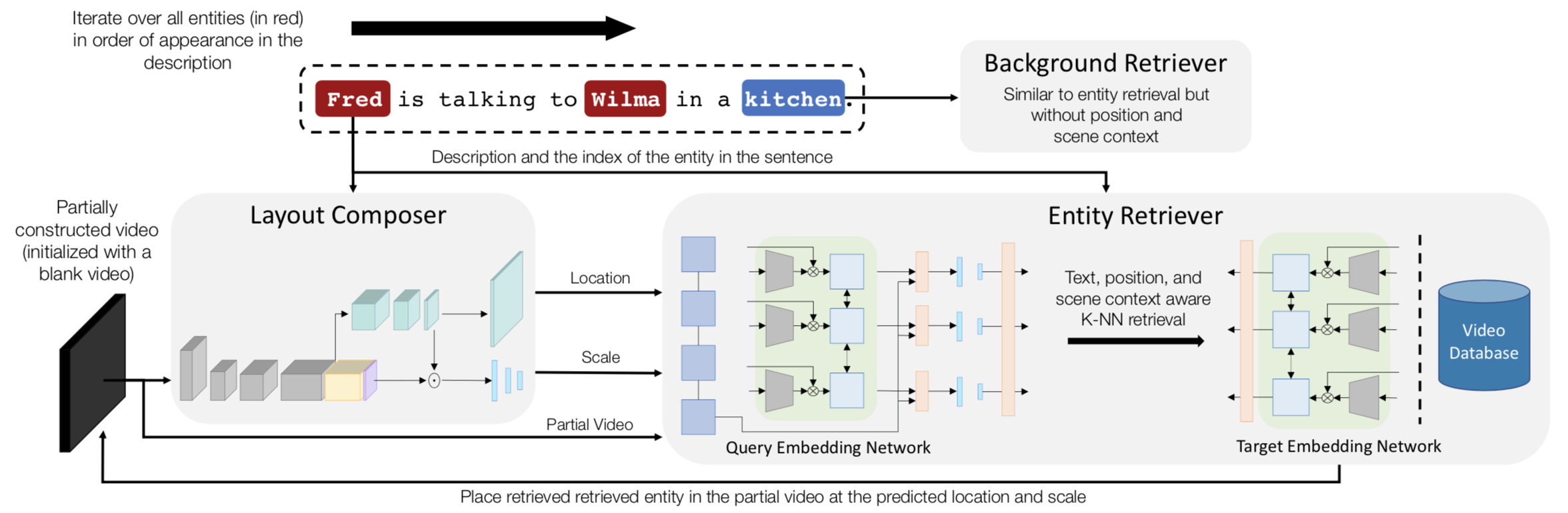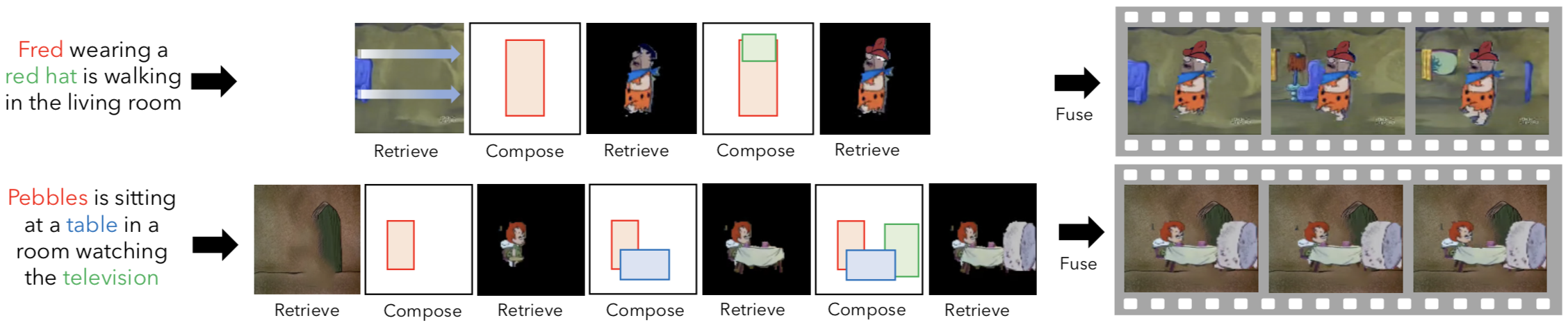
Imagining a scene described in natural language with realistic layout and appearance of entities is the ultimate test of spatial, visual, and semantic world knowledge. Towards this goal, we present the Composition, Retrieval, and Fusion Network (CRAFT), a model capable of learning this knowledge from video-caption data and applying it while generating videos from novel captions. CRAFT explicitly predicts a temporal-layout of mentioned entities (characters and objects), retrieves spatio-temporal entity segments from a video database and fuses them to generate scene videos. Our contributions include sequential training of components of CRAFT while jointly modeling layout and appearances, and losses that encourage learning compositional representations for retrieval. We evaluate CRAFT on semantic fidelity to caption, composition consistency, and visual quality. CRAFT outperforms direct pixel generation approaches and generalizes well to unseen captions and to unseen video databases with no text annotations. We demonstrate CRAFT on FLINTSTONES, a new richly annotated video-caption dataset with over 25000 videos.
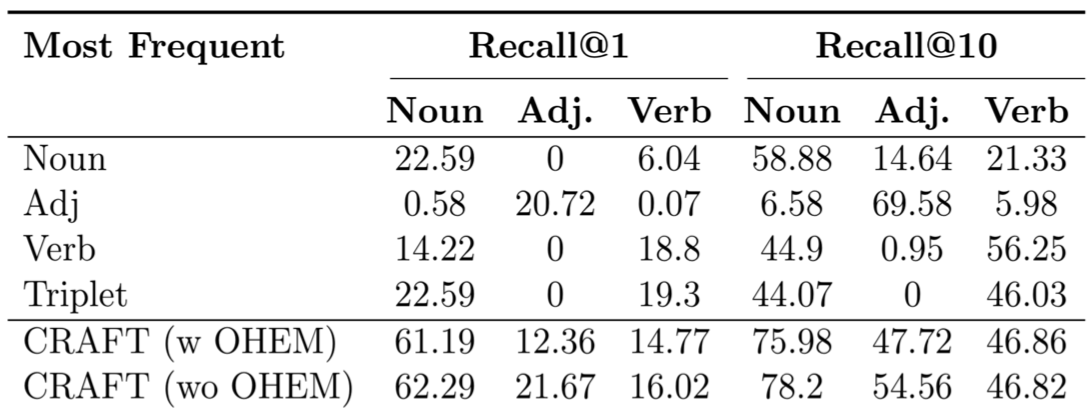
While the paper contains detailed ablation experiments on CRAFT, here we include additional baselines for Entity Retriever evaluation that could not be included in the paper because of space constraints. This baseline simply predicts the most frequent entities instead of using our Entity Retriever. The idea is to verify that the Noun, Adjective, and Verb Recall performance of CRAFT is not simply due to a skewed data distribution.
Recall values for these baselines are shown below. Rows correspond to different ways of selecting the top k (for Recall@k) entities to be predicted. E.g., Noun selects k most frequent nouns in the training data and then for each noun, an entity containing that noun is randomly chosen. Triplet corresponds to selecting entities jointly considering frequency of associated noun, adjective, and verbs. CRAFT is nearly 3x better than these baselines in noun Recall@1. While Adj and Verb baselines sometimes outperform CRAFT on respective recalls, it is important to consider them jointly with noun recall. This is because retrieving "red hat" instead of "red shirt" is incorrect but produces a perfect adjective recall.

The Flintstones dataset is composed of 25184 densely annotated video clips derived from the animated sitcom The Flintstones. Clips are to be 3 seconds (75 frames) and capture relatively small action sequences.
How were the clips created?
The clips in the dataset are taken from multiple episodes and seasons. Clips were created from the original episodes by first detecting shot changes in each episode by thresholding on the pixel distance between consecutive frames. Shots longer than 75 frames were broken down into multiple 75 frame shots and those smaller than 75 frames were discarded.
How was the train-val-test split created?
Nearby clips from within an episode can be similar (sharing entities and actions), while clips from different episodes consistently differ in some aspect. We ensure that all clips taken from the same episode are assigned entirely to either: train, val or test. Within a season, episodes are split using 80-10-10 split. This allows the training data to capture a wide gamut of characters, objects, actions, and scenes of the Flintstones world, while preventing test set captions and videos from being too similar to train or val as a whole.