Situation Recognition is the task of recognizing the activity happening in an image, the actors and objects involved in this activity, and the roles they play. Semantic roles describe how objects in the image participate in the activity described by the verb. While situation recognition addresses what is happening in an image, who is playing a part in this and what their roles are, it does not address a critical aspect of visual understanding: where the involved entities lie in the image. We address this shortcoming and present Grounded Situation Recognition (GSR), a task that builds upon situation recognition and requires one to not just identify the situation observed in the image but also visually ground the identified roles within the corresponding image.
We present the Situations With Groundings (SWiG) Dataset for training and evalutation on the GSR task. This dataset builds upon the Situation Recognition dataset presented by Yatskar et al. The SWiG dataset contains approximately 125,000 images. Each image is associated with one verb. Three different annotators then label each entity in the frame associated with that verb and mark the location of the entity in the image. All three labels for each role are given in the SWiG dataset as well as an average of the three localizations.
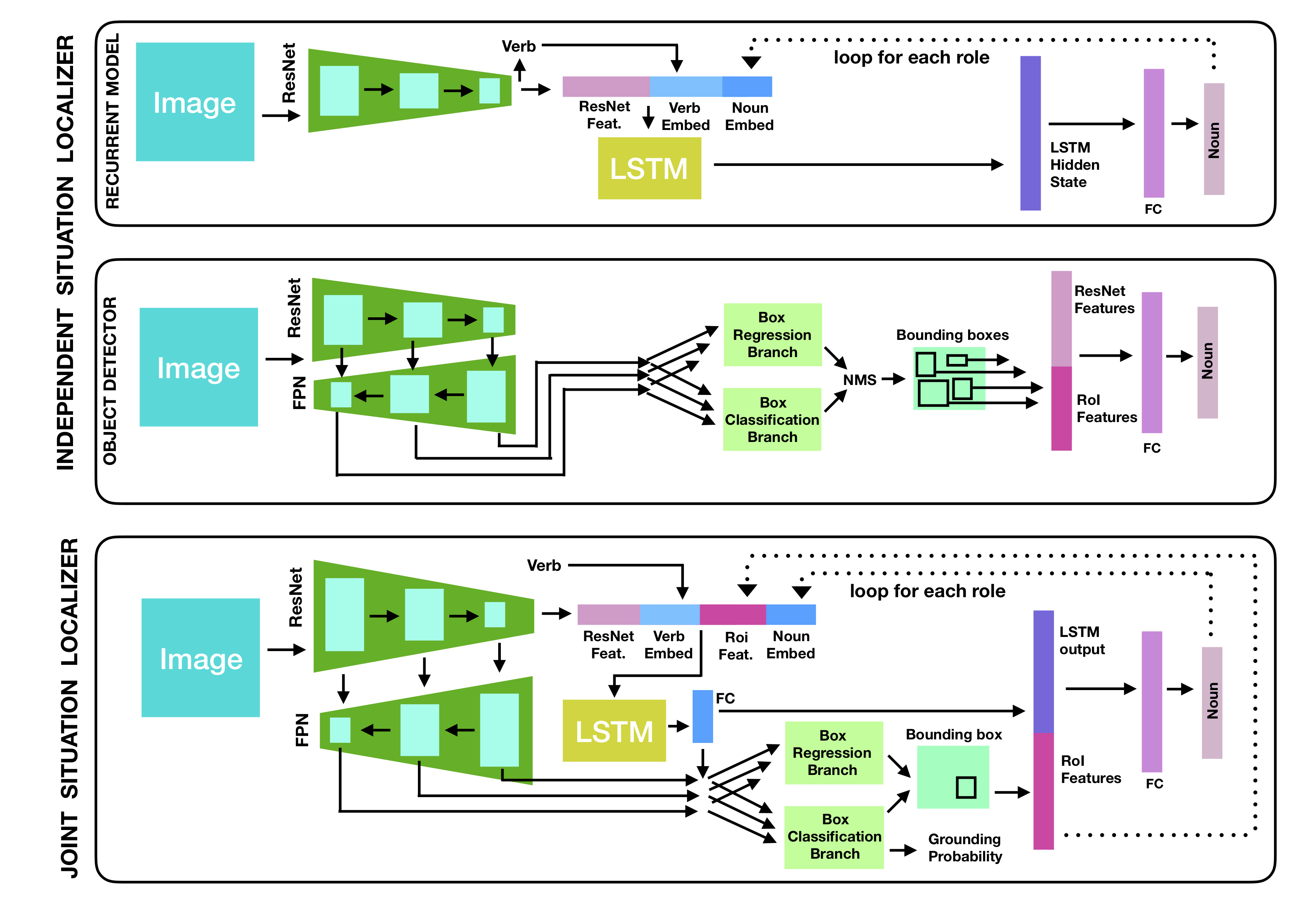
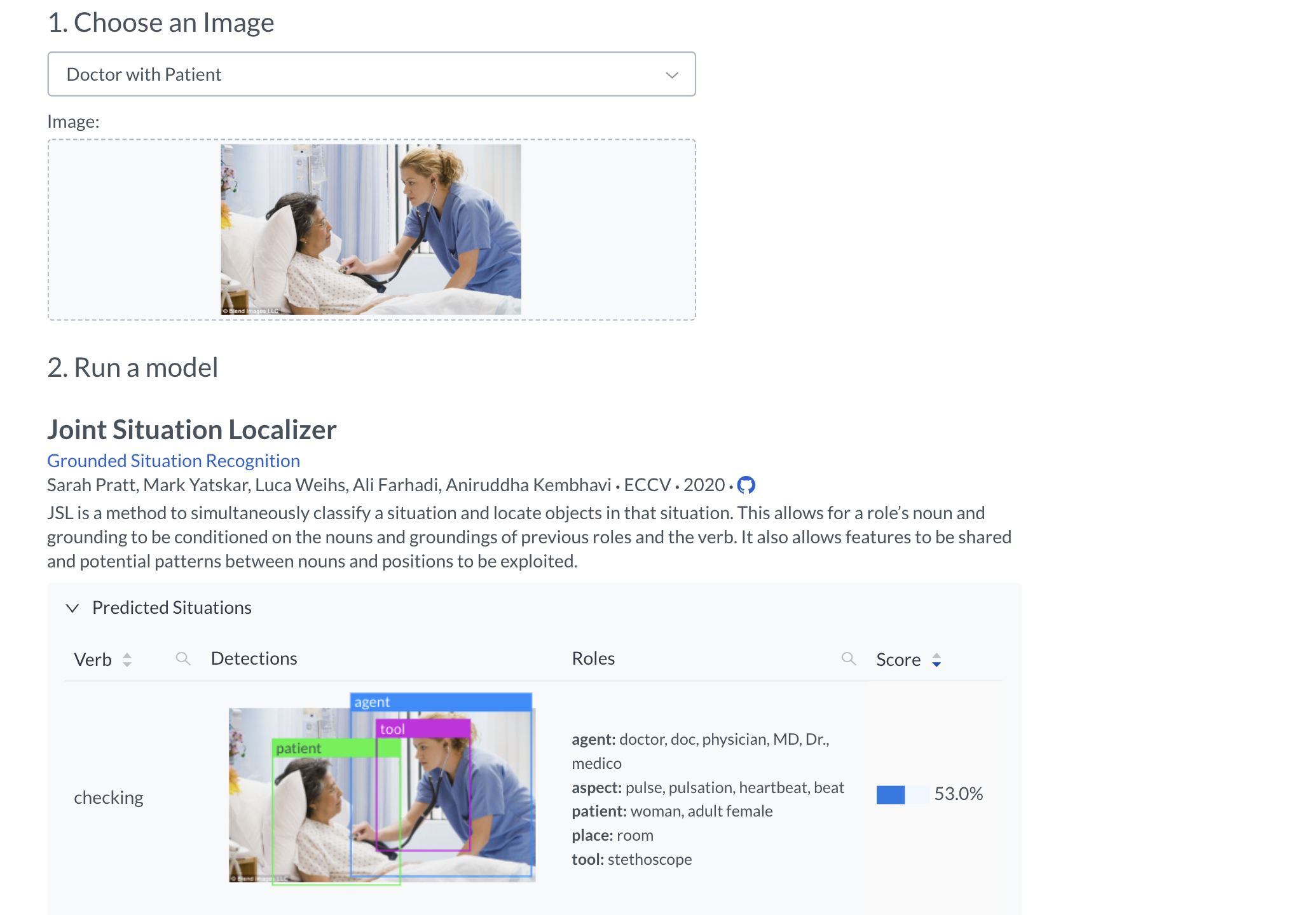
Along with the task and dataset, we present two methods for Grounded Situation Recognition. First, we present a baseline (Independent Situation Localizer) which used one model to predict a label for each role and then independently localizes each of these objects in the image. Additionally, we present the Joint Situation Localizer which jointly predicts the location and classification of each role. This improves over the baseline on all metrics and provides strong evidence for the efficacy of using spatial information to better understand the situation in the image.
The below figure shows some qualitative results for the Joint Situation Localizer. The top two rows demonstrate examples where the situations are well classified. The third row shows errors where the label for certain roles is incorrect. The last row shows errors where the localization is incorrect.

Grounded situation recognition and SWiG open up several exciting directions for future research. We present initial findings for some of these explorations. One application is Semantic Image Retrieval. This task involves identifying images which are semantically similar to a query image. The below figure shows initial results for this task, compared to several strong baselines. Note that comparing images based on their predicted grounded situation provides a strong match between images, both semantically and spatially.
Additionally, we extend this work by adjusting the JSL architecture to condition its prediction on a region of the image. This allows for multiple different image descriptions for more complex images, such as a woman who is both feeding a baby and working on a computer. The Conditional Situation Localizer allows for a much richer understanding of the image by chaining together many different situations. If we know that a particular region of the image contains an entity which is participating in multiple actions, we can start to reason about the larger context of actions within an image.

Explore grounded situation recogition and JSL (as well as many other computer vision tasks) with the AI2 vision explorer.
This is a video explanation of this work, which was given as a spotlight presentation at ECCV 2020.
