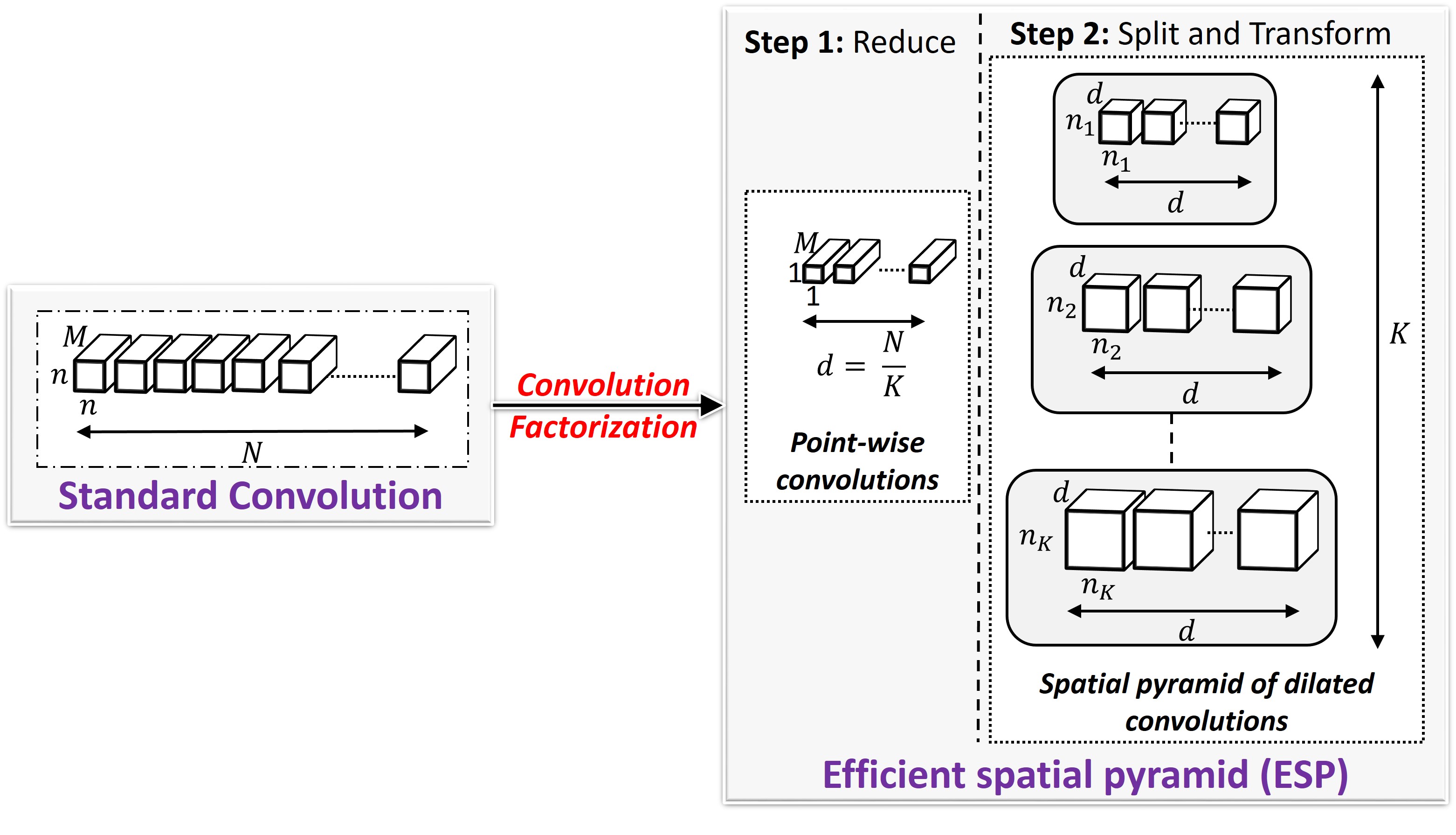
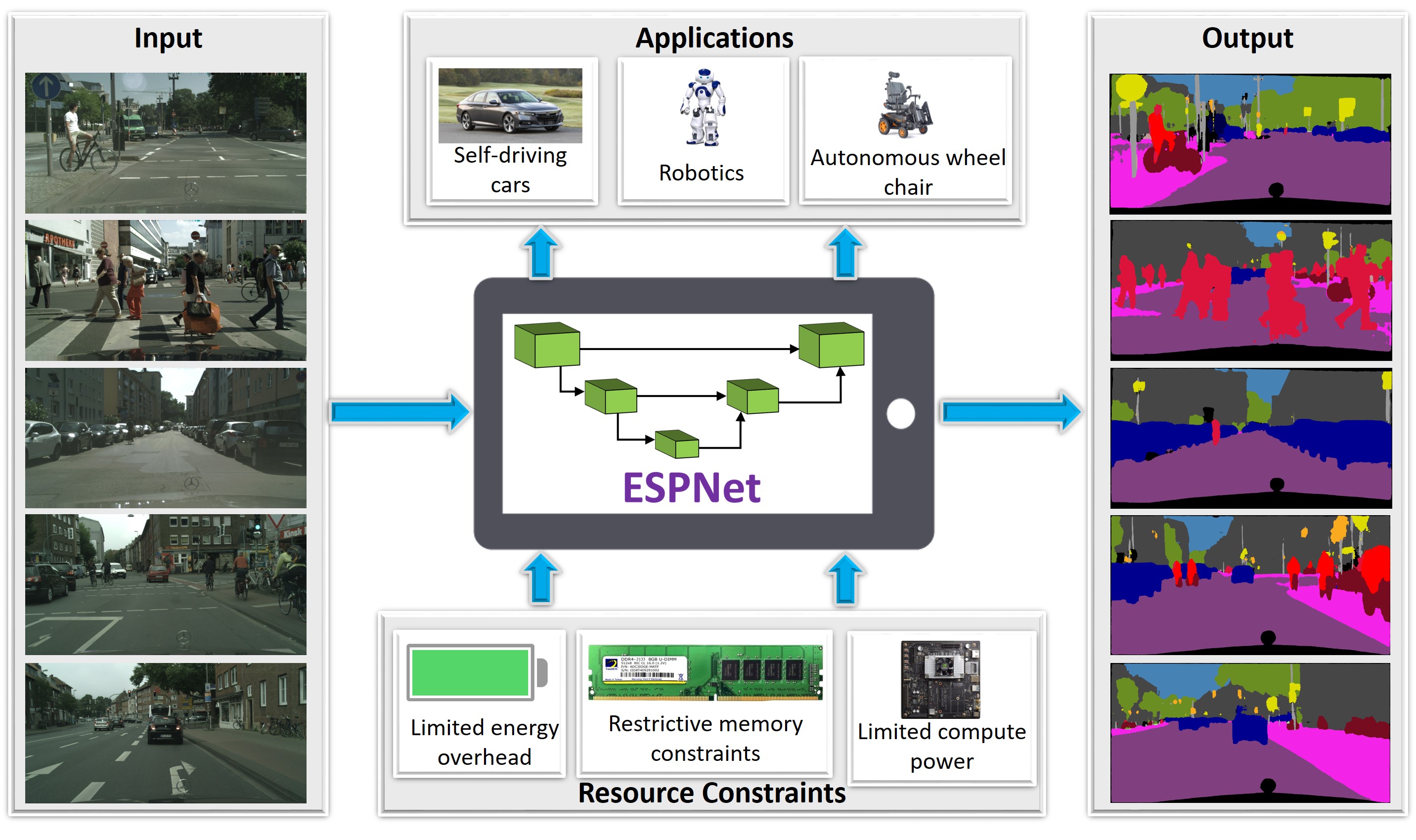
ESPNets are state-of-the-art CNN-based architectures that adhere to restrictive constraints, such as limited memory, limited computational power, and limited energy, of edge devices. ESPNets are built on a new convolutional unit, ESP (Efficient spatial pyramid), that decomposes a standard convolution into two steps: () point-wise convolutions and (2) spatial pyramid of dilated convolutions. The point-wise convolutions help in reducing the computation, while the spatial pyramid of dilated convolutions re-samples the feature maps to learn the representations from large effective receptive field. We show that ESPNets are more efficient than the state-of-the-art methods, including MobileNets and ShuffleNets, and achieves better performance across different computer vision tasks, including object classification, semantic segmentation, and object detection.