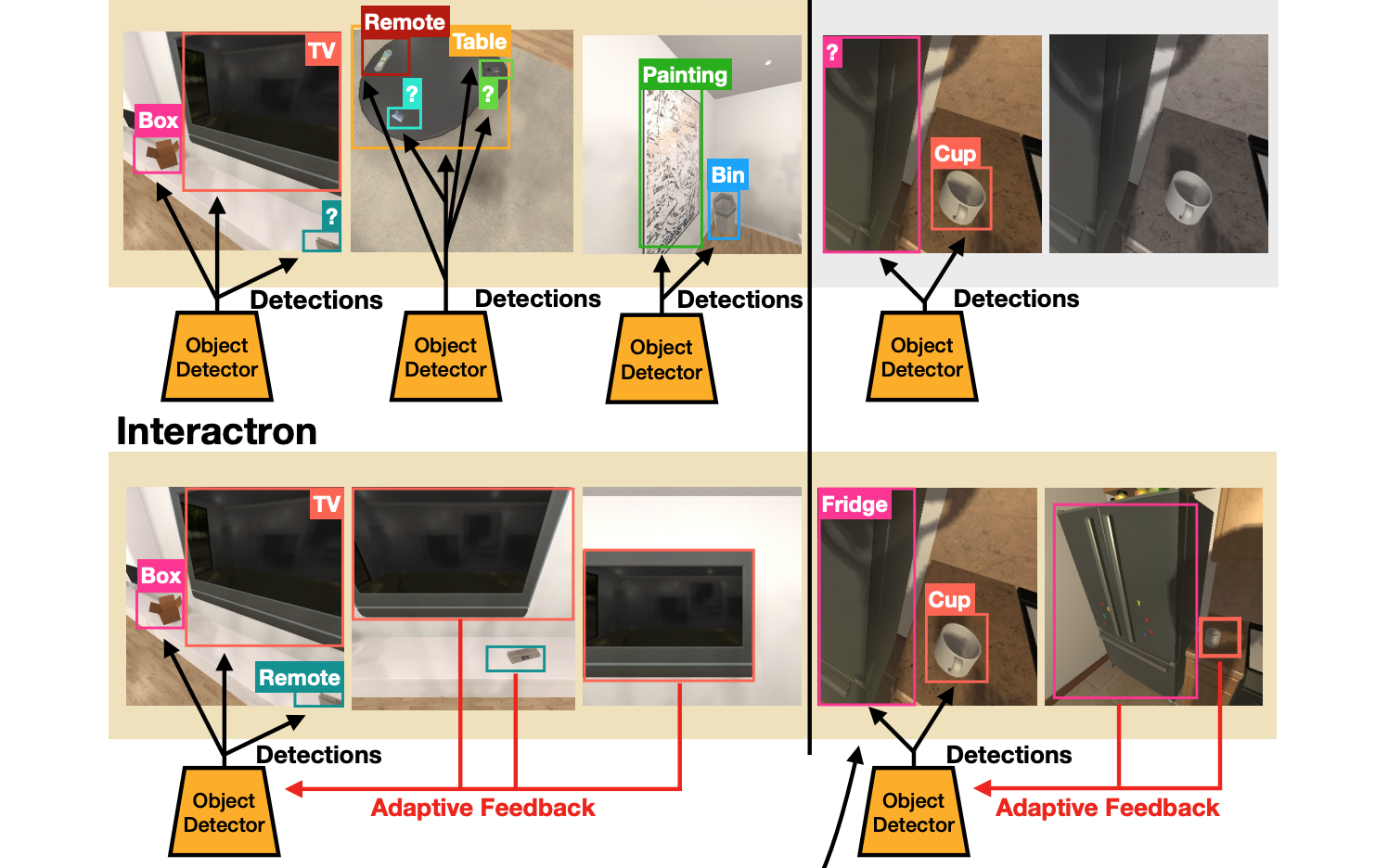
Over the years various methods have been proposed for the problem of object detection. Recently, we have witnessed great strides in this domain owing to the emergence of powerful deep neural networks.... However, there are typically two main assumptions common among these approaches. First, the model is trained on a fixed training set and is evaluated on a pre-recorded test set. Second, the model is kept frozen after the training phase, so no further updates are performed after the training is finished. These two assumptions limit the applicability of these methods to real-world settings. In this paper, we propose Interactron, a method for adaptive object detection in an interactive setting, where the goal is to perform object detection in images observed by an embodied agent navigating in different environments. Our idea is to continue training during inference and adapt the model at test time without any explicit supervision via interacting with the environment. Our adaptive object detection model provides a 11.8 point improvement in AP (and 19.1 points in AP50) over DETR, a recent, high performance object detector. Moreover, we show that our object detection model adapts to environments with completely different appearance characteristics, and its performance is on par with a model trained with full supervision for those environments.

The problem of knowledge-based visual question answering involves answering questions that require external knowledge in addition to the content of the image. Such knowledge typically comes in various... forms, including visual, textual, and commonsense knowledge. Using more knowledge sources increases the chance of retrieving more irrelevant or noisy facts, making it challenging to comprehend the facts and find the answer. To address this challenge, we propose Multi-modal Answer Validation using External knowledge (MAVEx), where the idea is to validate a set of promising answer candidates based on answer-specific knowledge retrieval. Instead of searching for the answer in a vast collection of often irrelevant facts as most existing approaches do, MAVEx aims to learn how to extract relevant knowledge from noisy sources, which knowledge source to trust for each answer candidate, and how to validate the candidate using that source. Our multi-modal setting is the first to leverage external visual knowledge (images searched using Google), in addition to textual knowledge in the form of Wikipedia sentences and ConceptNet concepts. Our experiments with OK-VQA, a challenging knowledge-based VQA dataset, demonstrate that MAVEx achieves new state-of-the-art results. Our code is available at https://github.com/jialinwu17/MAVEX

Communicating with humans is challenging for AIs because it requires a shared understanding of the world, complex semantics (e.g., metaphors or analogies), and at times multimodal gestures (e.g., poin... ting with a finger, or an arrow in a diagram). We investigate these challenges in the context of Iconary, a collaborative game of drawing and guessing based on Pictionary, that poses a novel challenge for the research community. In Iconary, a Guesser tries to identify a phrase that a Drawer is drawing by composing icons, and the Drawer iteratively revises the drawing to help the Guesser in response. This back-and-forth often uses canonical scenes, visual metaphor, or icon compositions to express challenging words, making it an ideal test for mixing language and visual/symbolic communication in AI. We propose models to play Iconary and train them on over 55,000 games between human players. Our models are skillful players and are able to employ world knowledge in language models to play with words unseen during training. Elite human players outperform our models, particularly at the drawing task, leaving an important gap for future research to address. We release our dataset, code, and evaluation setup as a challenge to the community at github.com/allenai/iconary.
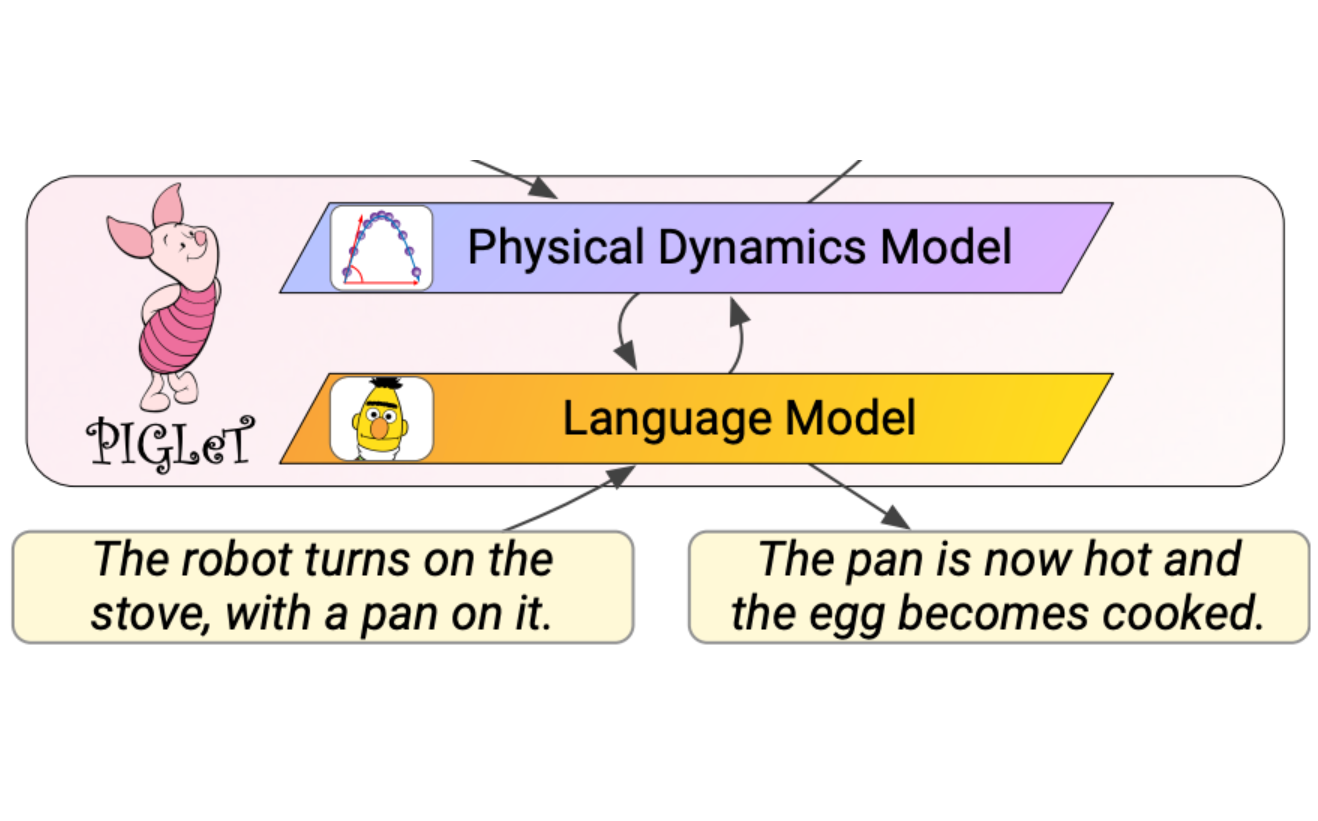
We propose PIGLeT: a model that learns physical commonsense knowledge through interaction, and then uses this knowledge to ground language. We factorize PIGLeT into a physical dynamics model, and a se... parate language model. Our dynamics model learns not just what objects are but also what they do: glass cups break when thrown, plastic ones don't. We then use it as the interface to our language model, giving us a unified model of linguistic form and grounded meaning. PIGLeT can read a sentence, simulate neurally what might happen next, and then communicate that result through a literal symbolic representation, or natural language. Experimental results show that our model effectively learns world dynamics, along with how to communicate them. It is able to correctly forecast what happens next given an English sentence over 80% of the time, outperforming a 100x larger, text-to-text approach by over 10%. Likewise, its natural language summaries of physical interactions are also judged by humans as more accurate than LM alternatives. We present comprehensive analysis showing room for future work
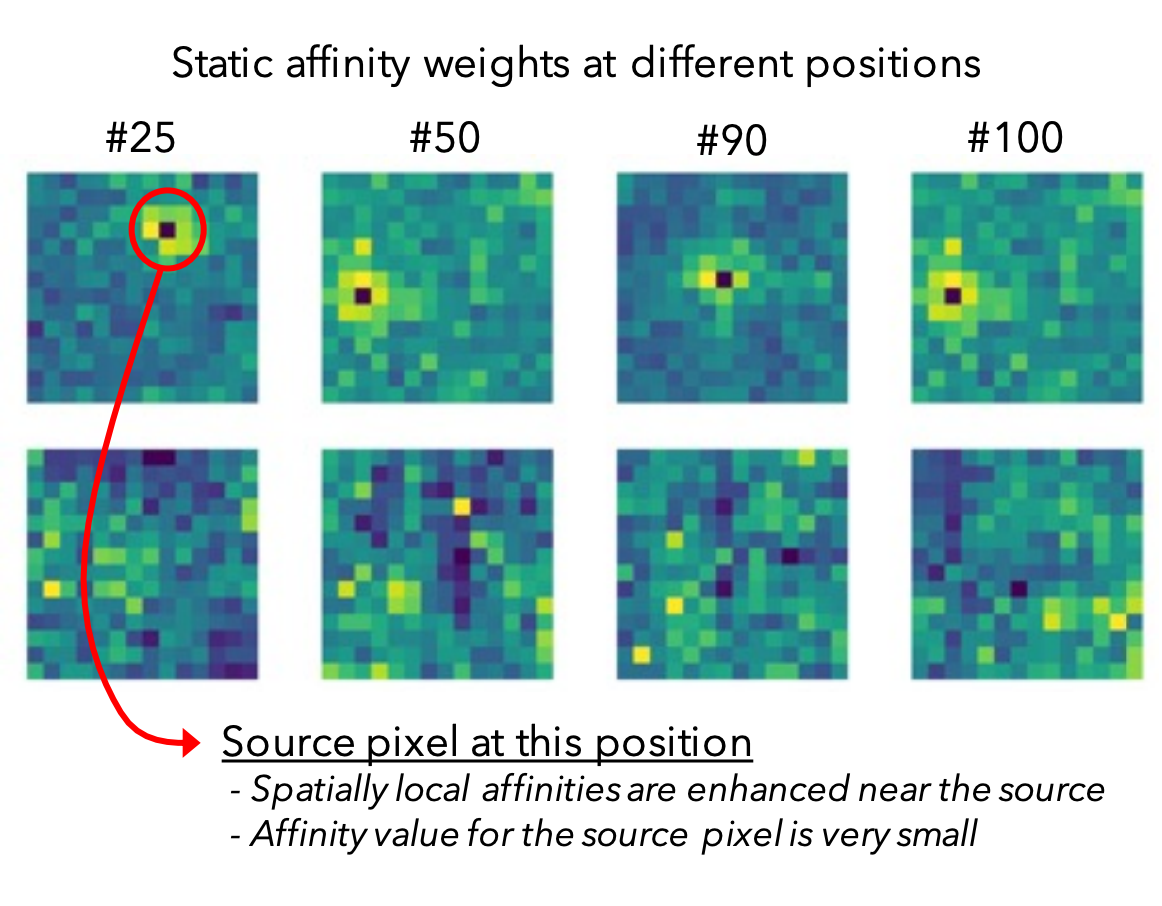
Convolutional neural networks (CNNs) are ubiquitous in computer vision, with a myriad of effective and efficient variations. Recently, Transformers -- originally introduced in natural language process... ing -- have been increasingly adopted in computer vision. While early adopters continue to employ CNN backbones, the latest networks are end-to-end CNN-free Transformer solutions. A recent surprising finding shows that a simple MLP based solution without any traditional convolutional or Transformer components can produce effective visual representations. While CNNs, Transformers and MLP-Mixers may be considered as completely disparate architectures, we provide a unified view showing that they are in fact special cases of a more general method to aggregate spatial context in a neural network stack. We present the model (CONText AggregatIon NEtwoRk), a general-purpose building block for multi-head context aggregation that can exploit long-range interactions a la Transformers while still exploiting the inductive bias of the local convolution operation leading to faster convergence speeds, often seen in CNNs. In contrast to Transformer-based methods that do not scale well to downstream tasks that rely on larger input image resolutions, our efficient network, named modellight, can be employed in object detection and instance segmentation networks such as DETR, RetinaNet and Mask-RCNN to obtain an impressive detection mAP of 38.9, 43.8, 45.1 and mask mAP of 41.3, providing large improvements of 6.6, 7.3, 6.9 and 6.6 pts respectively, compared to a ResNet-50 backbone with a comparable compute and parameter size. Our method also achieves promising results on self-supervised learning compared to DeiT on the DINO framework.
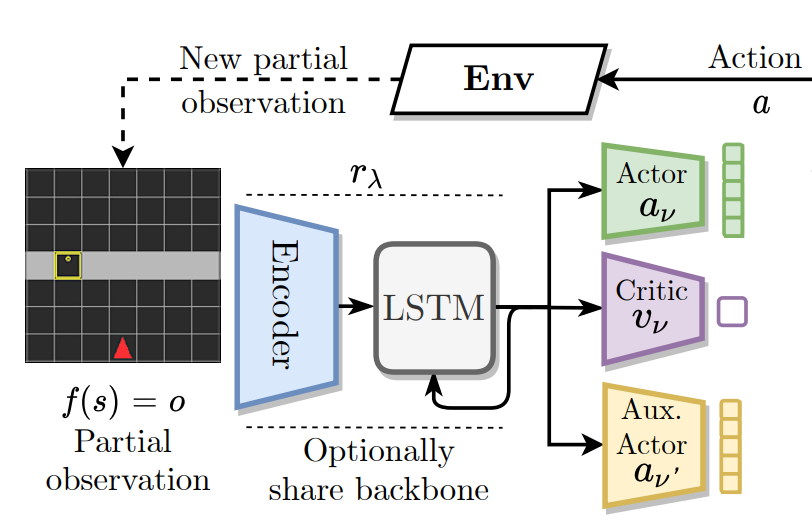
In practice, imitation learning is preferred over pure reinforcement learning whenever it is possible to design a teaching agent to provide expert supervision. However, we show that when the teaching... agent makes decisions with access to privileged information that is unavailable to the student, this information is marginalized during imitation learning, resulting in an "imitation gap" and, potentially, poor results. Prior work bridges this gap via a progression from imitation learning to reinforcement learning. While often successful, gradual progression fails for tasks that require frequent switches between exploration and memorization. To better address these tasks and alleviate the imitation gap we propose 'Adaptive Insubordination' (ADVISOR). ADVISOR dynamically weights imitation and reward-based reinforcement learning losses during training, enabling on-the-fly switching between imitation and exploration. On a suite of challenging tasks set within gridworlds, multi-agent particle environments, and high-fidelity 3D simulators, we show that on-the-fly switching with ADVISOR outperforms pure imitation, pure reinforcement learning, as well as their sequential and parallel combinations.

Performing simple household tasks based on language directives is very natural to humans, yet it remains an open challenge for AI agents. The 'interactive instruction following' task attempts to make... progress towards building agents that jointly navigate, interact, and reason in the environment at every step. To address the multifaceted problem, we propose a model that factorizes the task into interactive perception and action policy streams with enhanced components and name it as MOCA, a Modular Object-Centric Approach. We empirically validate that MOCA outperforms prior arts by significant margins on the ALFRED benchmark with improved generalization.
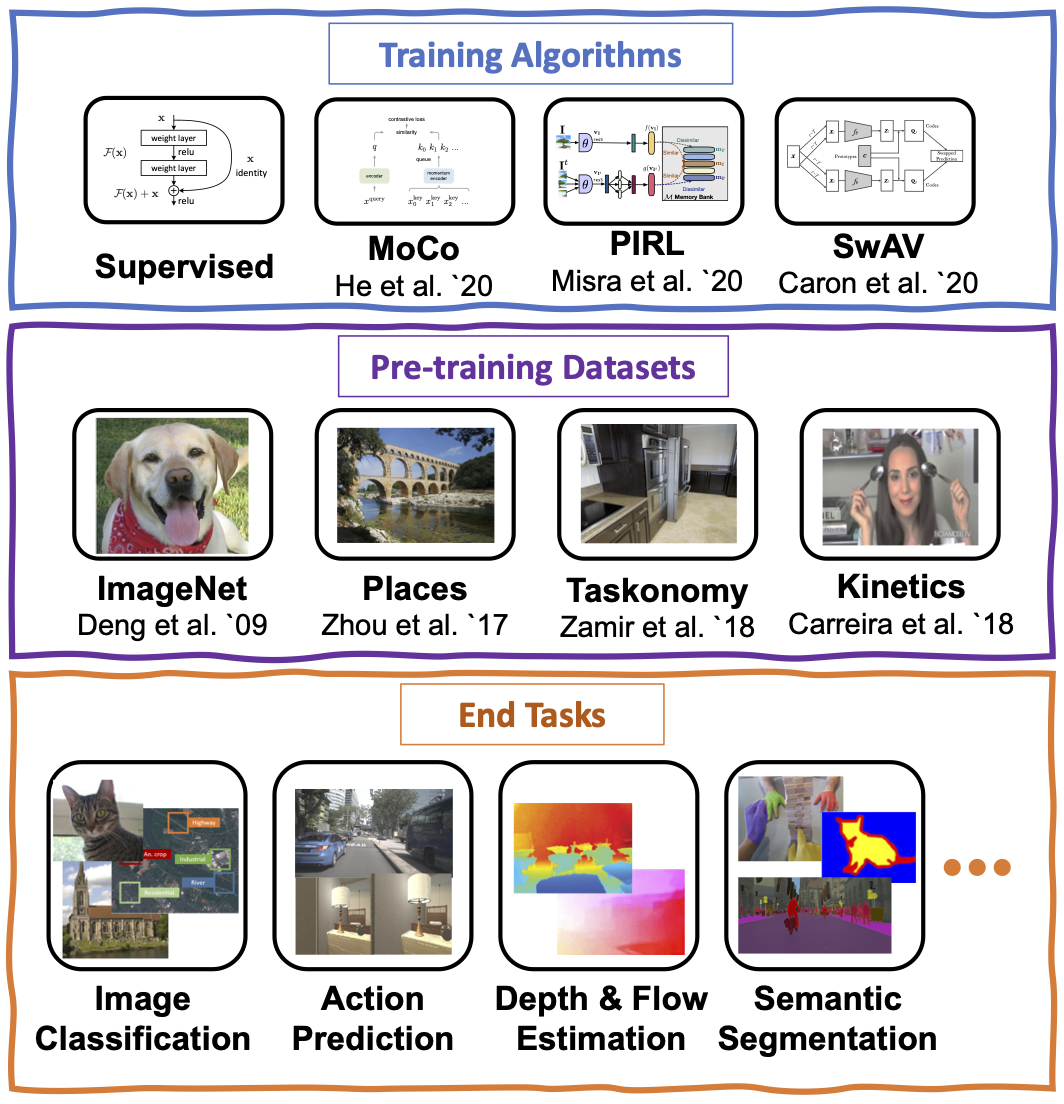
In the past few years, we have witnessed remarkable breakthroughs in self-supervised representation learning. Despite the success and adoption of representations learned through this paradigm, much is... yet to be understood about how different training methods and datasets influence performance on downstream tasks. In this paper, we analyze contrastive approaches as one of the most successful and popular variants of self-supervised representation learning. We perform this analysis from the perspective of the training algorithms, pre-training datasets and end tasks. We examine over 700 training experiments including 30 encoders, 4 pre-training datasets and 20 diverse downstream tasks. Our experiments address various questions regarding the performance of self-supervised models compared to their supervised counterparts, current benchmarks used for evaluation, and the effect of the pre-training data on end task performance.
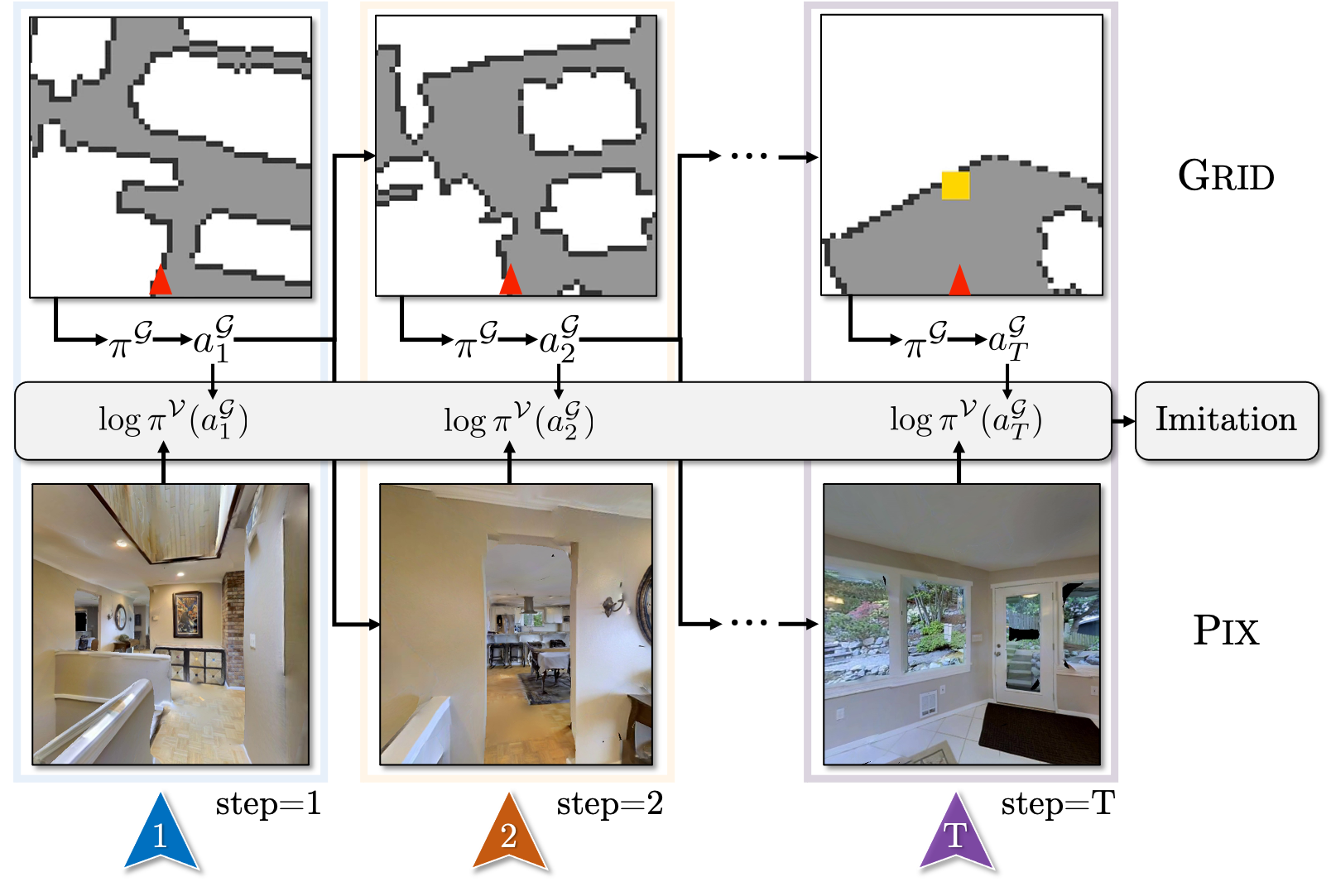
While deep reinforcement learning (RL) promises freedom from hand-labeled data, great successes, especially for Embodied AI, require significant work to create supervision via carefully shaped rewards... . Indeed, without shaped rewards, i.e., with only terminal rewards, present-day Embodied AI results degrade significantly across Embodied AI problems from single-agent Habitat-based PointGoal Navigation (SPL drops from 55 to 0) and two-agent AI2-THOR-based Furniture Moving (success drops from 58% to 1%) to three-agent Google Football-based 3 vs. 1 with Keeper (game score drops from 0.6 to 0.1). As training from shaped rewards doesn’t scale to more realistic tasks, the community needs to improve the success of training with terminal rewards. For this we propose GridToPix: 1) train agents with terminal rewards in gridworlds that generically mirror Embodied AI environments, i.e., they are independent of the task; 2) distill the learned policy into agents that reside in complex visual worlds. Despite learning from only terminal rewards with identical models and RL algorithms, GridToPix significantly improves results across tasks: from PointGoal Navigation (SPL improves from 0 to 64) and Furniture Moving (success improves from 1% to 25%) to football gameplay (game score improves from 0.1 to 0.6). GridToPix even helps to improve the results of shaped reward training.
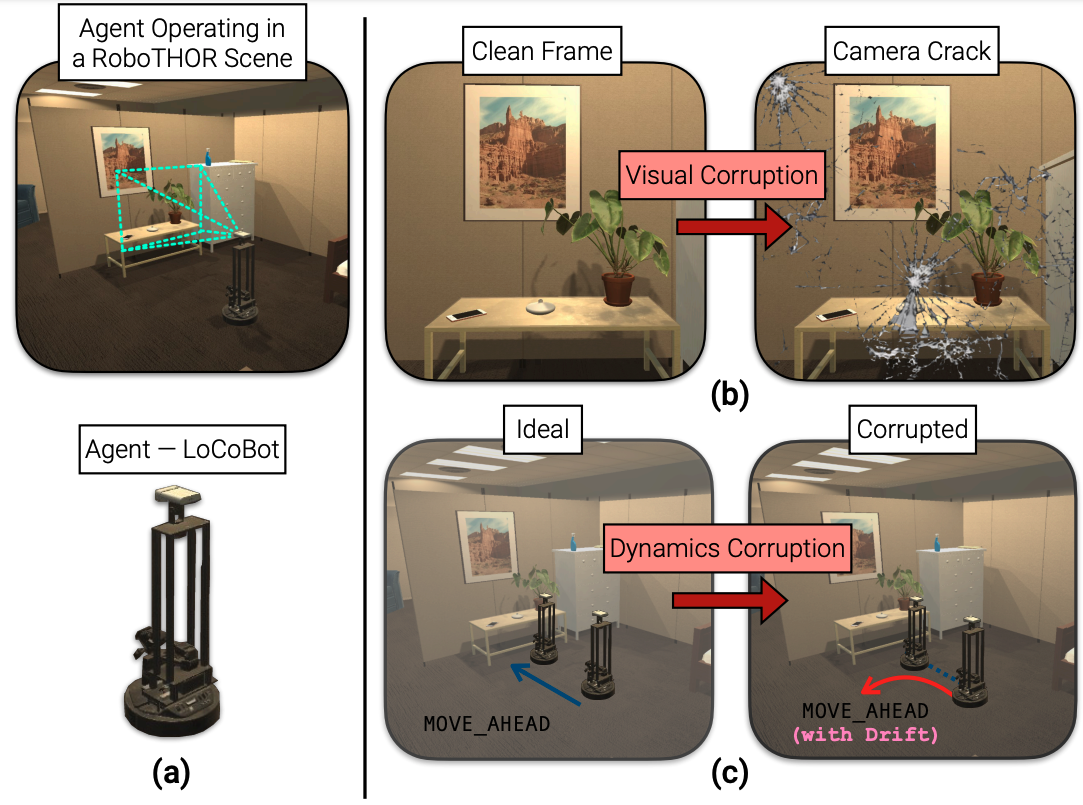
As an attempt towards assessing the robustness of embodied navigation agents, we propose RobustNav, a framework to quantify the performance of embodied navigation agents when exposed to a wide variety... of visual – affecting RGB inputs – and dynamics – affecting transition dynamics – corruptions. Most recent efforts in visual navigation have typically focused on generalizing to novel target environments with similar appearance and dynamics characteristics. With RobustNav, we find that some standard embodied navigation agents significantly underperform (or fail) in the presence of visual or dynamics corruptions. We systematically analyze the kind of idiosyncrasies that emerge in the behavior of such agents when operating under corruptions. Finally, for visual corruptions in RobustNav, we show that while standard techniques to improve robustness such as data-augmentation and self-supervised adaptation offer some zero-shot resistance and improvements in navigation performance, there is still a long way to go in terms of recovering lost performance relative to clean “non-corrupt” settings, warranting more research in this direction.
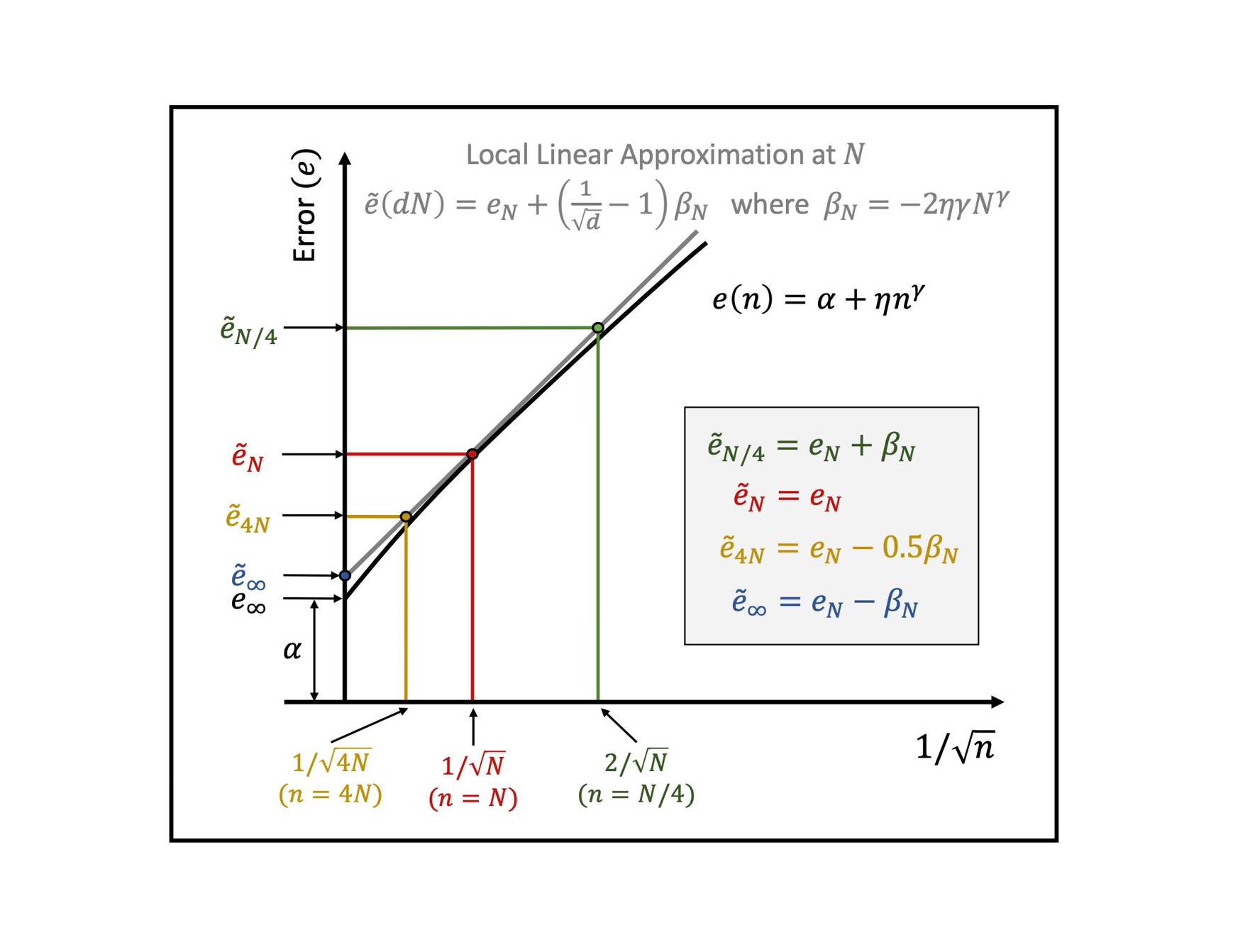
Learning curves model a classifier's test error as a function of the number of training samples. Prior works show that learning curves can be used to select model parameters and extrapolate performanc... e. We investigate how to use learning curves to evaluate design choices, such as pretraining, architecture, and data augmentation. We propose a method to robustly estimate learning curves, abstract their parameters into error and data-reliance, and evaluate the effectiveness of different parameterizations. Our experiments exemplify use of learning curves for analysis and yield several interesting observations.
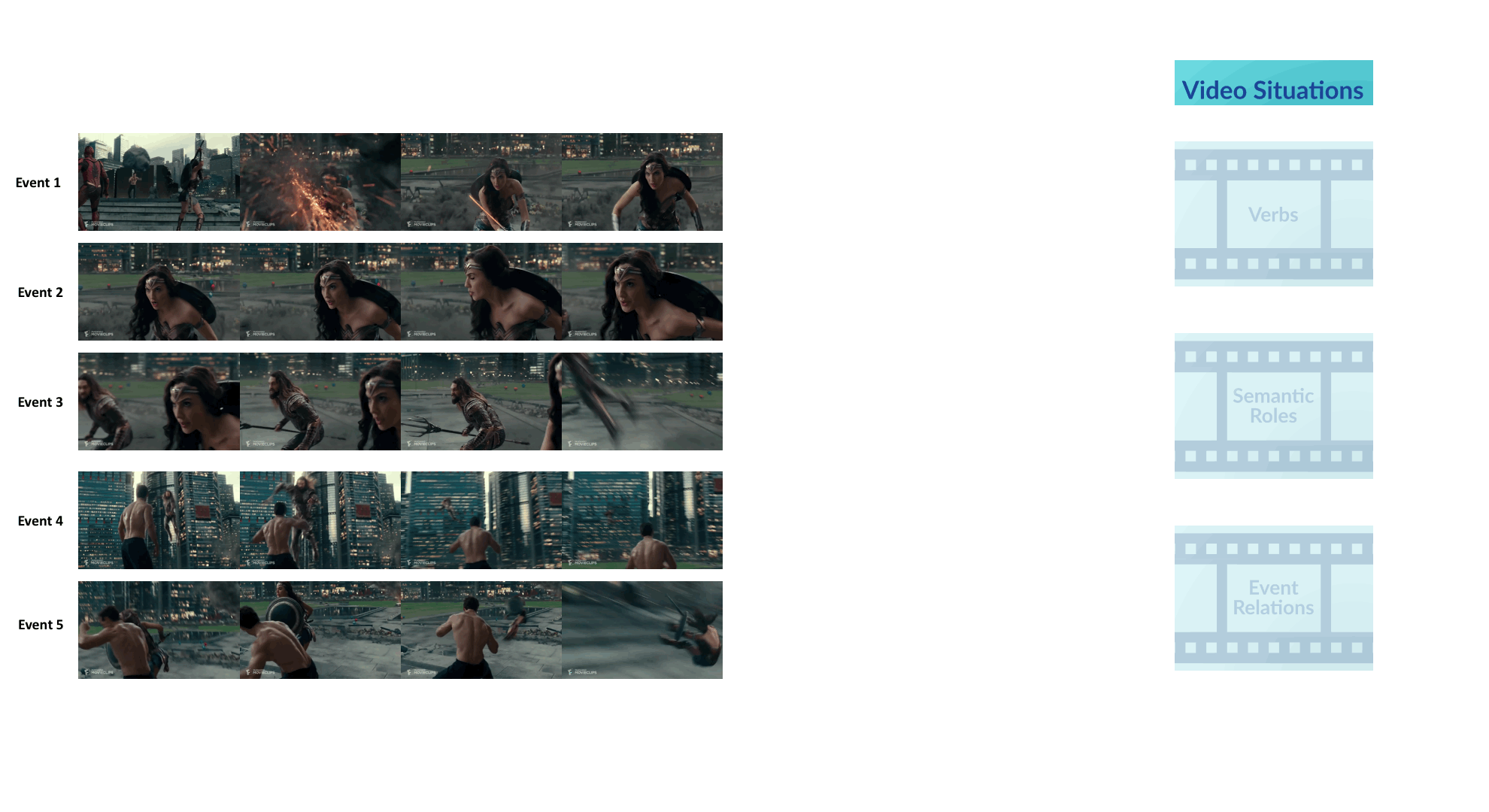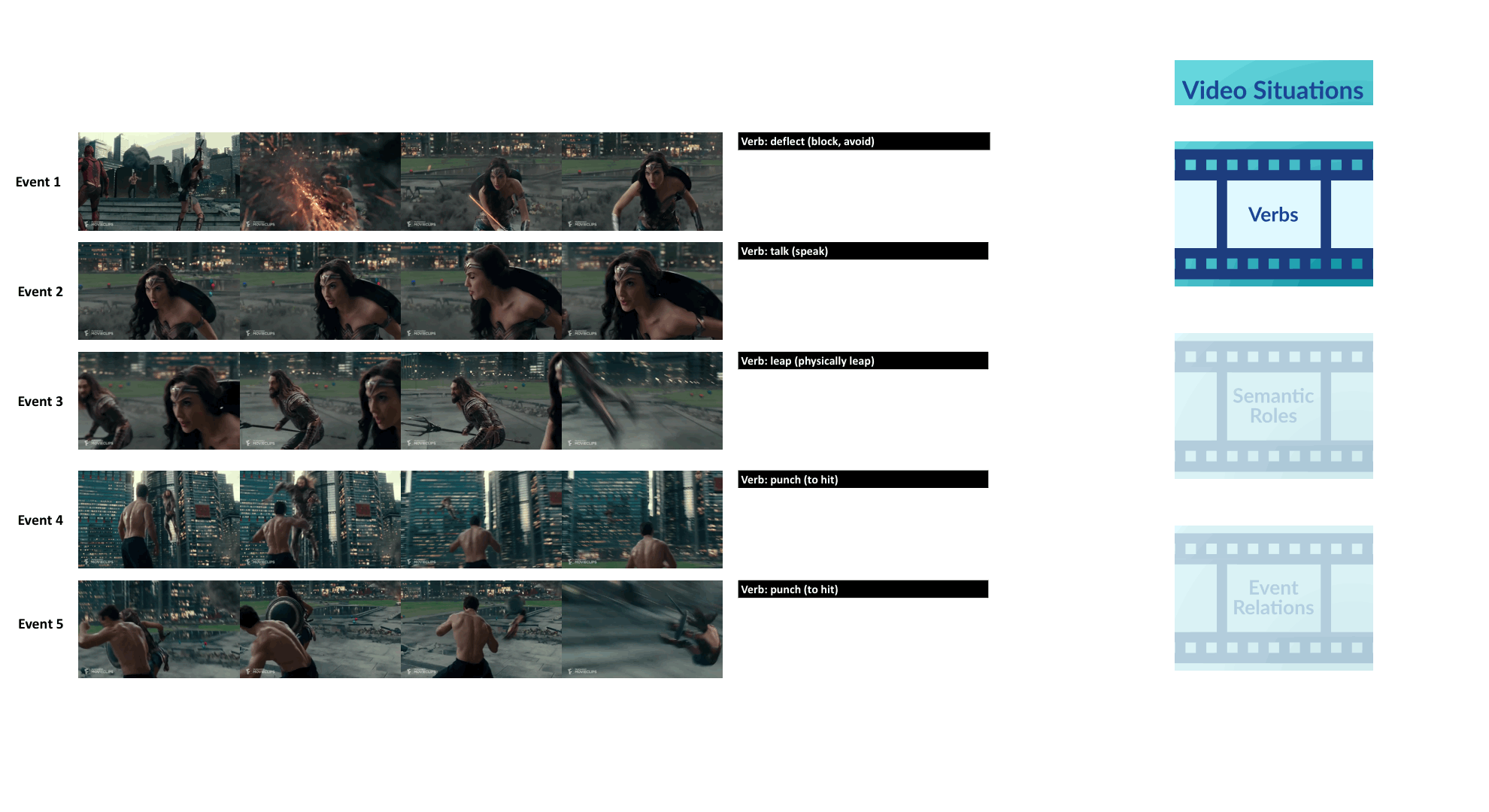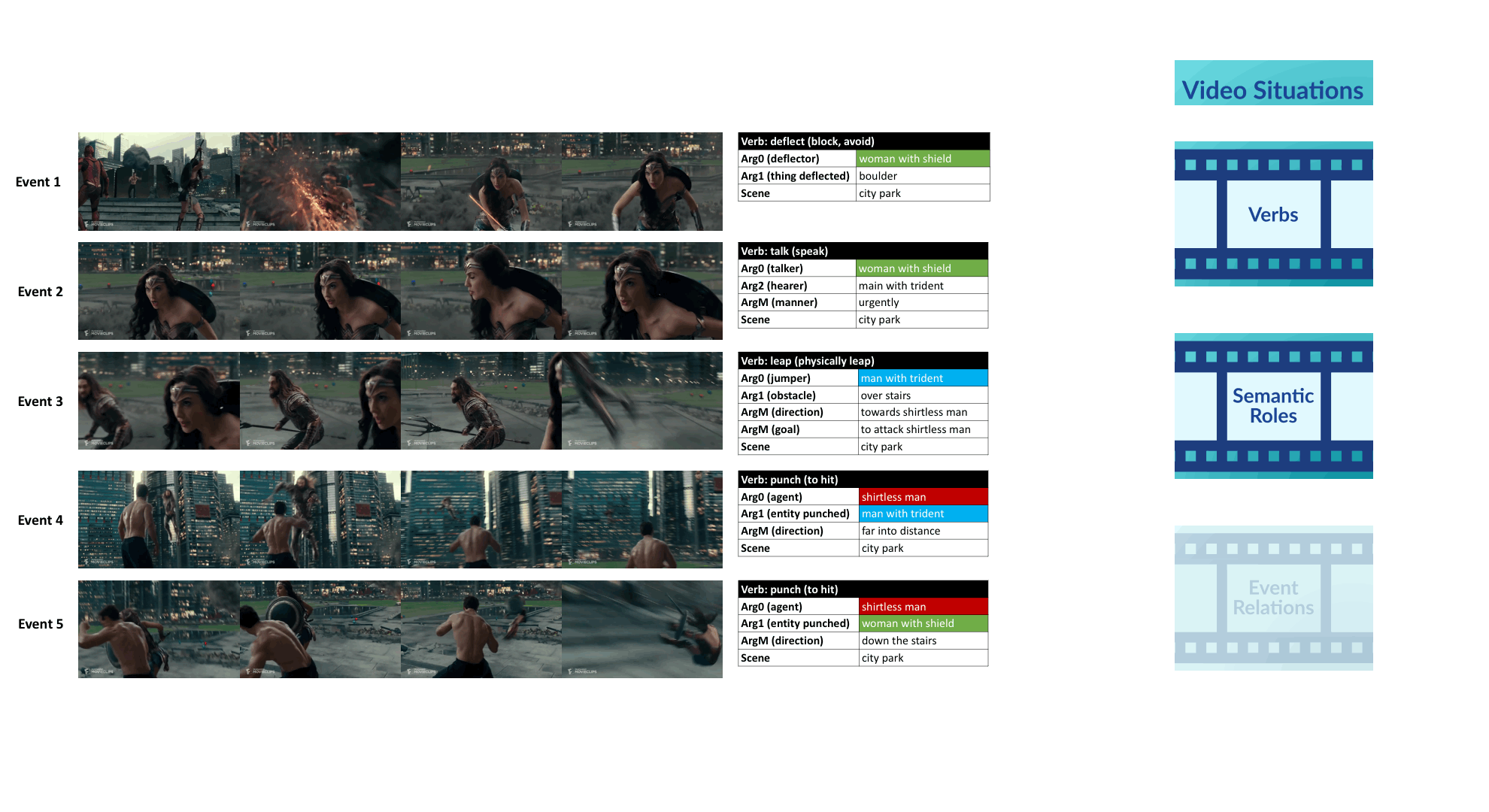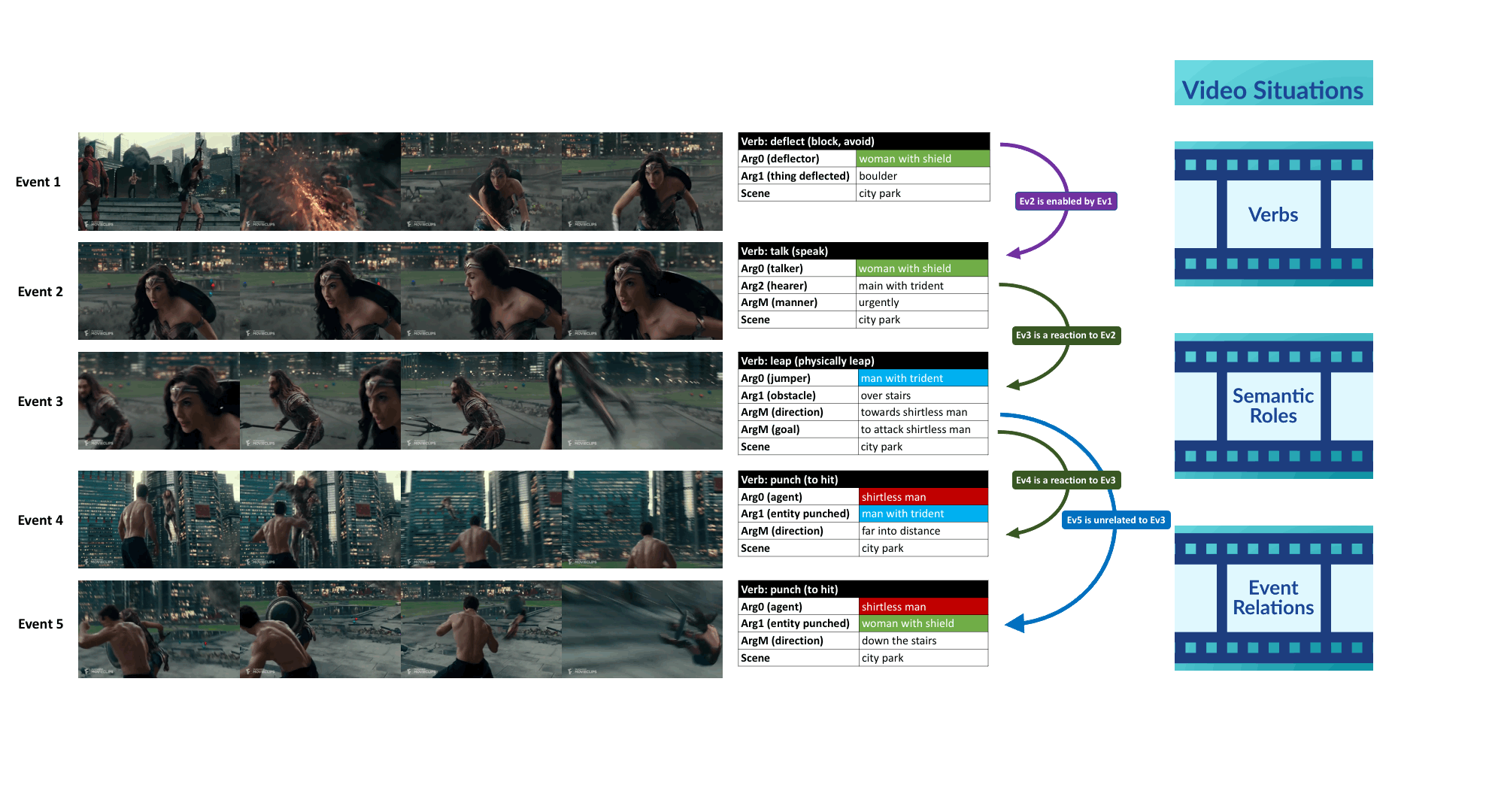
We propose a new framework for understanding and representing related salient events in a video using visual semantic role labeling. We represent videos as a set of related events, wherein each event... consists of a verb and multiple entities that fulfill various roles relevant to that event. To study the challenging task of semantic role labeling in videos or VidSRL, we introduce the VidSitu benchmark, a large-scale video understanding data source with 29K 10-second movie clips richly annotated with a verb and semantic-roles every 2 seconds. Entities are co-referenced across events within a movie clip and events are connected to each other via event-event relations. Clips in VidSitu are drawn from a large collection of movies (∼3K) and have been chosen to be both complex (∼4.2 unique verbs within a video) as well as diverse (∼200 verbs have more than 100 annotations each). We provide a comprehensive analysis of the dataset in comparison to other publicly available video understanding benchmarks, several illustrative baselines and evaluate a range of standard video recognition models.

We present ManipulaTHOR, a framework that facilitates visual manipulation of objects using a robotic arm. Our framework is built upon a physics engine and enables realistic interactions with objects w... hile navigating through scenes and performing tasks. Object manipulation is an established research domain within the robotics community and poses several challenges including avoiding collisions, grasping, and long-horizon planning. Our framework focuses primarily on manipulation in visually rich and complex scenes, joint manipulation and navigation planning, and generalization to unseen environments and objects; challenges that are often overlooked. The framework provides a comprehensive suite of sensory information and motor functions enabling development of robust manipulation agents.

Learning effective representations of visual data that generalize to a variety of downstream tasks has been a long quest for computer vision. Most representation learning approaches rely solely on vis... ual data such as images or videos. In this paper, we explore a novel approach, where we use human interaction and attention cues to investigate whether we can learn better representations compared to visual only representations. For this study, we collect a dataset of human interactions capturing body part movements and gaze in their daily lives. Our experiments show that our “muscly-supervised” representation that encodes interaction and attention cues outperforms a visual-only state-of-the-art method MoCo (He et al., 2020), on a variety of target tasks: scene classification (semantic), action recognition (temporal), depth estimation (geometric), dynamics prediction (physics) and walkable surface estimation (affordance).

We have observed significant progress in visual navigation for embodied agents. A common assumption in studying visual navigation is that the environments are static; this is a limiting assumption. In... telligent navigation may involve interacting with the environment beyond just moving forward/backward and turning left/right. Sometimes, the best way to navigate is to push something out of the way. In this paper, we study the problem of interactive navigation where agents learn to change the environment to navigate more efficiently to their goals. To this end, we introduce the Neural Interaction Engine (NIE) to explicitly predict the change in the environment caused by the agent's actions. By modeling the changes while planning, we find that agents exhibit significant improvements in their navigational capabilities. More specifically, we consider two downstream tasks in the physics-enabled, visually rich, AI2-THOR environment: (1) reaching a target while the path to the target is blocked (2) moving an object to a target location by pushing it. For both tasks, agents equipped with an NIE significantly outperform agents without the understanding of the effect of the actions indicating the benefits of our approach. The code and dataset are available at github.com/KuoHaoZeng/ Interactive_Visual_Navigation.

There has been a significant recent progress in the field of Embodied AI with researchers developing models and algorithms enabling embodied agents to navigate and interact within completely unseen en... vironments. In this paper, we propose a new dataset and baseline models for the task of Rearrangement. We particularly focus on the task of Room Rearrangement: an agent begins by exploring a room and recording objects’ initial configurations. We then remove the agent and change the poses and states (e.g., open/closed) of some objects in the room. The agent must restore the initial configurations of all objects in the room. Our dataset, named RoomR, includes 6,000 distinct rearrangement settings involving 72 different object types in 120 scenes. Our experiments show that solving this challenging interactive task that involves navigation and object interaction is beyond the capabilities of the current state-of-the-art techniques for embodied tasks and we are still very far from achieving perfect performance on these types of tasks.
A growing body of research suggests that embodied gameplay, prevalent not just in human cultures but across a variety of animal species including turtles and ravens, is critical in developing the neur... al flexibility for creative problem solving, decision making, and socialization. Comparatively little is known regarding the impact of embodied gameplay upon artificial agents. While recent work has produced agents proficient in abstract games, these environments are far removed from the real world and thus these agents can provide little insight into the advantages of embodied play. Hiding games, such as hide-and-seek, played universally, provide a rich ground for studying the impact of embodied gameplay on representation learning in the context of perspective taking, secret keeping, and false belief understanding. Here we are the first to show that embodied adversarial reinforcement learning agents playing Cache, a variant of hide-and-seek, in a high fidelity, interactive, environment, learn generalizable representations of their observations encoding information such as object permanence, free space, and containment. Moving closer to biologically motivated learning strategies, our agents’ representations, enhanced by intentionality and memory, are developed through interaction and play. These results serve as a model for studying how facets of vision develop through interaction, provide an experimental framework for assessing what is learned by artificial agents, and demonstrates the value of moving from large, static, datasets towards experiential, interactive, representation learning.

Learning effective representations of visual data that generalize to a variety of downstream tasks has been a long quest for computer vision. Most representation learning approaches rely solely on vis... ual data such as images or videos. In this paper, we explore a novel approach, where we use human interaction and attention cues to investigate whether we can learn better representations compared to visualonly representations. For this study, we collect a dataset of human interactions capturing body part movements and gaze in their daily lives. Our experiments show that our “muscly-supervised” representation that encodes interaction and attention cues outperforms a visual-only state-of-the-art method MoCo (He et al., 2020), on a variety of target tasks: scene classification (semantic), action recognition (temporal), depth estimation (geometric), dynamics prediction (physics) and walkable surface estimation (affordance). Our code and dataset are available at: https://github.com/ehsanik/muscleTorch.
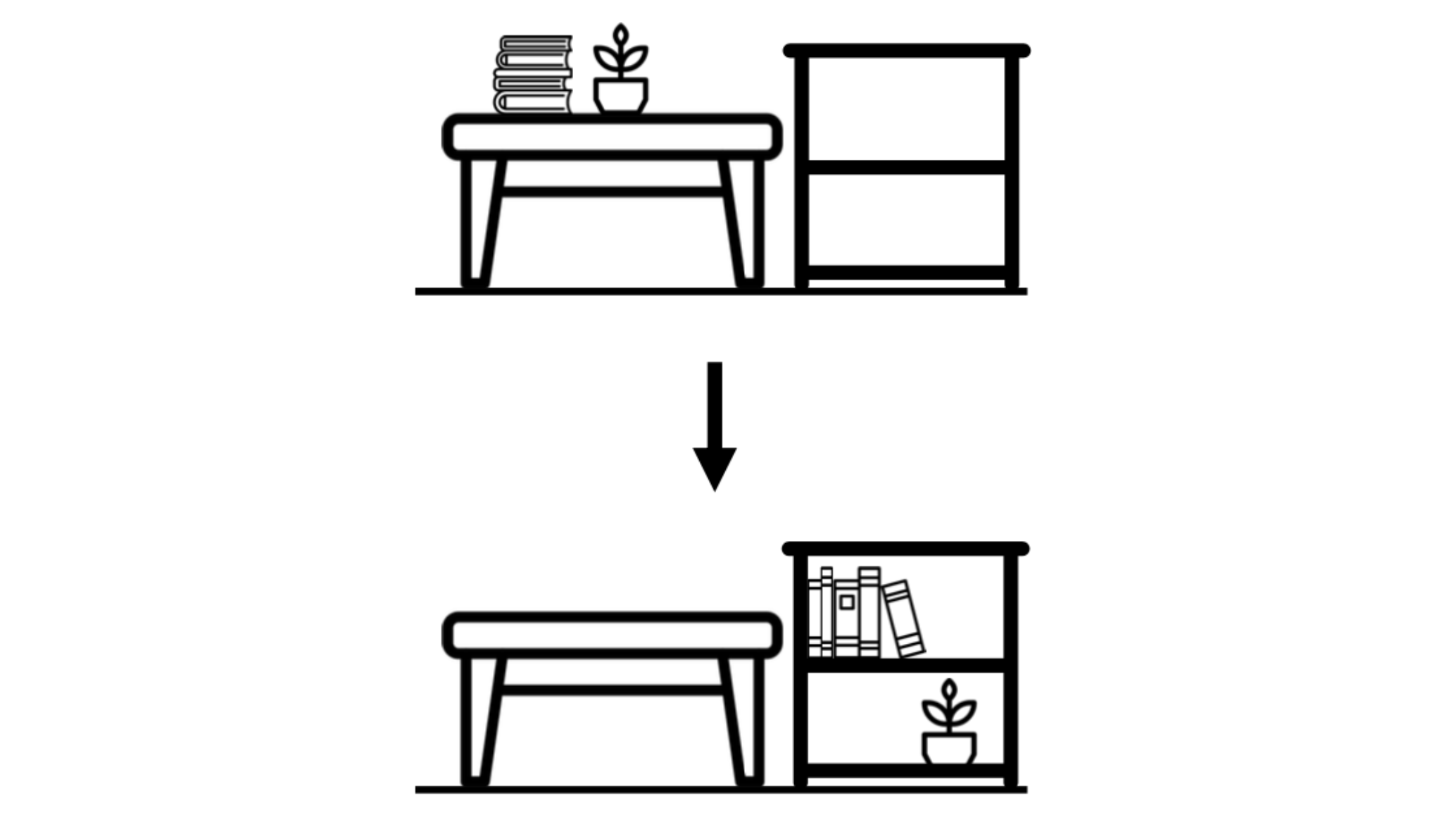
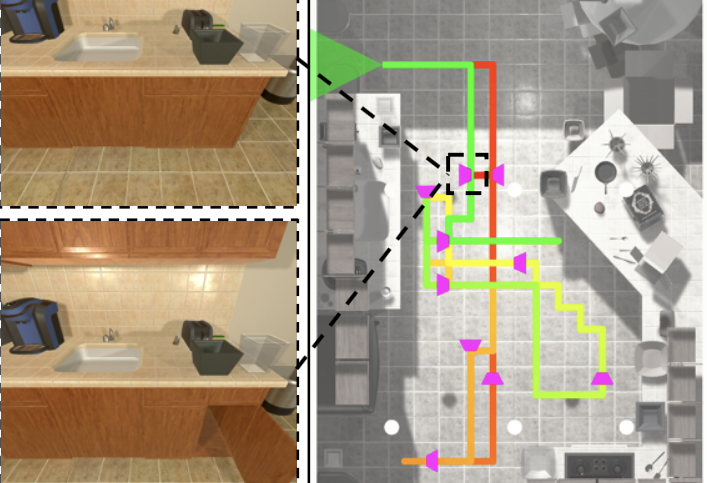
We describe a framework for research and evaluation in Embodied AI. Our proposal is based on a canonical task: Rearrangement. A standard task can focus the development of new techniques and serve as a... source of trained models that can be transferred to other settings. In the rearrangement task, the goal is to bring a given physical environment into a specified state. The goal state can be specified by object poses, by images, by a description in language, or by letting the agent experience the environment in the goal state. We characterize rearrangement scenarios along different axes and describe metrics for benchmarking rearrangement performance. To facilitate research and exploration, we present experimental testbeds of rearrangement scenarios in four different simulation environments. We anticipate that other datasets will be released and new simulation platforms will be built to support training of rearrangement agents and their deployment on physical systems.
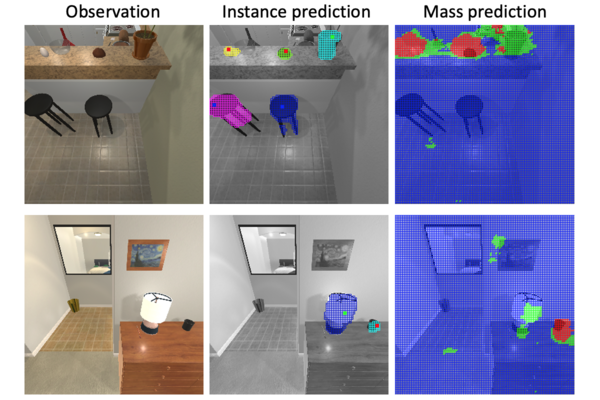
Much of the remarkable progress in computer vision has been focused around fully supervised learning mechanisms relying on highly curated datasets for a variety of tasks. In contrast, humans often lea... rn about their world with little to no external supervision. Taking inspiration from infants learning from their environment through play and interaction, we present a computational framework to discover objects and learn their physical properties along this paradigm of Learning from Interaction. Our agent, when placed within the near photo-realistic and physics-enabled AI2THOR environment, interacts with its world and learns about objects, their geometric extents and relative masses, without any external guidance. Our experiments reveal that this agent learns efficiently and effectively; not just for objects it has interacted with before, but also for novel instances from seen categories as well as novel object categories.

Mirroring the success of masked language models, vision-and-language counterparts like VILBERT, LXMERT and UNITER have achieved state of the art performance on a variety of multimodal discriminative t... asks like visual question answering and visual grounding. Recent work has also successfully adapted such models towards the generative task of image captioning. This begs the question: Can these models go the other way and generate images from pieces of text? Our analysis of a popular representative from this model family – LXMERT – finds that it is unable to generate rich and semantically meaningful imagery with its current training setup. We introduce X-LXMERT, an extension to LXMERT with training refinements including: discretizing visual representations, using uniform masking with a large range of masking ratios and aligning the right pre-training datasets to the right objectives which enables it to paint. X-LXMERT’s image generation capabilities rival state of the art generative models while its question answering and captioning abilities remains comparable to LXMERT.

The domain of Embodied AI, in which agents learn to complete tasks through interaction with their environment from egocentric observations, has experienced substantial growth with the advent of de... ep reinforcement learning and increased interest from the computer vision, NLP, and robotics communities. This growth has been facilitated by the creation of a large number of simulated environments (such as AI2-THOR, Habitat and CARLA), tasks (like point navigation, instruction following, and embodied question answering), and associated leaderboards. While this diversity has been beneficial and organic, it has also fragmented the community: a huge amount of effort is required to do something as simple as taking a model trained in one environment and testing it in another. This discourages good science. We introduce AllenAct, a modular and flexible learning framework designed with a focus on the unique requirements of Embodied AI research. AllenAct provides first-class support for a growing collection of embodied environments, tasks and algorithms, provides reproductions of state-of-the-art models and includes extensive documentation, tutorials, start-up code, and pre-trained models. We hope that our framework makes Embodied AI more accessible and encourages new researchers to join this exciting area. The framework can be accessed at: https://allenact.org/
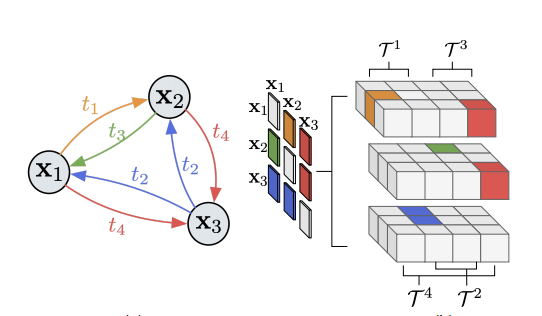
Textual cues are essential for everyday tasks like buying groceries and using public transport. To develop this assistive technology, we study the TextVQA task, i.e., reasoning about text in images to... answer a question. Existing approaches are limited in their use of spatial relations and rely on fully-connected transformer-like architectures to implicitly learn the spatial structure of a scene. In contrast, we propose a novel spatially aware self-attention layer such that each visual entity only looks at neighboring entities defined by a spatial graph. Further, each head in our multi-head self-attention layer focuses on a different subset of relations. Our approach has two advantages: (1) each head considers local context instead of dispersing the attention amongst all visual entities; (2) we avoid learning redundant features. We show that our model improves the absolute accuracy of current state-of-the-art methods on TextVQA by 2.2% overall over an improved baseline, and 4.62% on questions that involve spatial reasoning and can be answered correctly using OCR tokens. Similarly on ST-VQA, we improve the absolute accuracy by 4.2%. We further show that spatially aware self-attention improves visual grounding.
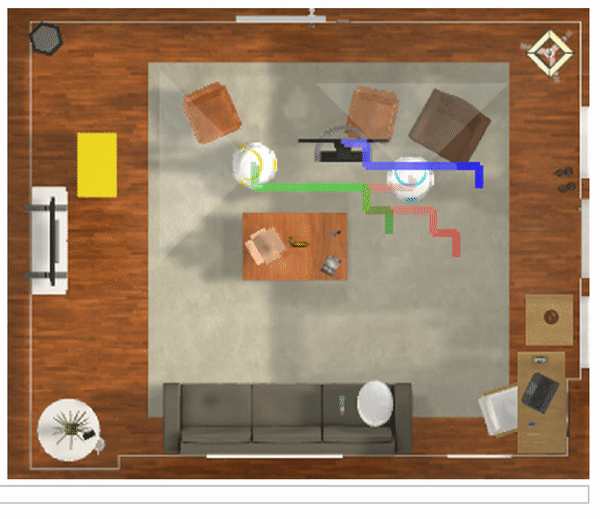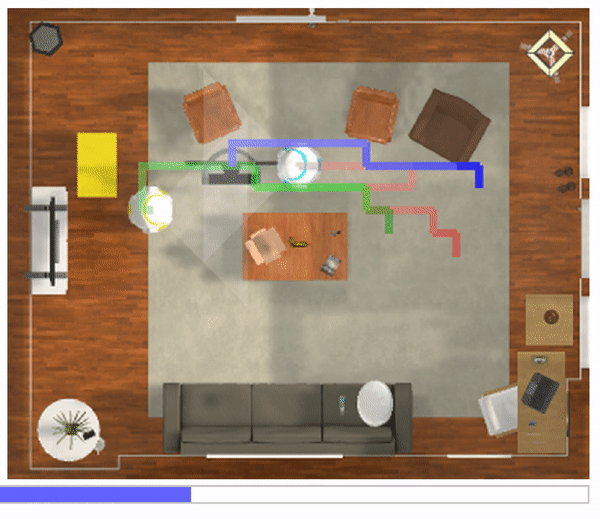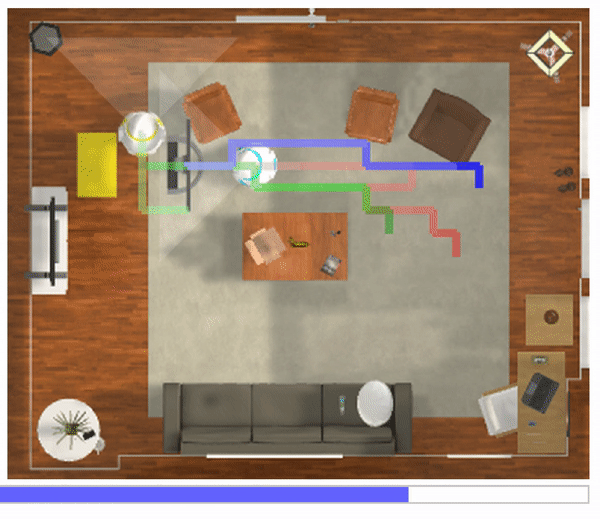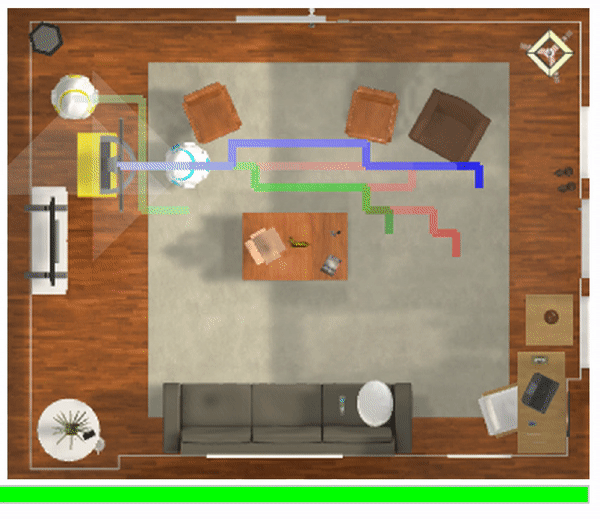
Autonomous agents must learn to collaborate. It is not scalable to develop a new centralized agent every time a task's difficulty outpaces a single agent's abilities. While multi-agent collaboration r... esearch has flourished in gridworld-like environments, relatively little work has considered visually rich domains. Addressing this, we introduce the novel task FurnMove in which agents work together to move a piece of furniture through a living room to a goal. Unlike existing tasks, FurnMove requires agents to coordinate at every timestep. We identify two challenges when training agents to complete FurnMove: existing decentralized action sampling procedures do not permit expressive joint action policies and, in tasks requiring close coordination, the number of failed actions dominates successful actions. To confront these challenges we introduce SYNC-policies (synchronize your actions coherently) and CORDIAL (coordination loss). Using SYNC-policies and CORDIAL, our agents achieve a 58% completion rate on FurnMove, an impressive absolute gain of 25 percentage points over competitive decentralized baselines.

We introduce Grounded Situation Recognition (GSR), a task that requires producing structured semantic summaries of images describing: the primary activity, entities engaged in the activity with their... roles (e.g. agent, tool), and bounding-box groundings of entities. GSR presents important technical challenges: identifying semantic saliency, categorizing and localizing a large and diverse set of entities, overcoming semantic sparsity, and disambiguating roles. Moreover, unlike in captioning, GSR is straightforward to evaluate. To study this new task we create the Situations With Groundings (SWiG) dataset which adds 278,336 bounding-box groundings to the 11,538 entity classes in the imsitu dataset. We propose a Joint Situation Localizer and find that jointly predicting situations and groundings with end-to-end training handily outperforms independent training on the entire grounding metric suite with relative gains between 8% and 32%. Finally, we show initial findings on three exciting future directions enabled by our models: conditional querying, visual chaining, and grounded semantic aware image retrieval.
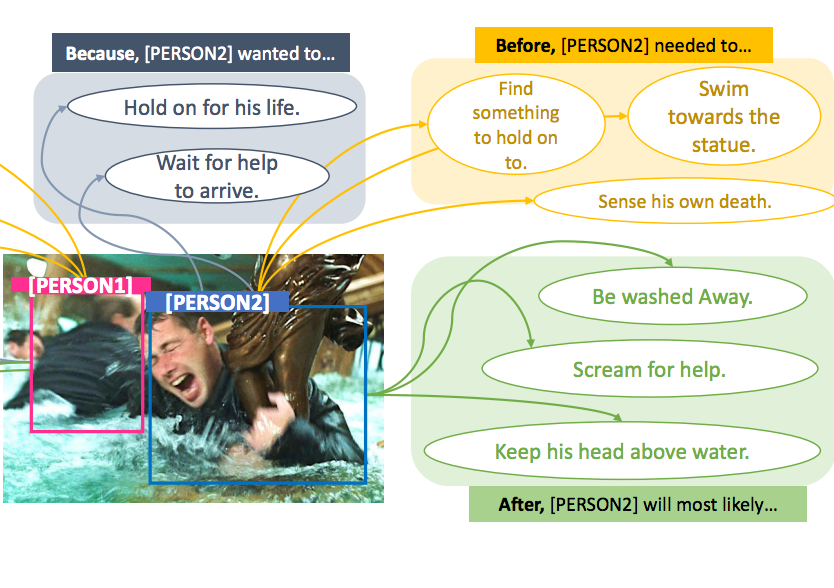
Even from a single frame of a still image, people can reason about the dynamic story of the image before, after, and beyond the frame. For example, given an image of a man struggling to stay afloat in... water, we can reason that the man fell into the water sometime in the past, the intent of that man at the moment is to stay alive, and he will need help in the near future or else he will get washed away. We propose VisualComet, the novel framework of visual commonsense reasoning tasks to predict events that might have happened before, events that might happen next, and the intents of the people at present. To support research toward visual commonsense reasoning, we introduce the first large-scale repository of Visual Commonsense Graphs that consists of over 1.4 million textual descriptions of visual commonsense inferences carefully annotated over a diverse set of 60,000 images, each paired with short video summaries of before and after. In addition, we provide person-grounding (i.e., co-reference links) between people appearing in the image and people mentioned in the textual commonsense descriptions, allowing for tighter integration between images and text. We establish strong baseline performances on this task and demonstrate that integration between visual and textual commonsense reasoning is the key and wins over non-integrative alternatives.
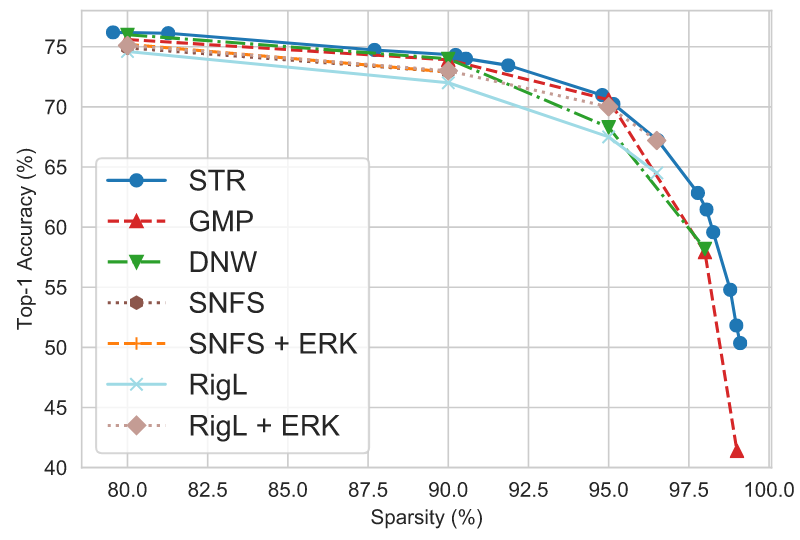
We introduce a new strategy for pruning neural networks based off of the soft threshold reparametrization technique from signal processing. The layerwise sparsity budgets allow for very sparse but sti... ll highly performant trained models across a variety of architectures and tasks.
Training a neural network is synonymous with learning the values of the weights. In contrast, we demonstrate that randomly weighted neural networks contain subnetworks which achieve impressive perform... ance without ever modifying the weight values. Hidden in a randomly weighted Wide ResNet-50 we find a subnetwork (with random weights) that is smaller than, but matches the performance of a ResNet-34 trained on ImageNet. Not only do these 'untrained subnetworks' exist, but we provide an algorithm to effectively find them. We empirically show that as randomly weighted neural networks with fixed weights grow wider and deeper, an 'untrained subnetwork' approaches a network with learned weights in accuracy. Our code and pretrained models are available at: https://github.com/allenai/hidden-networks.
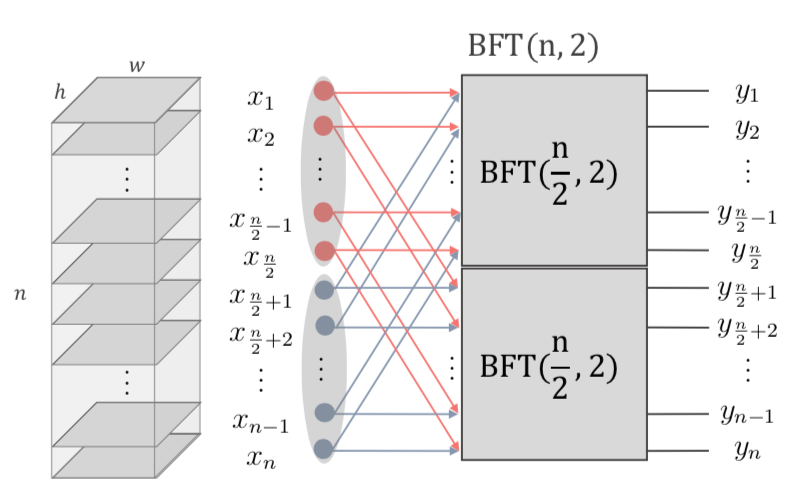
In this paper, we show that extending the butterfly operations from the FFT algorithm to a general Butterfly Transform (BFT) can be beneficial in building an efficient blockstructure for CNN designs.... Pointwise convolutions, which we refer to as channel fusions, are the main computational bottleneck in the state-of-the-art efficient CNNs (e.g. MobileNets [15,38,14]). We introduce a set of criterion for channel fusion, and prove that BFT yields an asymptotically optimal FLOP count with respect to these criteria. By replacing pointwise convolutions with BFT, we reduce the computational complexity of these layers from O(n^2) to O(n log n) with respect to the number of channels. Our experimental evaluations show that our method results in significant accuracy gains across a wide range of network architectures, especially at low FLOP ranges. For example, BFT results in up to a 6.75% absolute Top-1 improvement for MobileNetV1[15], 4.4% for ShuffleNet V2[28] and 5.4% for MobileNetV3[14] on ImageNet under a similar numberof FLOPS. Notably, ShuffleNet-V2+BFT outperforms state-of-the-art architecture search methods MNasNet[43], FBNet[46] and MobilenetV3[14] in the low FLOP regime.
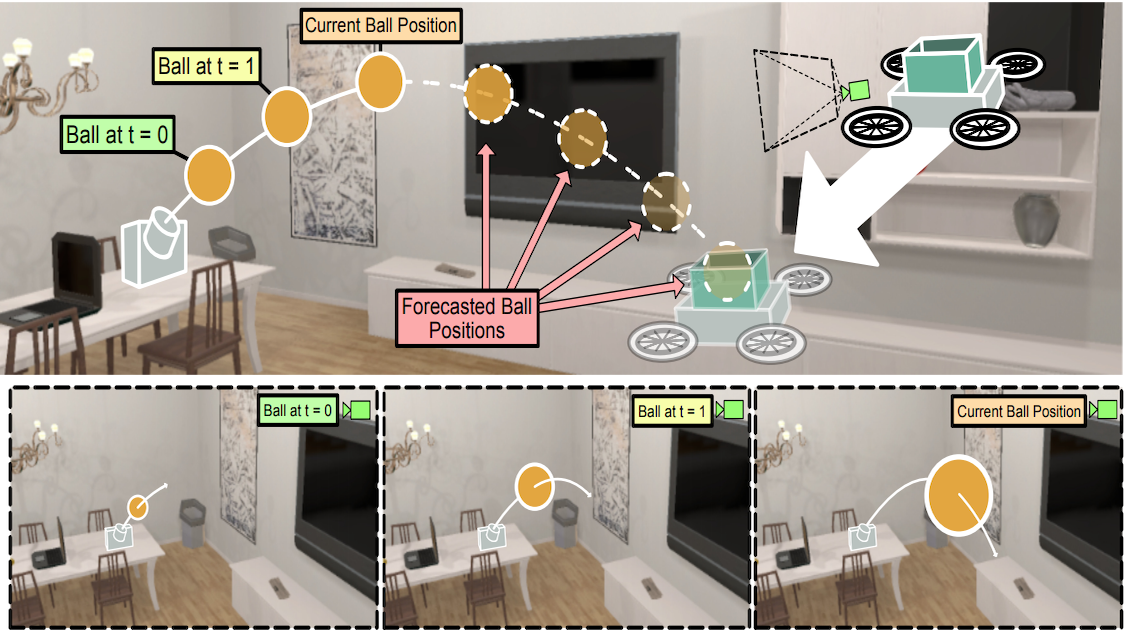
In this paper we address the problem of visual reaction: the task of interacting with dynamic environments where the changes in the environment are not necessarily caused by the agents itself. Visual... reaction entails predicting the future changes in a visual environment and planning accordingly. We study the problem of visual reaction in the context of playing catch with a drone in visually rich synthetic environments. This is a challenging problem since the agent is required to learn (1) how objects with different physical properties and shapes move, (2) what sequence of actions should be taken according to the prediction, (3) how to adjust the actions based on the visual feedback from the dynamic environment (e.g., when objects bouncing off a wall), and (4) how to reason and act with an unexpected state change in a timely manner. We propose a new dataset for this task, which includes 30K throws of 20 types of objects in different directions with different forces. Our results show that our model that integrates a forecaster with a planner outperforms a set of strong baselines that are based on tracking as well as pure model-based and model-free RL baselines.

We present ALFRED (Action Learning From Realistic Environments and Directives), a benchmark for learning a mapping from natural language instructions and egocentric vision to sequences of actions for... household tasks. ALFRED includes long, compositional tasks with nonreversible state changes to shrink the gap between research benchmarks and real-world applications. ALFRED consists of expert demonstrations in interactive visual environments for 25k natural language directives. These directives contain both high-level goals like “Rinse off a mug and place it in the coffee maker.” and low-level language instructions like “Walk to the coffee maker on the right.” ALFRED tasks are more complex in terms of sequence length, action space, and language than existing visionand-language task datasets. We show that a baseline model based on recent embodied vision-and-language tasks performs poorly on ALFRED, suggesting that there is significant room for developing innovative grounded visual language understanding models with this benchmark.

Visual recognition ecosystems (e.g. ImageNet, Pascal, MSCOCO) have undeniably played a prevailing role in the evolution of modern computer vision. We argue that interactive and embodied visual AI has... reached a stage of development similar to visual recognition prior to the advent of these ecosystems. Recently, various synthetic environments have been introduced to facilitate research in embodied AI. Notwithstanding this progress, the crucial question of how well models trained in simulation generalize to reality has remained largely unanswered. The creation of a comparable ecosystem for simulation-to-real embodied AI presentsmany challenges: (1) the inherently interactive nature of the problem, (2) the need for tight alignments between real and simulated worlds, (3) the difficulty of replicating physical conditions for repeatable experiments, (4) and the associated cost. In this paper we introduce RoboTHOR to democratise research in interactive and embodied visual AI. RoboTHOR offers a framework of simulated environments paired with physical counterparts to systematically exploreand overcome the challenges of simulation-to-real transfer, and a platform where researchers across the globe can test their embodied models over IP. As a first benchmark, our experiments show that there exists a significant gap between the performance of models trained in simulation when they are tested in both simulations and their carefully constructed physical analogues. We hope that RoboTHOR will spur the next stage of evolution in embodied computer vision.
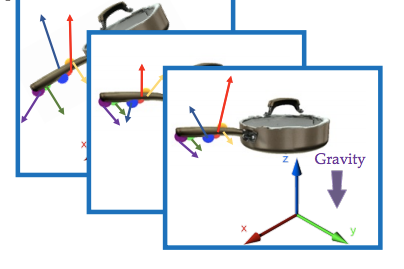
When we humans look at a video of human-object interaction, we can not only infer what is happening but we can even extract actionable information and imitate those interactions. On the other hand, cu... rrent recognition or geometric approaches lack the physicality of action representation. In this paper, we take a step towards a more physical understanding of actions. We address the problem of inferring contact points and the physical forces from videos of humans interacting with objects. One of the main challenges in tackling this problem is obtaining ground-truth labels for forces. We sidestep this problem by instead using a physics simulator for supervision. Specifically, we use a simulator to predict effects and enforce that estimated forces must lead to the same effect as depicted in the video. Our quantitative and qualitative results show that (a) we can predict meaningful forces from videos whose effects lead to accurate imitation of the motions observed, (b) by jointly optimizing for contact point and force prediction, we can improve the performance on both tasks in comparison to independent training, and (c) we can learn a representation from this model that generalizes to novel objects using few shot
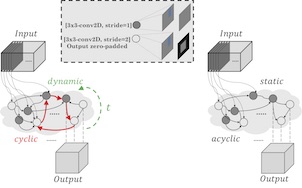
The success of neural networks has driven a shift in focus from feature engineering to architecture engineering. However, successful networks today are constructed using a small and manually defined s... et of building blocks. Even in methods of neural architecture search (NAS) the network connectivity patterns are largely constrained. In this work we propose a method for discovering neural wirings. We relax the typical notion of layers and instead enable channels to form connections independent of each other. This allows for a much larger space of possible networks. The wiring of our network is not fixed during training – as we learn the network parameters we also learn the structure itself. Our experiments demonstrate that our learned connectivity outperforms hand engineered and randomly wired networks. By learning the connectivity of MobileNetV1 [11] we boost the ImageNet accuracy by 10% at ∼ 41M FLOPs. Moreover, we show that our method generalizes to recurrent and continuous time networks and may be used to effectively discover sparse neural networks in a single training run. Code and pretrained models are available at https://github.com/allenai/dnw.
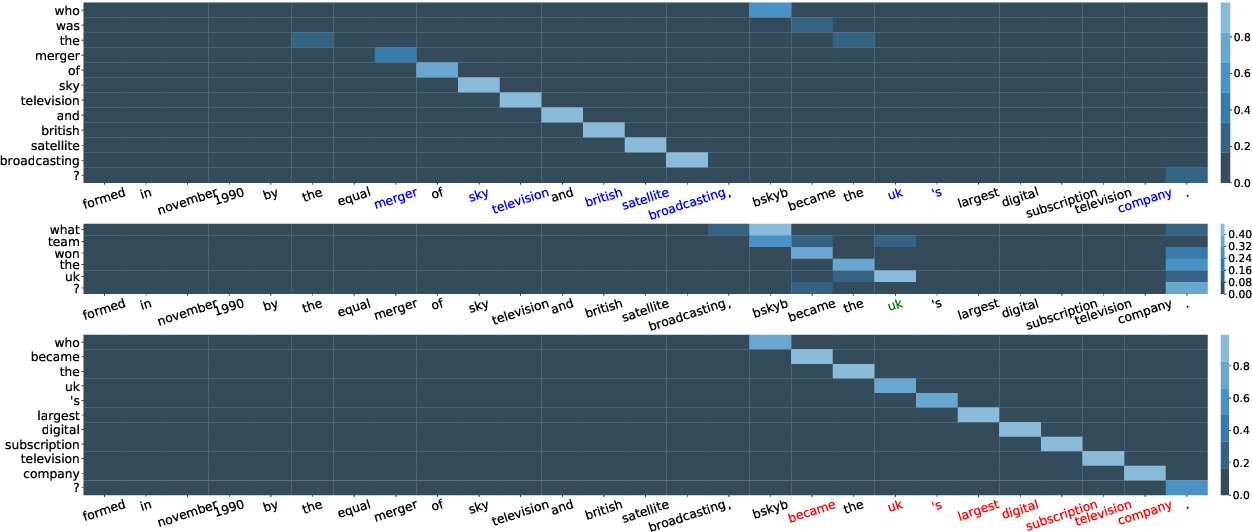
Generating diverse sequences is important in many NLP applications such as question generation or summarization that exhibit semantically one-to-many relationships between source and the target sequen... ces. We present a method to explicitly separate diversification from generation using a general plug-and-play module (called SELECTOR) that wraps around and guides an existing encoder-decoder model. The diversification stage uses a mixture of experts to sample different binary masks on the source sequence for diverse content selection. The generation stage uses a standard encoder-decoder model given each selected content from the source sequence. Due to the non-differentiable nature of discrete sampling and the lack of ground truth labels for binary mask, we leverage a proxy for ground-truth mask and adopt stochastic hard-EM for training. In question generation (SQuAD) and abstractive summarization (CNN-DM), our method demonstrates significant improvements in accuracy, diversity and training efficiency, including state-of-the-art top-1 accuracy in both datasets, 6% gain in top-5 accuracy, and 3.7 times faster training over a state-of-the-art model. Our code is publicly available at https://github.com/ clovaai/FocusSeq2Seq.
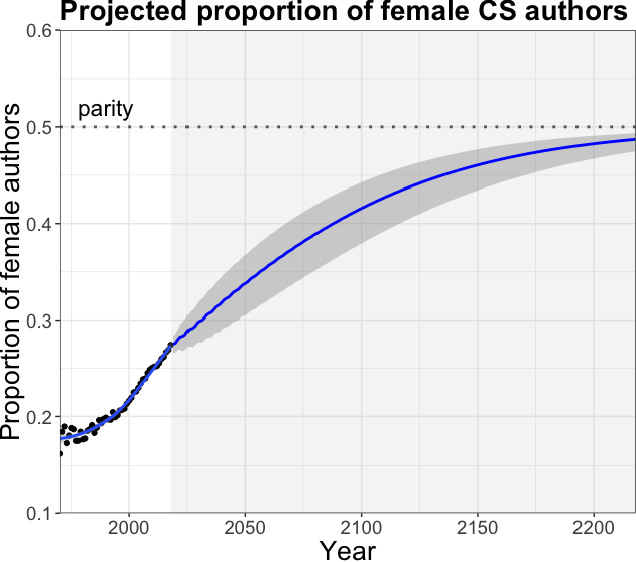
A comprehensive and up-to-date analysis of Computer Science literature (2.87 million papers through 2018) reveals that, if current trends continue, parity between the number of male and female authors... will not be reached in this century. Under our most optimistic projection models, gender parity is forecast to be reached by 2100, and significantly later under more realistic assumptions. In contrast, parity is projected to be reached within two to three decades in the biomedical literature. Finally, our analysis of collaboration trends in Computer Science reveals decreasing rates of collaboration between authors of different genders.
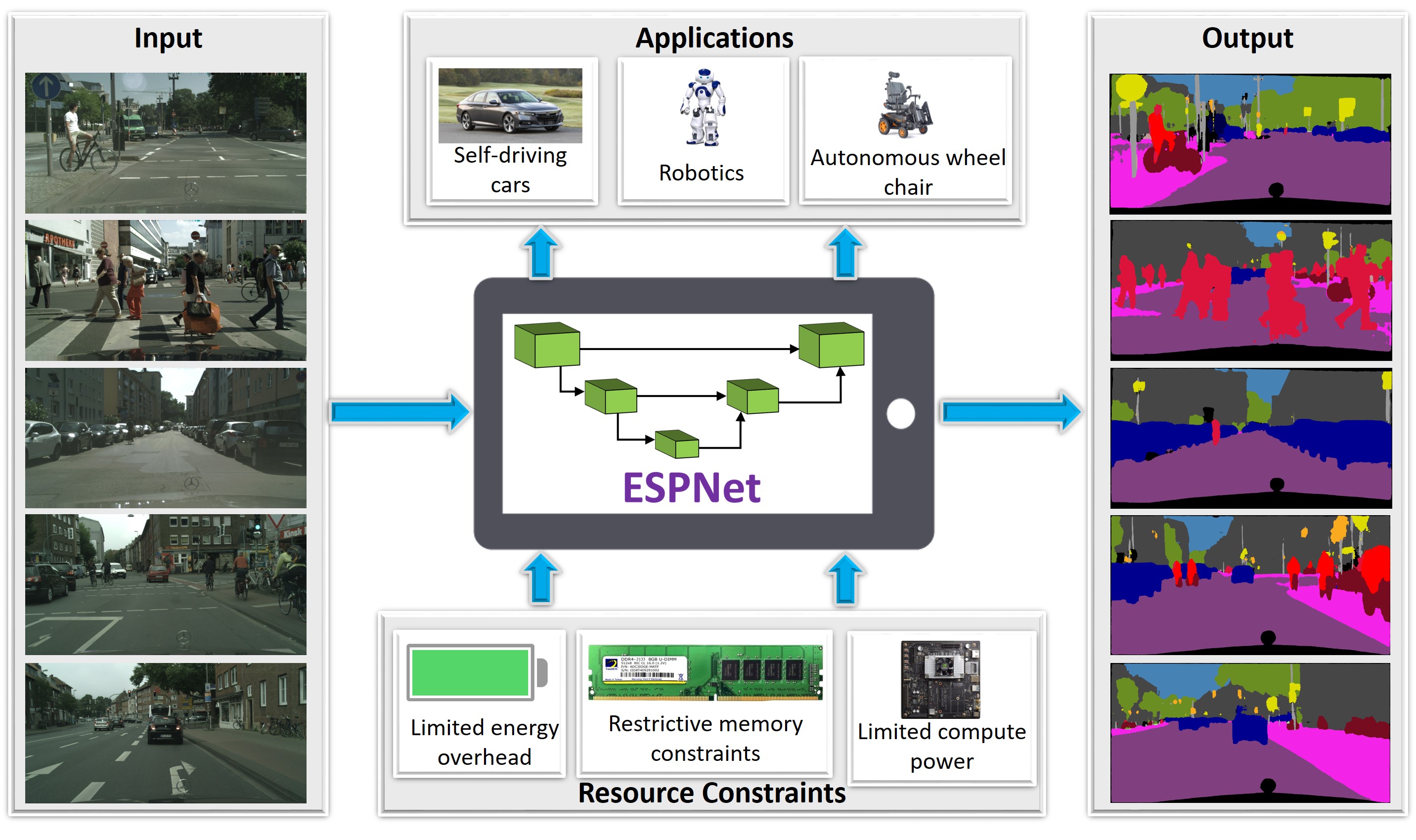
We introduce a light-weight, power efficient, and general purpose convolutional neural network, ESPNetv2, for modeling visual and sequential data. Our network uses group point-wise and depth-wise dila... ted separable convolutions to learn representations from a large effective receptive field with fewer FLOPs and parameters. The performance of our network is evaluated on four different tasks: (1) object classification, (2) semantic segmentation, (3) object detection, and (4) language modeling. Experiments on these tasks, including image classification on the ImageNet and language modeling on the PenTree bank dataset, demonstrate the superior performance of our method over the state-of-the-art methods. Our network outperforms ESPNet by 4-5% and has 2-4x fewer FLOPs on the PASCAL VOC and the Cityscapes dataset. Compared to YOLOv2 on the MS-COCO object detection, ESPNetv2 delivers 4.4% higher accuracy with 6x fewer FLOPs. Our experiments show that ESPNetv2 is much more power efficient than existing state-of-the-art efficient methods including ShuffleNets and MobileNets. Our code is open-source and available at https://github.com/sacmehta/ESPNetv2.
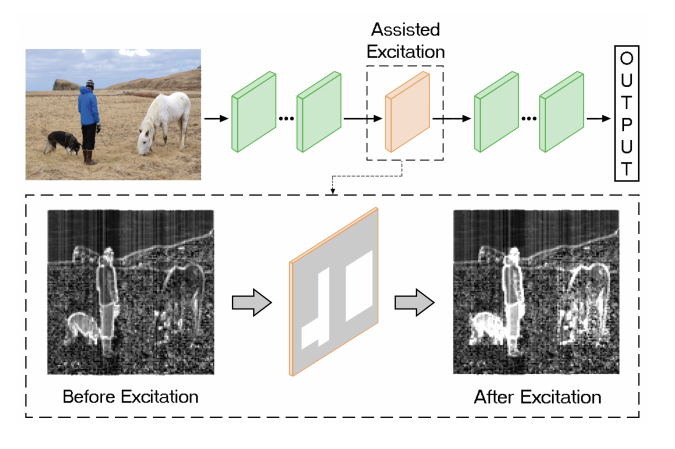
We present a simple and effective learning technique that significantly improves mAP of YOLO object detectors without compromising their speed. During network training, we carefully feed in localizati... on information. We excite certain activations in order to help the network learn to better localize. In the later stages of training, we gradually reduce our assisted excitation to zero. We reached a new state-of-the-art in the speed-accuracy trade-off. Our technique improves the mAP of YOLOv2 by 3.8% and mAP of YOLOv3 by 2.2% on MSCOCO dataset. This technique is inspired from curriculum learning. It is simple and effective and it is applicable to most single-stage object detectors.

Visual Question Answering (VQA) in its ideal form lets us study reasoning in the joint space of vision and language and serves as a proxy for the AI task of scene understanding. However, most VQA benc... hmarks to date are focused on questions such as simple counting, visual attributes, and object detection that do not require reasoning or knowledge beyond what is in the image. In this paper, we address the task of knowledge-based visual question answering and provide a benchmark, called OK-VQA, where the image content is not sufficient to answer the questions, encouraging methods that rely on external knowledge resources. Our new dataset includes more than 14,000 questions that require external knowledge to answer. We show that the performance of the state-of-the-art VQA models degrades drastically in this new setting. Our analysis shows that our knowledge-based VQA task is diverse, difficult, and large compared to previous knowledge-based VQA datasets. We hope that this dataset enables researchers to open up new avenues for research in this domain.
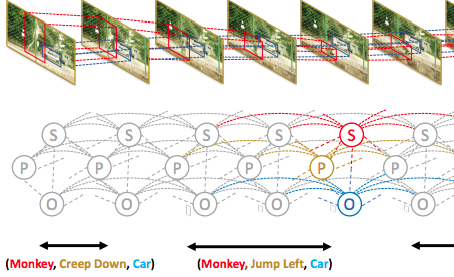
Visual relationship reasoning is a crucial yet challenging task for understanding rich interactions across visual concepts. For example, a relationship {man, open, door} involves a complex relation {o... pen} between concrete entities {man, door}. While much of the existing work has studied this problem in the context of still images, understanding visual relationships in videos has received limited attention. Due to their temporal nature, videos enable us to model and reason about a more comprehensive set of visual relationships, such as those requiring multiple (temporal) observations (e.g., {man, lift up, box} vs. {man, put down, box}), as well as relationships that are often correlated through time (e.g., {woman, pay, money} followed by {woman, buy, coffee}). In this paper, we construct a Conditional Random Field on a fully-connected spatio-temporal graph that exploits the statistical dependency between relational entities spatially and temporally. We introduce a novel gated energy function parametrization that learns adaptive relations conditioned on visual observations. Our model optimization is computationally efficient, and its space computation complexity is significantly amortized through our proposed parameterization. Experimental results on benchmark video datasets (ImageNet Video and Charades) demonstrate state-of-the-art performance across three standard relationship reasoning tasks: Detection, Tagging, and Recognition.
Visual understanding goes well beyond object recognition. With one glance at an image, we can effortlessly imagine the world beyond the pixels: for instance, we can infer people’s actions, goals, and... mental states. While this task is easy for humans, it is tremendously difficult for today’s vision systems, requiring higher-order cognition and commonsense reasoning about the world. In this paper, we formalize this task as Visual Commonsense Reasoning. In addition to answering challenging visual questions expressed in natural language, a model must provide a rationale explaining why its answer is true. We introduce a new dataset, VCR, consisting of 290k multiple choice QA problems derived from 110k movie scenes. The key recipe to generating non-trivial and high-quality problems at scale is Adversarial Matching, a new approach to transform rich annotations into multiple choice questions with minimal bias. To move towards cognition-level image understanding, we present a new reasoning engine, called Recognition to Cognition Networks (R2C), that models the necessary layered inferences for grounding, contextualization, and reasoning. Experimental results show that while humans find VCR easy (over 90% accuracy), state-of-theart models struggle (∼45%). Our R2C helps narrow this gap (∼65%); still, the challenge is far from solved, and we provide analysis that suggests avenues for future work.

Learning is an inherently continuous phenomenon. When humans learn a new task there is no explicit distinction between training and inference. As we learn a task, we keep learning about it while perfo... rming the task. What we learn and how we learn it varies during different stages of learning. Learning how to learn and adapt is a key property that enables us to generalize effortlessly to new settings. This is in contrast with conventional settings in machine learning where a trained model is frozen during inference. In this paper we study the problem of learning to learn at both training and test time in the context of visual navigation. A fundamental challenge in navigation is generalization to unseen scenes. In this paper we propose a self-adaptive visual navigation method (SAVN) which learns to adapt to new environments without any explicit supervision. Our solution is a meta-reinforcement learning approach where an agent learns a self-supervised interaction loss that encourages effective navigation. Our experiments, performed in the AI2-THOR framework, show major improvements in both success rate and SPL for visual navigation in novel scenes. Our code and data are available at: https://github.com/allenai/savn.

Scale variation has been a challenge from traditional to modern approaches in computer vision. Most solutions to scale issues have a similar theme: a set of intuitive and manually designed policies th... at are generic and fixed (e.g. SIFT or feature pyramid). We argue that the scaling policy should be learned from data. In this paper, we introduce ELASTIC, a simple, efficient and yet very effective approach to learn a dynamic scale policy from data. We formulate the scaling policy as a non-linear function inside the network's structure that (a) is learned from data, (b) is instance specific, (c) does not add extra computation, and (d) can be applied on any network architecture. We applied ELASTIC to several state-of-the-art network architectures and showed consistent improvement without extra (sometimes even lower) computation on ImageNet classification, MSCOCO multi-label classification, and PASCAL VOC semantic segmentation. Our results show major improvement for images with scale challenges. Our code is available here: https://github.com/allenai/elastic
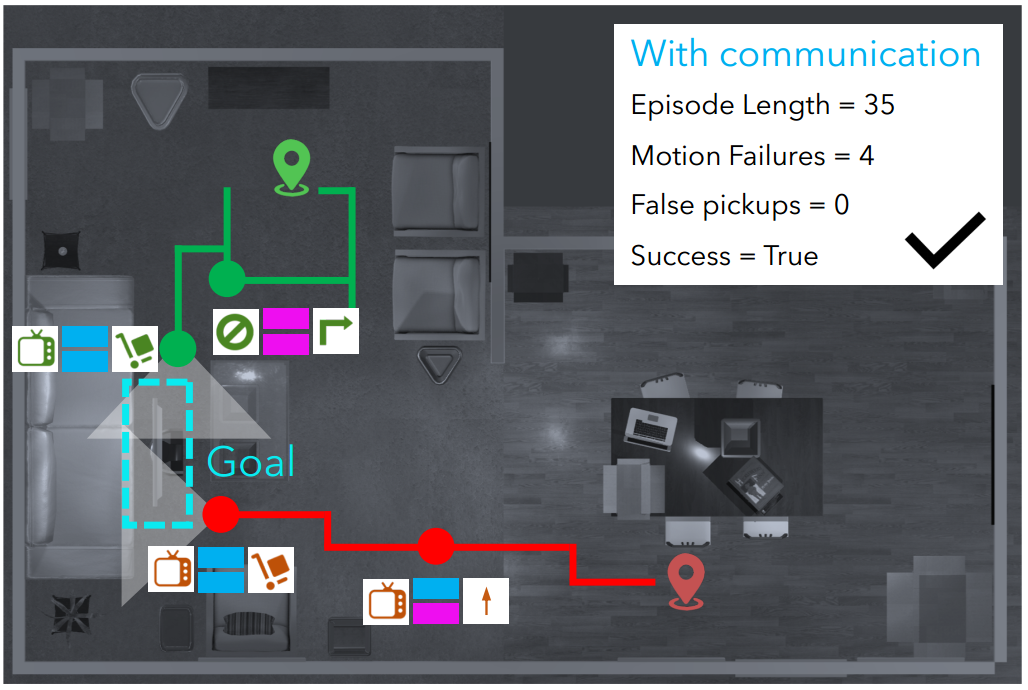
Collaboration is a necessary skill to perform tasks that are beyond one agent's capabilities. Addressed extensively in both conventional and modern AI, multi-agent collaboration has often been studied... in the context of simple grid worlds. We argue that there are inherently visual aspects to collaboration which should be studied in visually rich environments. A key element in collaboration is communication that can be either explicit, through messages, or implicit, through perception of the other agents and the visual world. Learning to collaborate in a visual environment entails learning (1) to perform the task, (2) when and what to communicate, and (3) how to act based on these communications and the perception of the visual world. In this paper we study the problem of learning to collaborate directly from pixels in AI2-THOR and demonstrate the benefits of explicit and implicit modes of communication to perform visual tasks.
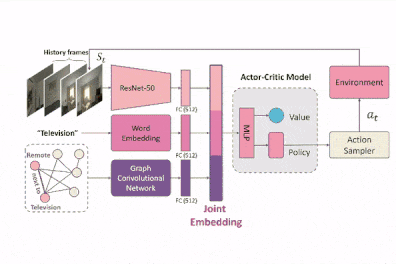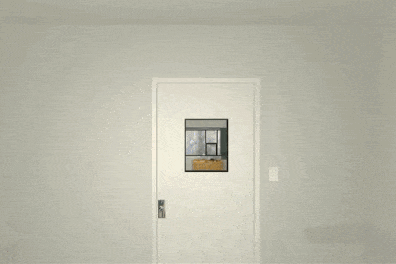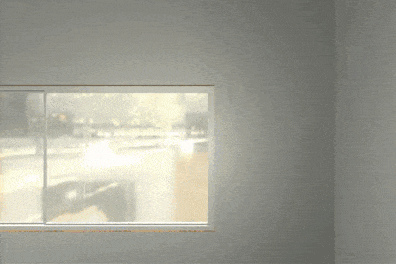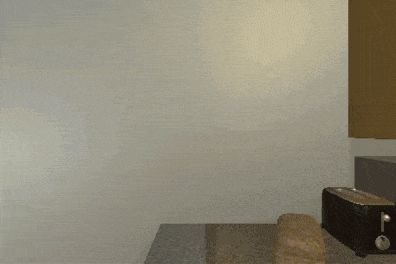
How do humans navigate to target objects in novel scenes? Do we use the semantic/functional priors we have built over years to efficiently search and navigate? For example, to search for mugs, we sear... ch cabinets near the coffee machine and for fruits we try the fridge. In this work, we focus on incorporating semantic priors in the task of semantic navigation. We propose to use Graph Convolutional Networks for incorporating the prior knowledge into a deep reinforcement learning framework. The agent uses the features from the knowledge graph to predict the actions. For evaluation, we use the AI2-THOR framework. Our experiments show how semantic knowledge improves performance significantly. More importantly, we show improvement in generalization to unseen scenes and/or objects.

We introduce a fast and efficient convolutional neural network, ESPNet, for semantic segmentation of high resolution images under resource constraints. ESPNet is based on a new convolutional module, e... fficient spatial pyramid (ESP), which is efficient in terms of computation, memory, and power. ESPNet is 22 times faster (on a standard GPU) and 180 times smaller than the stateof-the-art semantic segmentation network PSPNet [1], while its category-wise accuracy is only 8% less. We evaluated EPSNet on a variety of semantic segmentation datasets including Cityscapes, PASCAL VOC, and a breast biopsy whole slide image dataset. Under the same constraints on memory and computation, ESPNet outperforms all the current efficient CNN networks such as MobileNet, ShuffleNet, and ENet on both standard metrics and our newly introduced performance metrics that measure efficiency on edge devices. Our network can process high resolution images at a rate of 112 and 9 frames per second on a standard GPU and edge device, respectively.
We propose the idea of transferring common-sense knowledge from source categories to target categories for scalable object detection. In our setting, the training data for the source categories have b... ounding box annotations, while those for the target categories only have image-level annotations. Current state-of-the-art approaches focus on image-level visual or semantic similarity to adapt a detector trained on the source categories to the new target categories. In contrast, our key idea is to (i) use similarity not at image-level, but rather at region-level, as well as (ii) leverage richer common-sense (based on attribute, spatial, etc.,) to guide the algorithm towards learning the correct detections. We acquire such common-sense cues automatically from readily-available knowledge bases without any extra human effort. On the challenging MS COCO dataset, we find that using common-sense knowledge substantially improves detection performance over existing transfer-learning baselines.

Imagining a scene described in natural language with realistic layout and appearance of entities is the ultimate test of spatial, visual, and semantic world knowledge. Towards this goal, we present th... e Composition, Retrieval, and Fusion Network (CRAFT), a model capable of learning this knowledge from video-caption data and applying it while generating videos from novel captions. CRAFT explicitly predicts a temporal-layout of mentioned entities (characters and objects), retrieves spatio-temporal entity segments from a video database and fuses them to generate scene videos. Our contributions include sequential training of components of CRAFT while jointly modeling layout and appearances, and losses that encourage learning compositional representations for retrieval. We evaluate CRAFT on semantic fidelity to caption, composition consistency, and visual quality. CRAFT outperforms direct pixel generation approaches and generalizes well to unseen captions and to unseen video databases with no text annotations. We demonstrate CRAFT on FLINTSTONES, a new richly annotated video-caption dataset with over 25000 videos. For a glimpse of videos generated by Craft, see https://youtu.be/688Vv86n0z8.

We study the task of directly modelling a visually intelligent agent. Computer vision typically focuses on solving various subtasks related to visual intelligence. We depart from this standard approac... h to computer vision; instead we directly model a visually intelligent agent. Our model takes visual information as input and directly predicts the actions of the agent. Toward this end we introduce DECADE, a dataset of ego-centric videos from a dog’s perspective as well as her corresponding movements. Using this data we model how the dog acts and how the dog plans her movements. We show under a variety of metrics that given just visual input we can successfully model this intelligent agent in many situations. Moreover, the representation learned by our model encodes distinct information compared to representations trained on image classification, and our learned representation can generalize to other domains. In particular, we show strong results on the task of walkable surface estimation and scene classification by using this dog modelling task as representation learning.

We introduce Interactive Question Answering (IQA), the task of answering questions that require an autonomous agent to interact with a dynamic visual environment. IQA presents the agent with a scene a... nd a question, like: “Are there any apples in the fridge?” The agent must navigate around the scene, acquire visual understanding of scene elements, interact with objects (e.g. open refrigerators) and plan for a series of actions conditioned on the question. Popular reinforcement learning approaches with a single controller perform poorly on IQA owing to the large and diverse state space. We propose the Hierarchical Interactive Memory Network (HIMN), consisting of a factorized set of controllers, allowing the system to operate at multiple levels of temporal abstraction, reducing the diversity of the action space available to each controller and enabling an easier training paradigm. We introduce IQADATA, a new Interactive Question Answering dataset built upon AI2-THOR, a simulated photo-realistic environment of configurable indoor scenes [95] with interactive objects. IQADATA has 75,000 questions, each paired with a unique scene configuration. Our experiments show that our proposed model outperforms popular single controller based methods on IQADATA. For sample questions and results, please view our video: https://youtu.be/ pXd3C-1jr98.
Diagrams often depict complex phenomena and serve as a good test bed for visual and textual reasoning. However, understanding diagrams using natural image understanding approaches requires large train... ing datasets of diagrams, which are very hard to obtain. Instead, this can be addressed as a matching problem either between labeled diagrams, images or both. This problem is very challenging since the absence of significant color and texture renders local cues ambiguous and requires global reasoning. We consider the problem of one-shot part labeling: labeling multiple parts of an object in a target image given only a single source image of that category. For this set-to-set matching problem, we introduce the Structured Set Matching Network (SSMN), a structured prediction model that incorporates convolutional neural networks. The SSMN is trained using global normalization to maximize local match scores between corresponding elements and a global consistency score among all matched elements, while also enforcing a matching constraint between the two sets. The SSMN significantly outperforms several strong baselines on three label transfer scenarios: diagram-to-diagram, evaluated on a new diagram dataset of over 200 categories; image-toimage, evaluated on a dataset built on top of the Pascal Part Dataset; and image-to-diagram, evaluated on transferring labels across these datasets.

Objects often occlude each other in scenes; Inferring their appearance beyond their visible parts plays an important role in scene understanding, depth estimation, object interaction and manipulation.... In this paper, we study the challenging problem of completing the appearance of occluded objects. Doing so requires knowing which pixels to paint (segmenting the invisible parts of objects) and what color to paint them (generating the invisible parts). Our proposed novel solution, SeGAN, jointly optimizes for both segmentation and generation of the invisible parts of objects. Our experimental results show that: (a) SeGAN can learn to generate the appearance of the occluded parts of objects; (b) SeGAN outperforms state-of-the-art segmentation baselines for the invisible parts of objects; (c) trained on synthetic photo realistic images, SeGAN can reliably segment natural images; (d) by reasoning about occluderoccludee relations, our method can infer depth layering.

We investigate the problem of producing structured graph representations of visual scenes. Our work analyzes the role of motifs: regularly appearing substructures in scene graphs. We present new quant... itative insights on such repeated structures in the Visual Genome dataset. Our analysis shows that object labels are highly predictive of relation labels but not vice-versa. We also find there are recurring patterns even in larger subgraphs: more than 50% of graphs contain motifs involving at least two relations. This analysis leads to a new baseline that is simple, yet strikingly powerful. While hardly considering the overall visual context of an image, it outperforms previous approaches. We then introduce Stacked Motif Networks, a new architecture for encoding global context that is crucial for capturing higher order motifs in scene graphs. Our best model for scene graph detection achieves a 7.3% absolute improvement in recall@50 (41% relative gain) over prior state-of-the-art.
A number of studies have found that today’s Visual Question Answering (VQA) models are heavily driven by superficial correlations in the training data and lack sufficient image grounding. To encourage... development of models geared towards the latter, we propose a new setting for VQA where for every question type, train and test sets have different prior distributions of answers. Specifically, we present new splits of the VQA v1 and VQA v2 datasets, which we call Visual Question Answering under Changing Priors (VQACP v1 and VQA-CP v2 respectively). First, we evaluate several existing VQA models under this new setting and show that their performance degrades significantly compared to the original VQA setting. Second, we propose a novel Grounded Visual Question Answering model (GVQA) that contains inductive biases and restrictions in the architecture specifically designed to prevent the model from ‘cheating’ by primarily relying on priors in the training data. Specifically, GVQA explicitly disentangles the recognition of visual concepts present in the image from the identification of plausible answer space for a given question, enabling the model to more robustly generalize across different distributions of answers. GVQA is built off an existing VQA model – Stacked Attention Networks (SAN). Our experiments demonstrate that GVQA significantly outperforms SAN on both VQA-CP v1 and VQA-CP v2 datasets. Interestingly, it also outperforms more powerful VQA models such as Multimodal Compact Bilinear Pooling (MCB) in several cases. GVQA offers strengths complementary to SAN when trained and evaluated on the original VQA v1 and VQA v2 datasets. Finally, GVQA is more transparent and interpretable than existing VQA models.

Several theories in cognitive neuroscience suggest that when people interact with the world, or simulate interactions, they do so from a first-person egocentric perspective, and seamlessly transfer kn... owledge between third-person (observer) and first-person (actor). Despite this, learning such models for human action recognition has not been achievable due to the lack of data. This paper takes a step in this direction, with the introduction of Charades-Ego, a large-scale dataset of paired first-person and third-person videos, involving 112 people, with 4000 paired videos. This enables learning the link between the two, actor and observer perspectives. Thereby, we address one of the biggest bottlenecks facing egocentric vision research, providing a link from first-person to the abundant third-person data on the web. We use this data to learn a joint representation of first and third-person videos, with only weak supervision, and show its effectiveness for transferring knowledge from the third-person to the first-person domain.
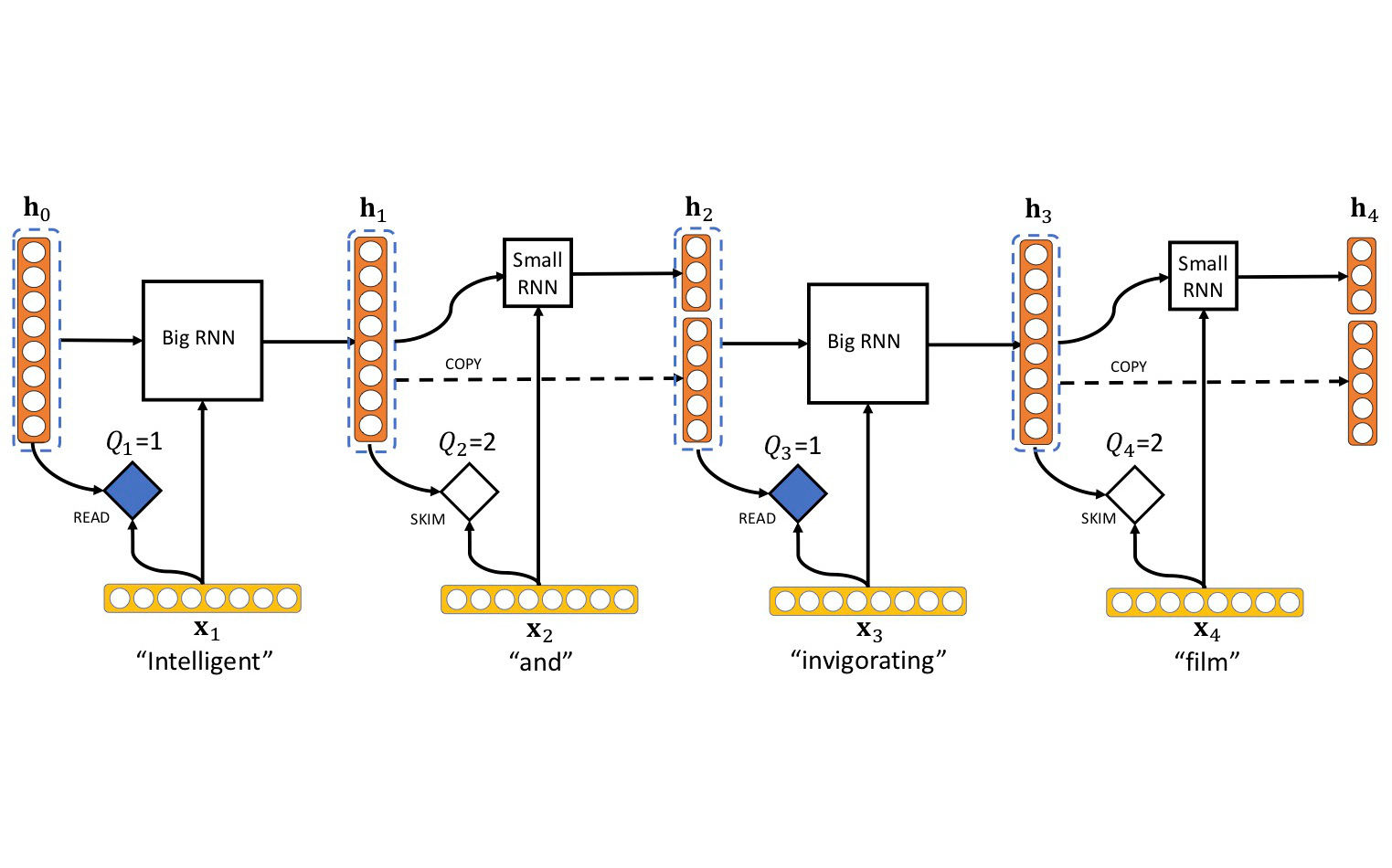
Inspired by the principles of speed reading, we introduce Skim-RNN, a recurrent neural network (RNN) that dynamically decides to update only a small fraction of the hidden state for relatively unimpor... tant input tokens. Skim-RNN gives computational advantage over an RNN that always updates the entire hidden state. Skim-RNN uses the same input and output interfaces as a standard RNN and can be easily used instead of RNNs in existing models. In our experiments, we show that Skim-RNN can achieve significantly reduced computational cost without losing accuracy compared to standard RNNs across five different natural language tasks. In addition, we demonstrate that the trade-off between accuracy and speed of Skim-RNN can be dynamically controlled during inference time in a stable manner. Our analysis also shows that Skim-RNN running on a single CPU offers lower latency compared to standard RNNs on GPUs.
Robust object tracking requires knowledge and understanding of the object being tracked: its appearance, its motion, and how it changes over time. A tracker must be able to modify its underlying model... and adapt to new observations. We present Re3, a real-time deep object tracker capable of incorporating temporal information into its model. Rather than focusing on a limited set of objects or training a model at test-time to track a specific instance, we pretrain our generic tracker on a large variety of objects and efficiently update on the fly; Re3 simultaneously tracks and updates the appearance model with a single forward pass. This lightweight model is capable of tracking objects at 150 FPS, while attaining competitive results on challenging benchmarks. We also show that our method handles temporary occlusion better than other comparable trackers using experiments that directly measure performance on sequences with occlusion.
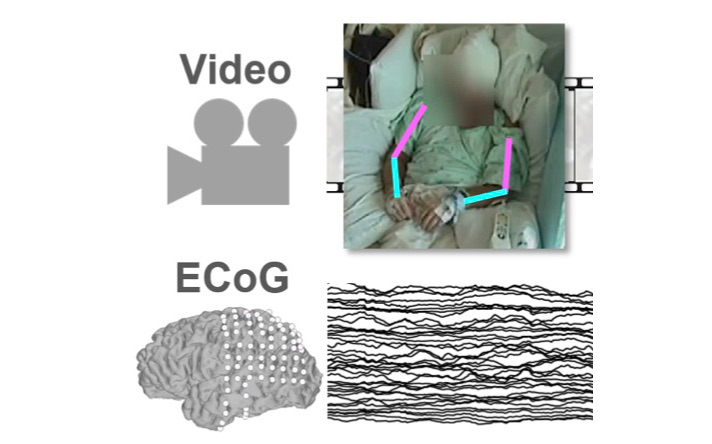
Developing useful interfaces between brains and machines is a grand challenge of neuroengineering. An effective interface has the capacity to not only interpret neural signals, but predict the intenti... ons of the human to perform an action in the near future; prediction is made even more challenging outside well-controlled laboratory experiments. This paper describes our approach to detect and to predict natural human arm movements in the future, a key challenge in brain computer interfacing that has never before been attempted. We introduce the novel Annotated Joints in Long-term ECoG (AJILE) dataset; AJILE includes automatically annotated poses of 7 upper body joints for four human subjects over 670 total hours (more than 72 million frames), along with the corresponding simultaneously acquired intracranial neural recordings. The size and scope of AJILE greatly exceeds all previous datasets with movements and electrocorticography (ECoG), making it possible to take a deep learning approach to movement prediction. We propose a multimodal model that combines deep convolutional neural networks (CNN) with long short-term memory (LSTM) blocks, leveraging both ECoG and video modalities. We demonstrate that our models are able to detect movements and predict future movements up to 800 msec before movement initiation. Further, our multimodal movement prediction models exhibit resilience to simulated ablation of input neural signals. We believe a multimodal approach to natural neural decoding that takes context into account is critical in advancing bioelectronic technologies and human neuroscience.

We introduce The House Of inteRactions (THOR), a framework for visual AI research, available at http://ai2thor.allenai.org. AI2-THOR consists of near photo-realistic 3D indoor scenes, where AI agents... can navigate in the scenes and interact with objects to perform tasks. AI2-THOR enables research in many different domains including but not limited to deep reinforcement learning, imitation learning, learning by interaction, planning, visual question answering, unsupervised representation learning, object detection and segmentation, and learning models of cognition. The goal of AI2-THOR is to facilitate building visually intelligent models and push the research forward in this domain.

A crucial capability of real-world intelligent agents is their ability to plan a sequence of actions to achieve their goals in the visual world. In this work, we address the problem of visual semantic... planning: the task of predicting a sequence of actions from visual observations that transform a dynamic environment from an initial state to a goal state. Doing so entails knowledge about objects and their affordances, as well as actions and their preconditions and effects. We propose learning these through interacting with a visual and dynamic environment. Our proposed solution involves bootstrapping reinforcement learning with imitation learning. To ensure cross task generalization, we develop a deep predictive model based on successor representations. Our experimental results show near optimal results across a wide range of tasks in the challenging THOR environment.

Humans have rich understanding of liquid containers and their contents; for example, we can effortlessly pour water from a pitcher to a cup. Doing so requires estimating the volume of the cup, approxi... mating the amount of water in the pitcher, and predicting the behavior of water when we tilt the pitcher. Very little attention in computer vision has been made to liquids and their containers. In this paper, we study liquid containers and their contents, and propose methods to estimate the volume of containers, approximate the amount of liquid in them, and perform comparative volume estimations all from a single RGB image. Furthermore, we show the results of the proposed model for predicting the behavior of liquids inside containers when one tilts the containers. We also introduce a new dataset of Containers Of liQuid contEnt (COQE) that contains more than 5,000 images of 10,000 liquid containers in context labelled with volume, amount of content, bounding box annotation, and corresponding similar 3D CAD models.

We introduce YOLO9000, a state-of-the-art, real-time object detection system that can detect over 9000 object categories. First we propose various improvements to the YOLO detection method, both novel... and drawn from prior work. The improved model, YOLOv2, is state-of-the-art on standard detection tasks like PASCAL VOC and COCO. Using a novel, multi-scale training method the same YOLOv2 model can run at varying sizes, offering an easy tradeoff between speed and accuracy. At 67 FPS, YOLOv2 gets 76.8 mAP on VOC 2007. At 40 FPS, YOLOv2 gets 78.6 mAP, outperforming state-of-the-art methods like Faster RCNN with ResNet and SSD while still running significantly faster. Finally we propose a method to jointly train on object detection and classification. Using this method we train YOLO9000 simultaneously on the COCO detection dataset and the ImageNet classification dataset. Our joint training allows YOLO9000 to predict detections for object classes that don't have labelled detection data. We validate our approach on the ImageNet detection task. YOLO9000 gets 19.7 mAP on the ImageNet detection validation set despite only having detection data for 44 of the 200 classes. On the 156 classes not in COCO, YOLO9000 gets 16.0 mAP. YOLO9000 predicts detections for more than 9000 different object categories, all in real-time.
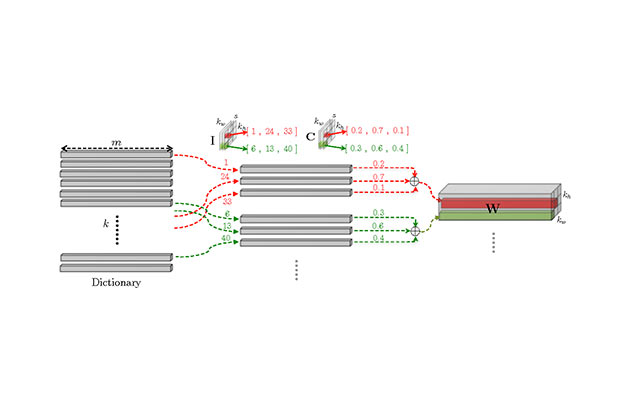
Porting state of the art deep learning algorithms to resource constrained compute platforms (e.g. VR, AR, wearables) is extremely challenging. We propose a fast, compact, and accurate model for convol... utional neural networks that enables efficient learning and inference. We introduce LCNN, a lookup-based convolutional neural network that encodes convolutions by few lookups to a dictionary that is trained to cover the space of weights in CNNs. Training LCNN involves jointly learning a dictionary and a small set of linear combinations. The size of the dictionary naturally traces a spectrum of trade-offs between efficiency and accuracy. Our experimental results on ImageNet challenge show that LCNN can offer 3.2x speedup while achieving2 55.1% top-1 accuracy using AlexNet architecture. Our fastest LCNN offers 37.6x speed up over AlexNet while6 maintaining 44.3% top-1 accuracy. LCNN not only offers dramatic speed ups at inference, but it also enables efficient training. In this paper, we show the benefits of LCNN in few-shot learning and few-iteration learning, two crucial aspects of on-device training of deep learning models.
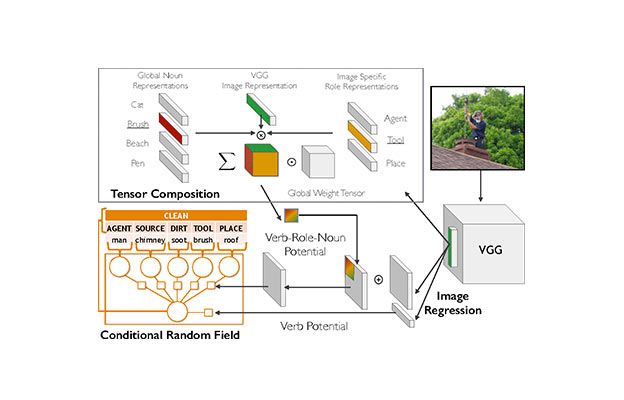
Semantic sparsity is a common challenge in structured visual classification problems; when the output space is complex, the vast majority of the possible predictions are rarely, if ever, seen in the t... raining set. This paper studies semantic sparsity in situation recognition, the task of producing structured summaries of what is happening in images, including activities, objects and the roles objects play within the activity. For this problem, we find empirically that most substructures required for prediction are rare, and current state-of-the-art model performance dramatically decreases if even one such rare substructure exists in the target output.We avoid many such errors by (1) introducing a novel tensor composition function that learns to share examples across substructures more effectively and (2) semantically augmenting our training data with automatically gathered examples of rarely observed outputs using web data. When integrated within a complete CRF-based structured prediction model, the tensor-based approach outperforms existing state of the art by a relative improvement of 2.11% and 4.40% on top-5 verb and noun-role accuracy, respectively. Adding 5 million images with our semantic augmentation techniques gives further relative improvements of 6.23% and 9.57% on top-5 verb and noun-role accuracy.
We introduce the task of Multi-Modal Machine Comprehension (M3C), which aims at answering multimodal questions given a context of text, diagrams and images. We present the Textbook Question Answering... (TQA) dataset that includes 1,076 lessons and 26,260 multi-modal questions, taken from middle school science curricula. Our analysis shows that a significant portion of questions require complex parsing of the text and the diagrams and reasoning, indicating that our dataset is more complex compared to previous machine comprehension and visual question answering datasets. We extend state-of-the-art methods for textual machine comprehension and visual question answering to the TQA dataset. Our experiments show that these models do not perform well on TQA. The presented dataset opens new challenges for research in question answering and reasoning across multiple modalities.
Actions are more than just movements and trajectories: we cook to eat and we hold a cup to drink from it. A thorough understanding of videos requires going beyond appearance modeling and necessitates... reasoning about the sequence of activities, as well as the higher-level constructs such as intentions. But how do we model and reason about these? We propose a fully-connected temporal CRF model for reasoning over various aspects of activities that includes objects, actions, and intentions, where the potentials are predicted by a deep network. End-to-end training of such structured models is a challenging endeavor: For inference and learning we need to construct mini-batches consisting of whole videos, leading to mini-batches with only a few videos. This causes high-correlation between data points leading to breakdown of the backprop algorithm. To address this challenge, we present an asynchronous variational inference method that allows efficient end-to-end training. Our method achieves a classification mAP of 22.4% on the Charades [42] benchmark, outperforming the state-of-the-art (17.2% mAP), and offers equal gains on the task of temporal localization.

Two less addressed issues of deep reinforcement learning are (1) lack of generalization capability to new goals, and (2) data inefficiency, i.e., the model requires several (and often costly) episodes... of trial and error to converge, which makes it impractical to be applied to real-world scenarios. In this paper, we address these two issues and apply our model to target-driven visual navigation. To address the first issue, we propose an actor-critic model whose policy is a function of the goal as well as the current state, which allows better generalization. To address the second issue, we propose the AI2-THOR framework, which provides an environment with high-quality 3D scenes and a physics engine. Our framework enables agents to take actions and interact with objects. Hence, we can collect a huge number of training samples efficiently. We show that our proposed method (1) converges faster than the state-of-the-art deep reinforcement learning methods, (2) generalizes across targets and scenes, (3) generalizes to a real robot scenario with a small amount of fine-tuning (although the model is trained in simulation), (4) is end-to-end trainable and does not need feature engineering, feature matching between frames or 3D reconstruction of the environment.

In this paper, we study the problem of question answering when reasoning over multiple facts is required. We propose Query-Reduction Network (QRN), a variant of Recurrent Neural Network (RNN) that eff... ectively handles both short-term (local) and long-term (global) sequential dependencies to reason over multiple facts. QRN considers the context sentences as a sequence of state-changing triggers, and reduces the original query to a more informed query as it observes each trigger (context sentence) through time. Our experiments show that QRN produces the state-of-the-art results in bAbI QA and dialog tasks, and in a real goal-oriented dialog dataset. In addition, QRN formulation allows parallelization on RNN's time axis, saving an order of magnitude in time complexity for training and inference.
Machine comprehension (MC), answering a query about a given context paragraph, requires modeling complex interactions between the context and the query. Recently, attention mechanisms have been succes... sfully extended to MC. Typically these methods use attention to focus on a small portion of the context and summarize it with a fixed-size vector, couple attentions temporally, and/or often form a uni-directional attention. In this paper we introduce the Bi-Directional Attention Flow (BIDAF) network, a multi-stage hierarchical process that represents the context at different levels of granularity and uses bi-directional attention flow mechanism to obtain a query-aware context representation without early summarization. Our experimental evaluations show that our model achieves the state-of-the-art results in Stanford Question Answering Dataset (SQuAD) and CNN/DailyMail cloze test.

We present a novel method to summarize unconstrained videos using salient montages (i.e., a “melange” of frames in the video as shown in Fig. 1), by finding “montageable moments” and identifying the s... alient people and actions to depict in each montage. Our method aims at addressing the increasing need for generating concise visualizations from the large number of videos being captured from portable devices. Our main contributions are (1) the process of finding salient people and moments to form a montage, and (2) the application of this method to videos taken “in the wild” where the camera moves freely. As such, we demonstrate results on head-mounted cameras, where the camera moves constantly, as well as on videos downloaded from YouTube. In our experiments, we show that our method can reliably detect and track humans under significant action and camera motion. Moreover, the predicted salient people are more accurate than results from state-of-the-art video salieny method [1] . Finally, we demonstrate that a novel “montageability” score can be used to retrieve results with relatively high precision which allows us to present high quality montages to users.
Due to the unprecedented growth of unedited videos, finding highlights relevant to a text query in a set of unedited videos has become increasingly important. We refer this task as semantic highlight... retrieval and propose a query-dependent video representation for retrieving a variety of highlights. Our method consists of two parts: 1) “viralets”, a mid-level representation bridging between semantic [Fig. 1(a)] and visual [Fig. 1(c)] spaces and 2) a novel Semantic-MODulation (SMOD) procedure to make viralets query-dependent (referred to as SMOD viralets). Given SMOD viralets, we train a single highlight ranker to predict the highlightness of clips with respect to a variety of queries (two examples in Fig. 1), whereas existing approaches can be applied only in a few predefined domains. Other than semantic highlight retrieval, viralets can also be used to associate relevant terms to each video. We utilize this property and propose a simple term prediction method based on nearest neighbor search. To conduct experiments, we collect a viral video dataset1 including users' comments, highlights, and/or original videos. Among a testing database with 1189 clips (13% highlights and 87% non-highlights), our highlight ranker achieves 41.2% recall at top-10 retrieved clips. It is significantly higher than the state-of-the-art domain-specific highlight ranker and its extension. Similarly, our method also outperforms all baseline methods on the publicly available video highlight dataset. Finally, our simple term prediction method utilizing viralets outperforms the state-of-the-art matrix factorization method (adapted from Kalayeh et al.). Viral videos refer to popular online videos. We focus on user-generated viral videos, which typically contain short highlight marked by users.
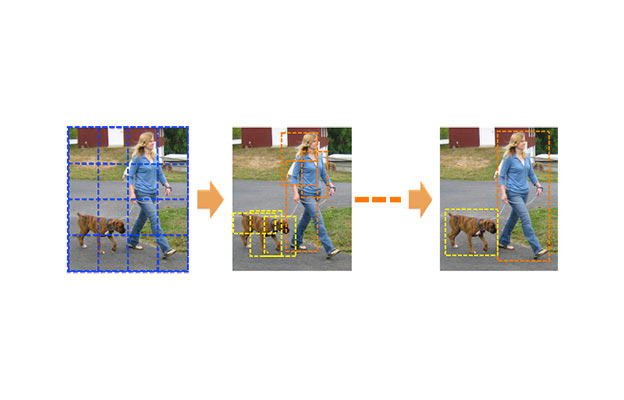
We introduce G-CNN, an object detection technique based on CNNs which works without proposal algorithms. G-CNN starts with a multi-scale grid of fixed bounding boxes. We train a regressor to move and... scale elements of the grid towards objects iteratively. G-CNN models the problem of object detection as finding a path from a fixed grid to boxes tightly surrounding the objects. G-CNN with around 180 boxes in a multi-scale grid performs comparably to Fast R-CNN which uses around 2K bounding boxes generated with a proposal technique. This strategy makes detection faster by removing the object proposal stage as well as reducing the number of boxes to be processed.
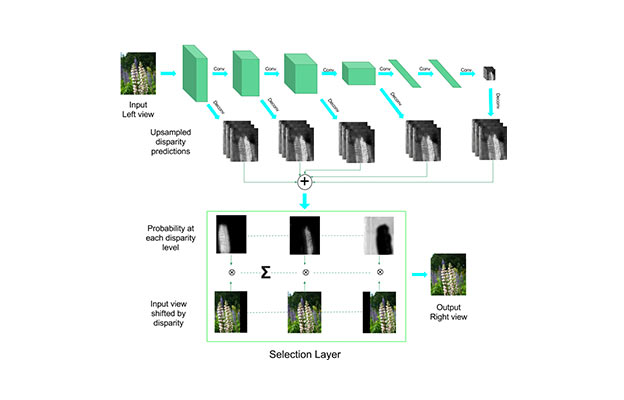
We propose Deep3D, a fully automatic 2D-to-3D conversion algorithm that takes 2D images or video frames as input and outputs stereo 3D image pairs. The stereo images can be viewed with 3D glasses or h... ead-mounted VR displays. Deep3D is trained directly on stereo pairs from a dataset of 3D movies to minimize the pixel-wise reconstruction error of the right view when given the left view. Internally, the Deep3D network estimates a probabilistic disparity map that is used by a differentiable depth image-based rendering layer to produce the right view. Thus Deep3D does not require collecting depth sensor data for supervision.
Which are the pedestrian detectors that yield a precision above 95% at 25% recall? Answering such a complex query involves identifying and analyzing the results reported in figures within several rese... arch papers. Despite the availability of excellent academic search engines, retrieving such information poses a cumbersome challenge today as these systems have primarily focused on understanding the text content of scholarly documents. In this paper, we introduce FigureSeer, an end-to-end framework for parsing result-figures, that enables powerful search and retrieval of results in research papers. Our proposed approach automatically localizes figures from research papers, classifies them, and analyses the content of the result-figures. The key challenge in analyzing the figure content is the extraction of the plotted data and its association with the legend entries. We address this challenge by formulating a novel graph-based reasoning approach using a CNN-based similarity metric. We present a thorough evaluation on a real-word annotated dataset to demonstrate the efficacy of our approach.
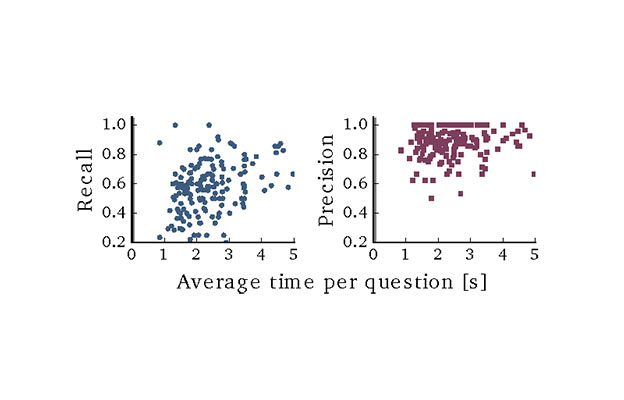
Large-scale annotated datasets allow AI systems to learn from and build upon the knowledge of the crowd. Many crowdsourcing techniques have been developed for collecting image annotations. These techn... iques often implicitly rely on the fact that a new input image takes a negligible amount of time to perceive. In contrast, we investigate and determine the most cost-effective way of obtaining high-quality multi-label annotations for temporal data such as videos. Watching even a short 30-second video clip requires a significant time investment from a crowd worker; thus, requesting multiple annotations following a single viewing is an important cost-saving strategy. But how many questions should we ask per video? We conclude that the optimal strategy is to ask as many questions as possible in a HIT (up to 52 binary questions after watching a 30-second video clip in our experiments). We demonstrate that while workers may not correctly answer all questions, the cost-benefit analysis nevertheless favors consensus from multiple such cheap-yet-imperfect iterations over more complex alternatives. When compared with a one-question-per-video baseline, our method is able to achieve a 10% improvement in recall (76.7% ours versus 66.7% baseline) at comparable precision (83.8% ours versus 83.0% baseline) in about half the annotation time (3.8 minutes ours compared to 7.1 minutes baseline). We demonstrate the effectiveness of our method by collecting multi-label annotations of 157 human activities on 1,815 videos.
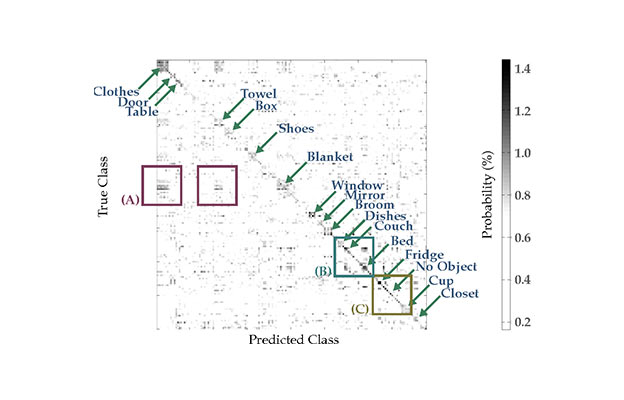
Computer vision has a great potential to help our daily lives by searching for lost keys, watering flowers or reminding us to take a pill. To succeed with such tasks, computer vision methods need to b... e trained from real and diverse examples of our daily dynamic scenes. While most of such scenes are not particularly exciting, they typically do not appear on YouTube, in movies or TV broadcasts. So how do we collect sufficiently many diverse but boring samples representing our lives? We propose a novel Hollywood in Homes approach to collect such data. Instead of shooting videos in the lab, we ensure diversity by distributing and crowdsourcing the whole process of video creation from script writing to video recording and annotation. Following this procedure we collect a new dataset, Charades, with hundreds of people recording videos in their own homes, acting out casual everyday activities. The dataset is composed of 9,848 annotated videos with an average length of 30 seconds, showing activities of 267 people from three continents. Each video is annotated by multiple free-text descriptions, action labels, action intervals and classes of interacted objects. In total, Charades provides 27,847 video descriptions, 66,500 temporally localized intervals for 157 action classes and 41,104 labels for 46 object classes. Using this rich data, we evaluate and provide baseline results for several tasks including action recognition and automatic description generation. We believe that the realism, diversity, and casual nature of this dataset will present unique challenges and new opportunities for computer vision community.
We propose two efficient approximations to standard convolutional neural networks: Binary-Weight-Networks and XNOR-Networks. In Binary-Weight-Networks, the filters are approximated with binary values... resulting in $32 imes$ memory saving. In XNOR-Networks, both the filters and the input to convolutional layers are binary. XNOR-Networks approximate convolutions using primarily binary operations. This results in 58x faster convolutional operations (in terms of number of the high precision operations) and 32x memory savings. XNOR-Nets offer the possibility of running state-of-the-art networks on CPUs (rather than GPUs) in real-time. Our binary networks are simple, accurate, efficient, and work on challenging visual tasks. We evaluate our approach on the ImageNet classification task. The classification accuracy with a Binary-Weight-Network version of AlexNet is the same as the full-precision AlexNet. We compare our method with recent network binarization methods, BinaryConnect and BinaryNets, and outperform these methods by large margins on ImageNet, more than 16% in top-1 accuracy.

What happens if one pushes a cup sitting on a table toward the edge of the table? How about pushing a desk against a wall? In this paper, we study the problem of understanding the movements of objects... as a result of applying external forces to them. For a given force vector applied to a specific location in an image, our goal is to predict long-term sequential movements caused by that force. Doing so entails reasoning about scene geometry, objects, their attributes, and the physical rules that govern the movements of objects. We design a deep neural network model that learns long-term sequential dependencies of object movements while taking into account the geometry and appearance of the scene by combining Convolutional and Recurrent Neural Networks. Training our model requires a large-scale dataset of object movements caused by external forces. To build a dataset of forces in scenes, we reconstructed all images in SUN RGB-D dataset in a physics simulator to estimate the physical movements of objects caused by external forces applied to them. Our Forces in Scenes (ForScene) dataset contains 65,000 object movements in 3D which represent a variety of external forces applied to different types of objects. Our experimental evaluations show that the challenging task of predicting long-term movements of objects as their reaction to external forces is possible from a single image.
Diagrams are common tools for representing complex concepts, relationships and events, often when it would be difficult to portray the same information with natural images. Understanding natural image... s has been extensively studied in computer vision, while diagram understanding has received little attention. In this paper, we study the problem of diagram interpretation, the challenging task of identifying the structure of a diagram and the semantics of its constituents and their relationships. We introduce Diagram Parse Graphs (DPG) as our representation to model the structure of diagrams. We define syntactic parsing of diagrams as learning to infer DPGs for diagrams and study semantic interpretation and reasoning of diagrams in the context of diagram question answering. We devise an LSTM-based method for syntactic parsing of diagrams and introduce a DPG-based attention model for diagram question answering. We compile a new dataset of diagrams with exhaustive annotations of constituents and relationships for about 5,000 diagrams and 15,000 questions and answers. Our results show the significance of our models for syntactic parsing and question answering in diagrams using DPGs.
Clustering is central to many data-driven application domains and has been studied extensively in terms of distance functions and grouping algorithms. Relatively little work has focused on learning re... presentations for clustering. In this paper, we propose Deep Embedded Clustering (DEC), a method that simultaneously learns feature representations and cluster assignments using deep neural networks. DEC learns a mapping from the data space to a lower-dimensional feature space in which it iteratively optimizes a clustering objective. Our experimental evaluations on image and text corpora show significant improvement over state-of-the-art methods.

Figures and tables are key sources of information in many scholarly documents. However, current academic search engines do not make use of figures and tables when semantically parsing documents or pre... senting document summaries to users. To facilitate these applications we develop an algorithm that extracts figures, tables, and captions from documents called "PDFFigures 2.0." Our proposed approach analyzes the structure of individual pages by detecting captions, graphical elements, and chunks of body text, and then locates figures and tables by reasoning about the empty regions within that text. To evaluate our work, we introduce a new dataset of computer science papers, along with ground truth labels for the locations of the figures, tables, and captions within them. Our algorithm achieves impressive results (94% precision at 90% recall) on this dataset surpassing previous state of the art. Further, we show how our framework was used to extract figures from a corpus of over one million papers, and how the resulting extractions were integrated into the user interface of a smart academic search engine, Semantic Scholar (www.semanticscholar.org). Finally, we present results of exploratory data analysis completed on the extracted figures as well as an extension of our method for the task of section title extraction. We release our dataset and code on our project webpage for enabling future research (http://pdffigures2.allenai.org).

With the recent progress in visual recognition, we have already started to see a surge of vision related real-world applications. These applications, unlike general scene understanding, are task orien... ted and require specific information from visual data. Considering the current growth in new sensory devices, feature designs, feature learning methods, and algorithms, the search in the space of features and models becomes combinatorial. In this paper, we propose a novel cost-sensitive task-oriented recognition method that is based on a combination of linguistic semantics and visual cues. Our task-oriented framework is able to generalize to unseen tasks for which there is no training data and outperforms state-of-the-art cost-based recognition baselines on our new task-based dataset.
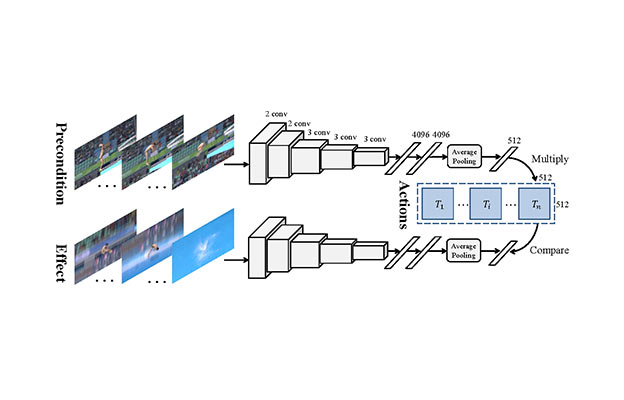
What defines an action like “kicking ball”? We argue that the true meaning of an action lies in the change or transformation an action brings to the environment. In this paper, we propose a novel repr... esentation for actions by modeling an action as a transformation which changes the state of the environment before the action happens (pre-condition) to the state after the action (effect). Motivated by recent advancements of video representation using deep learning, we design a Siamese network which models the action as a transformation on a high-level feature space. We show that our model gives improvements on standard action recognition datasets including UCF101 and HMDB51. More importantly, our approach is able to generalize beyond learned action categories and shows significant performance improvement on cross-category generalization on our new ACT dataset.
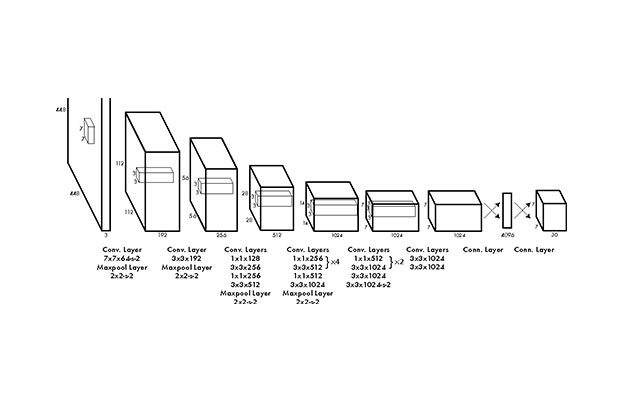
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially... separated bounding boxes and associated class probabilities. A single neural network pre- dicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimized end-to-end directly on detection performance. Our unified architecture is extremely fast. Our base YOLO model processes images in real-time at 45 frames per second. A smaller version of the network, Fast YOLO, processes an astounding 155 frames per second while still achieving double the mAP of other real-time detec- tors. Compared to state-of-the-art detection systems, YOLO makes more localization errors but is less likely to predict false positives on background. Finally, YOLO learns very general representations of objects. It outperforms other detection methods, including DPM and R-CNN, when generalizing from natural images to other domains like artwork.

In this paper, we study the challenging problem of predicting the dynamics of objects in static images. Given a query object in an image, our goal is to provide a physical understanding of the object... in terms of the forces acting upon it and its long term motion as response to those forces. Direct and explicit estimation of the forces and the motion of objects from a single image is extremely challenging. We define intermediate physical abstractions called Newtonian scenarios and introduce Newtonian Neural Network (N3) that learns to map a single image to a state in a Newto- nian scenario. Our evaluations show that our method can reliably predict dynamics of a query object from a single image. In addition, our approach can provide physical rea- soning that supports the predicted dynamics in terms of ve- locity and force vectors. To spur research in this direction we compiled Visual Newtonian Dynamics (VIND) dataset that includes more than 6000 videos aligned with Newto- nian scenarios represented using game engines, and more than 4500 still images with their ground truth dynamics.

This paper introduces situation recognition, the problem of producing a concise summary of the situation an image depicts including: (1) the main activity (e.g., clipping), (2) the participating actor... s, objects, substances, and locations (e.g., man, shears, sheep, wool, and field) and most importantly (3) the roles these participants play in the activity (e.g., the man is clipping, the shears are his tool, the wool is being clipped from the sheep, and the clipping is in a field). We use FrameNet, a verb and role lexicon devel- oped by linguists, to define a large space of possible sit- uations and collect a large-scale dataset containing over 500 activities, 1,700 roles, 11,000 objects, 125,000 images, and 200,000 unique situations. We also introduce struc- tured prediction baselines and show that, in activity-centric images, situation-driven prediction of objects and activities outperforms independent object and activity recognition.
Obtaining common sense knowledge using current information extraction techniques is extremely challenging. In this work, we instead propose to derive simple common sense statements from fully annotate... d object detection corpora such as the Microsoft Common Objects in Context dataset. We show that many thousands of common sense facts can be extracted from such corpora at high quality. Furthermore, using WordNet and a novel submodular k-coverage formulation, we are able to generalize our initial set of common sense assertions to unseen objects and uncover over 400k potentially useful facts.
Human vision greatly benefits from the information about sizes of objects. The role of size in several visual reasoning tasks has been thoroughly explored in human perception and cognition. However, t... he impact of the information about sizes of objects is yet to be determined in AI. We postulate that this is mainly attributed to the lack of a comprehensive repository of size information. In this paper, we introduce a method to automatically infer object sizes, leveraging visual and textual information from web. By maximizing the joint likelihood of textual and visual observations, our method learns reliable relative size estimates, with no explicit human supervision. We introduce the relative size dataset and show that our method outperforms competitive textual and visual baselines in reasoning about size comparisons.
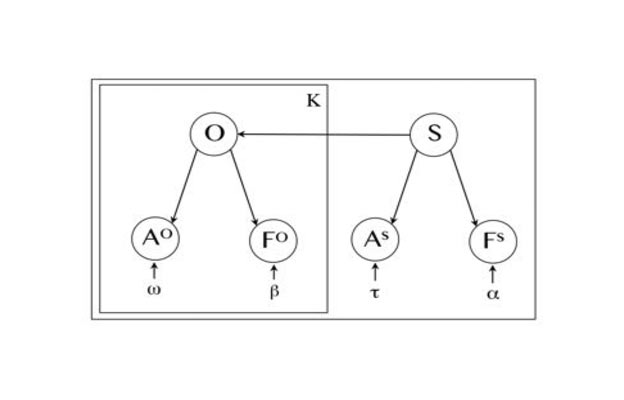
The human visual system can spot an abnormal image, and reason about what makes it strange. This task has not received enough attention in computer vision. In this paper we study various types of atyp... icalities in images in a more comprehensive way than has been done before. We propose a new dataset of abnormal images showing a wide range of atypicalities. We design human subject experiments to discover a coarse taxonomy of the reasons for abnormality. Our experiments reveal three major categories of abnormality: object-centric, scene-centric, and contextual. Based on this taxonomy, we propose a comprehensive computational model that can predict all different types of abnormality in images and outperform prior arts in abnormality recognition.
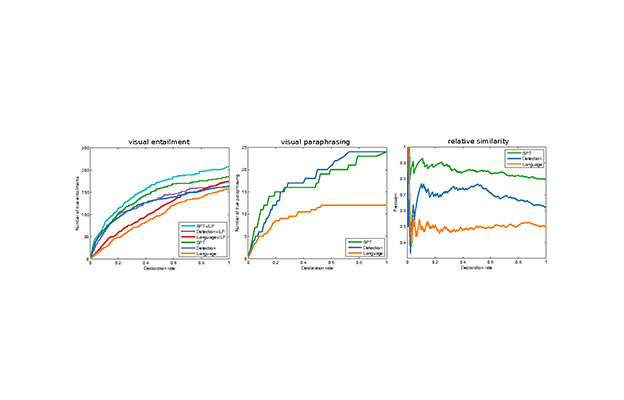
We introduce Segment-Phrase Table (SPT), a large collection of bijective associations between textual phrases and their corresponding segmentations. Leveraging recent progress in object recognition an... d natural language semantics, we show how we can successfully build a highquality segment-phrase table using minimal human supervision. More importantly, we demonstrate the unique value unleashed by this rich bimodal resource, for both vision as well as natural language understanding. First, we show that fine-grained textual labels facilitate contextual reasoning that helps in satisfying semantic constraints across image segments. This feature enables us to achieve state-of-the-art segmentation results on benchmark datasets. Next, we show that the association of high-quality segmentations to textual phrases aids in richer semantic understanding and reasoning of these textual phrases. Leveraging this feature, we motivate the problem of visual entailment and visual paraphrasing, and demonstrate its utility on a large dataset.
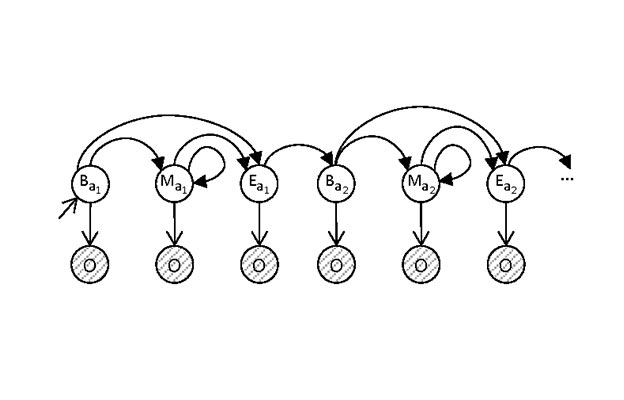
We all have experienced forgetting habitual actions among our daily activities. For example, we probably have forgotten to turn the lights off before leaving a room or turn the stove off after cooking... . In this paper, we propose a solution to the problem of issuing notifications on actions that may be missed. This involves learning about interdependencies between actions and being able to predict an ongoing action while segmenting the input video stream. In order to show a proof of concept, we collected a new egocentric dataset, in which people wear a camera while making lattes. We show promising results on the extremely challenging task of issuing correct and timely reminders. We also show that our model reliably segments the actions, while predicting the ongoing one when only a few frames from the beginning of the action are observed. The overall prediction accuracy is 46.2% when only 10 frames of an action are seen (2/3 of a sec). Moreover, the overall recognition and segmentation accuracy is shown to be 72.7% when the whole activity sequence is observed. Finally, the online prediction and segmentation accuracy is 68.3% when the prediction is made at every time step.

In this paper we present a bottom-up method to instance level Multiple Instance Learning (MIL) that learns to discover positive instances with globally constrained reasoning about local pairwise simil... arities. We discover positive instances by optimizing for a ranking such that positive (top rank) instances are highly and consistently similar to each other and dissimilar to negative instances. Our approach takes advantage of a discriminative notion of pairwise similarity coupled with a structural cue in the form of a consistency metric that measures the quality of each similarity. We learn a similarity function for every pair of instances in positive bags by how similarly they differ from instances in negative bags, the only certain labels in MIL. Our experiments demonstrate that our method consistently outperforms state-of-the-art MIL methods both at bag-level and instance-level predictions in standard benchmarks, image category recognition, and text categorization datasets.
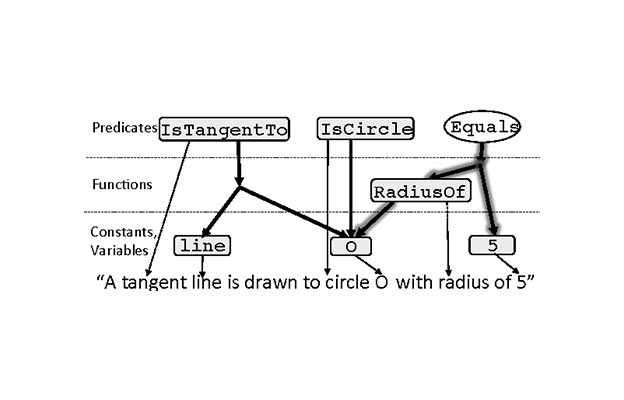
This paper introduces GEOS, the first automated system to solve unaltered SAT geometry questions by combining text understanding and diagram interpretation. We model the problem of understanding geome... try questions as submodular optimization, and identify a formal problem description likely to be compatible with both the question text and diagram. GEOS then feeds the description to a geometric solver that attempts to determine the correct answer. In our experiments, GEOS achieves a 49% score on official SAT questions, and a score of 61% on practice questions. Finally, we show that by integrating textual and visual information, GEOS boosts the accuracy of dependency and semantic parsing of the question text.

In this paper, we study the problem of answering visual analogy questions. These questions take the form of image A is to image B as image C is to what. Answering these questions entails discovering t... he mapping from image A to image B and then extending the mapping to image C and searching for the image D such that the relation from A to B holds for C to D.We pose this problem as learning an embedding that encourages pairs of analogous images with similar transformations to be close together using convolutional neural networks with a quadruple Siamese architecture. We introduce a dataset of visual analogy questions in natural images, and show first results of its kind on solving analogy questions on natural images.
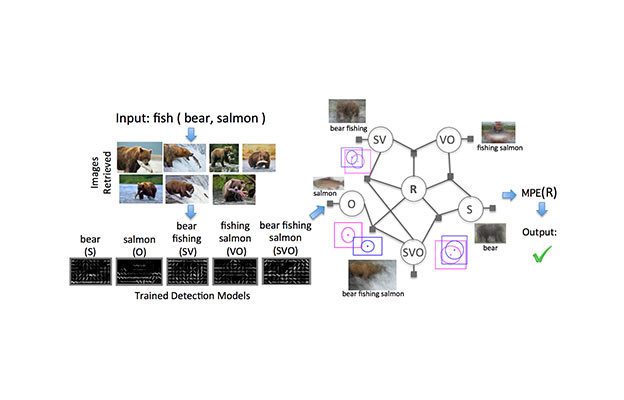
How can we know whether a statement about our world is valid. For example, given a relationship between a pair of entities e.g., 'eat(horse, hay)', how can we know whether this relationship is true or... false in general. Gathering such knowledge about entities and their relationships is one of the fundamental challenges in knowledge extraction. Most previous works on knowledge extraction havefocused purely on text-driven reasoning for verifying relation phrases. In this work, we introduce the problemof visual verification of relation phrases and developed aVisual Knowledge Extraction system called VisKE. Given a verb-based relation phrase between common nouns, our approach assess its validity by jointly analyzing over textand images and reasoning about the spatial consistency of the relative configurations of the entities and the relation involved. Our approach involves no explicit human supervision there by enabling large-scale analysis. Using our approach, we have already verified over 12000 relation phrases. Our approach has been used to not only enrich existing textual knowledge bases by improving their recall,but also augment open-domain question-answer reasoning.
Identifying and extracting figures and tables along with their captions from scholarly articles is important both as a way of providing tools for article summarization, and as part of larger systems t... hat seek to gain deeper, semantic understanding of these articles. While many "off-the-shelf" tools exist that can extract embedded images from these documents, e.g. PDFBox, Poppler, etc., these tools are unable to extract tables, captions, and figures composed of vector graphics. Our proposed approach analyzes the structure of individual pages of a document by detecting chunks of body text, and locates the areas wherein figures or tables could reside by reasoning about the empty regions within that text. This method can extract a wide variety of figures because it does not make strong assumptions about the format of the figures embedded in the document, as long as they can be differentiated from the main article's text. Our algorithm also demonstrates a caption-to-figure matching component that is effective even in cases where individual captions are adjacent to multiple figures. Our contribution also includes methods for leveraging particular consistency and formatting assumptions to identify titles, body text and captions within each article. We introduce a new dataset of 150 computer science papers along with ground truth labels for the locations of the figures, tables and captions within them. Our algorithm achieves 96% precision at 92% recall when tested against this dataset, surpassing previous state of the art. We release our dataset, code, and evaluation scripts on our project website for enabling future research.

We propose the problem of automated photo album creation from an unordered image collection. The problem is difficult as it involves a number of complex perceptual tasks that facilitate selection and... ordering of photos to create a compelling visual narrative. To help solve this problem, we collect (and will make available) a new benchmark dataset based on Flickr images. Flickr Album Dataset and provides a variety of annotations useful for the task, including manually created albums of various lengths. We analyze the problem and provide experimental evidence, through user studies, that both selection and ordering of photos within an album is important for human observers. To capture and learn rules of album composition, we propose a discriminative structured model capable of encoding simple preferences for contextual layout of the scene (e.g., spatial layout of faces, global scene context, and presence/absence of attributes) and ordering between photos (e.g., exclusion principles or correlations). The parameters of the model are learned using a structured SVM framework. Once learned, the model allows automatic composition of photo albums from unordered and untagged collections of images. We quantitatively evaluate the results obtained using our model against manually created albums and baselines on a dataset of 63 personal photo collections from 5 different topics.
Automatically solving geometry questions is a longstanding AI problem. A geometry question typically includes a textual description accompanied by a diagram. The first step in solving geometry questio... ns is diagram understanding, which consists of identifying visual elements in the diagram, their locations, their geometric properties, and aligning them to corresponding textual descriptions. In this paper, we present a method for diagram understanding that identifies visual elements in a diagram while maximizing agreement between textual and visual data. We show that the method’s objective function is submodular; thus we are able to introduce an efficient method for diagram understanding that is close to optimal. To empirically evaluate our method, we compile a new dataset of geometry questions (textual descriptions and diagrams) and compare with baselines that utilize standard vision techniques. Our experimental evaluation shows an F1 boost of more than 17% in identifying visual elements and 25% in aligning visual elements with their textual descriptions.

Recognition is graduating from labs to real-world applications. While it is encouraging to see its potential being tapped, it brings forth a fundamental challenge to the vision researcher: scalability... . How can we learn a model for any concept that exhaustively covers all its appearance variations, while requiring minimal or no human supervision for compiling the vocabulary of visual variance, gathering the training images and annotations, and learning the models? In this paper, we introduce a fully-automated approach for learning extensive models for a wide range of variations (e.g. actions, interactions, attributes and beyond) within any concept. Our approach leverages vast resources of online books to discover the vocabulary of variance, and intertwines the data collection and modeling steps to alleviate the need for explicit human supervision in training the models. Our approach organizes the visual knowledge about a concept in a convenient and useful way, enabling a variety of applications across vision and NLP. Our online system has been queried by users to learn models for several interesting concepts including breakfast, Gandhi, beautiful, etc. To date, our system has models available for over 50,000 variations within 150 concepts, and has annotated more than 10 million images with bounding boxes.