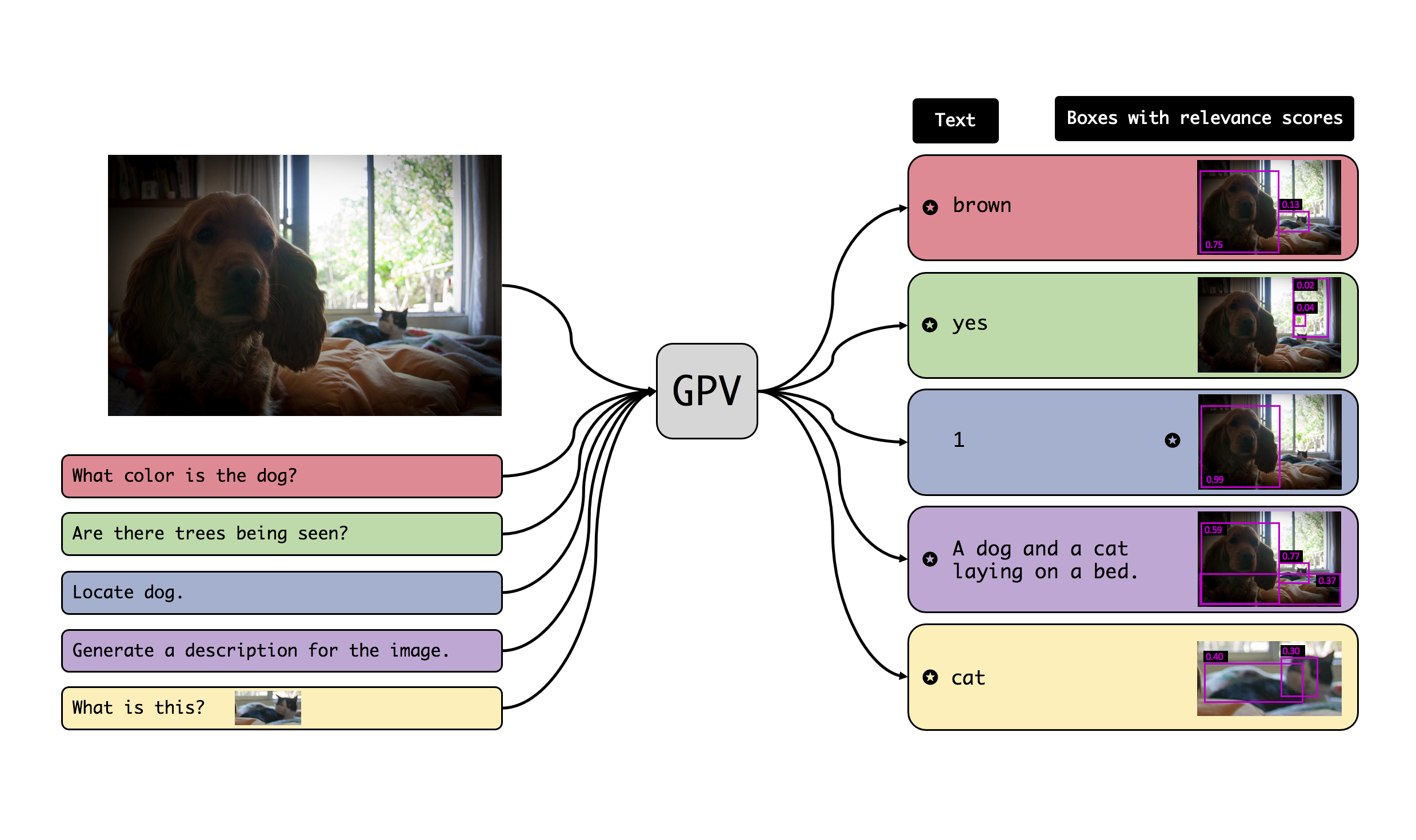
A special purpose learning system assumes knowledge of admissible tasks at design time. Adapting such a system to unforeseen tasks requires architecture manipulation such as adding an output head for each new task or dataset. In this work, we propose a task-agnostic vision-language system that accepts an image and a natural language task description and outputs bounding boxes, confidences, and text. The system supports a wide range of vision tasks such as classification, localization, question answering, captioning, and more. We evaluate the system's ability to learn multiple skills simultaneously, to perform tasks with novel skill-concept combinations, and to learn new skills efficiently and without forgetting.
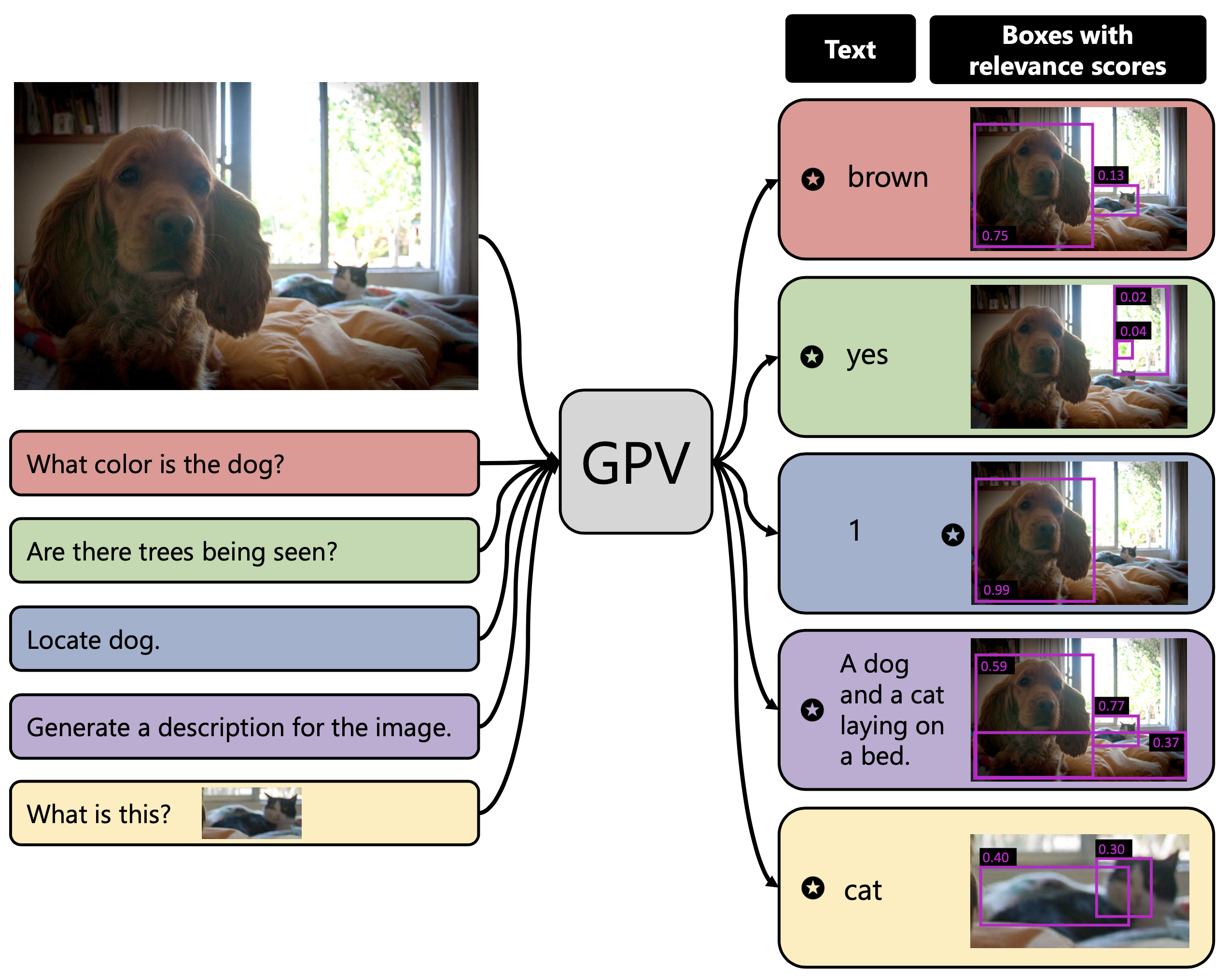
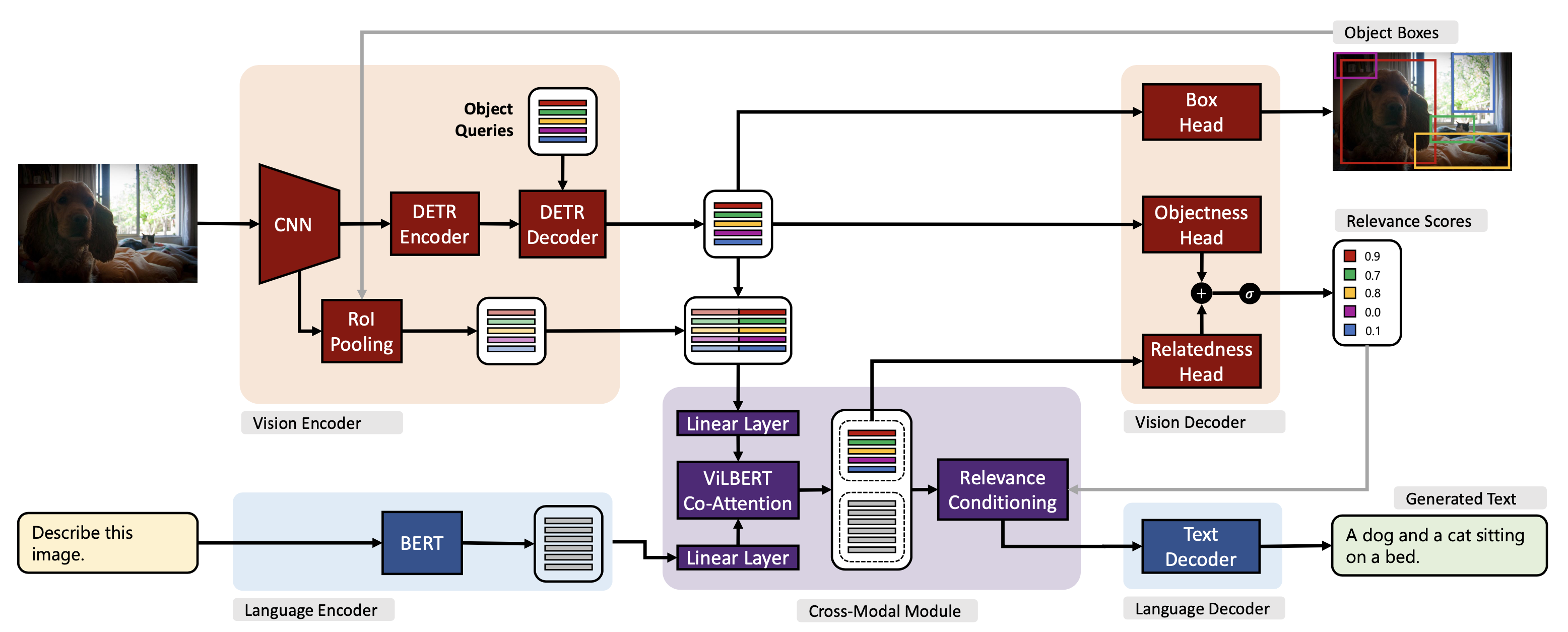
GPV-I is a general purpose vision-language architecture that can learn and perform any task that requires bounding boxes or text prediction. We demonstrate the effectiveness of GPV-I by jointly training it on VQA, Captioning, Localization, and Classification tasks and achieveing favorable performance in comparison to specialized single-task models.
GPV-I consisting of a visual encoder, language encoder, vision-language co-attention module, and output heads for the supported output modalities - boxes, relevance scores, and text. We use the CNN backbone and the transformer encoder-decoder from DETR, an end-to-end trainable object detector. The natural language task description is encoded with BERT. To cross-contextualize representations from the visual and language encoders, we use ViLBERT's co-attention module. Box and objectness heads predict task-agnostic bounding boxes and scores. Relatedness head predicts a task-specific score for each output box that is combined with the objectness scores to obtain relevance scores. The text decoder is a transformer decoder that auto-regressively generates text output while using relevance-conditioned representations produced by the cross-modal module as memory.