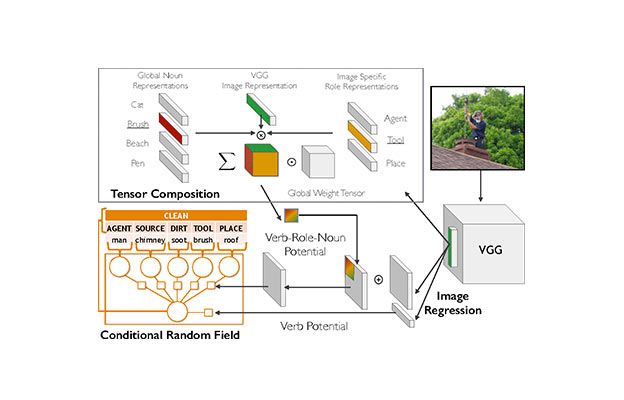
imSitu is a dataset supporting situation recognition, the problem of producing a concise summary of the situation an image depicts including: (1) the main activity, (2) the participating actors, objects, substances, and locations and most importantly (3) the roles these participants play in the activity. The role set used by imSitu is derived from the linguistic resource FrameNet and the entities are derived from ImageNet. The data in imSitu can be used to create robust algorithms for situation recognition.
On September 19, 2016, the New York Times published an article about imSitu called Computer Vision: On the Way to Seeing More.
| Verbs | 504 |
|---|---|
| Images | 126,102 |
| Situations per Image | 3 |
| Total Annotations | 1,481,851 |
| Unique Entity Types (>3) | 11,538 (6,794) |
| Unique Roles (role types) | 1,788 (190) |
| Images per Verb (range) | 250.2 (200 - 400) |
| Unique Situations (>3) | 205,095 (21,505) |
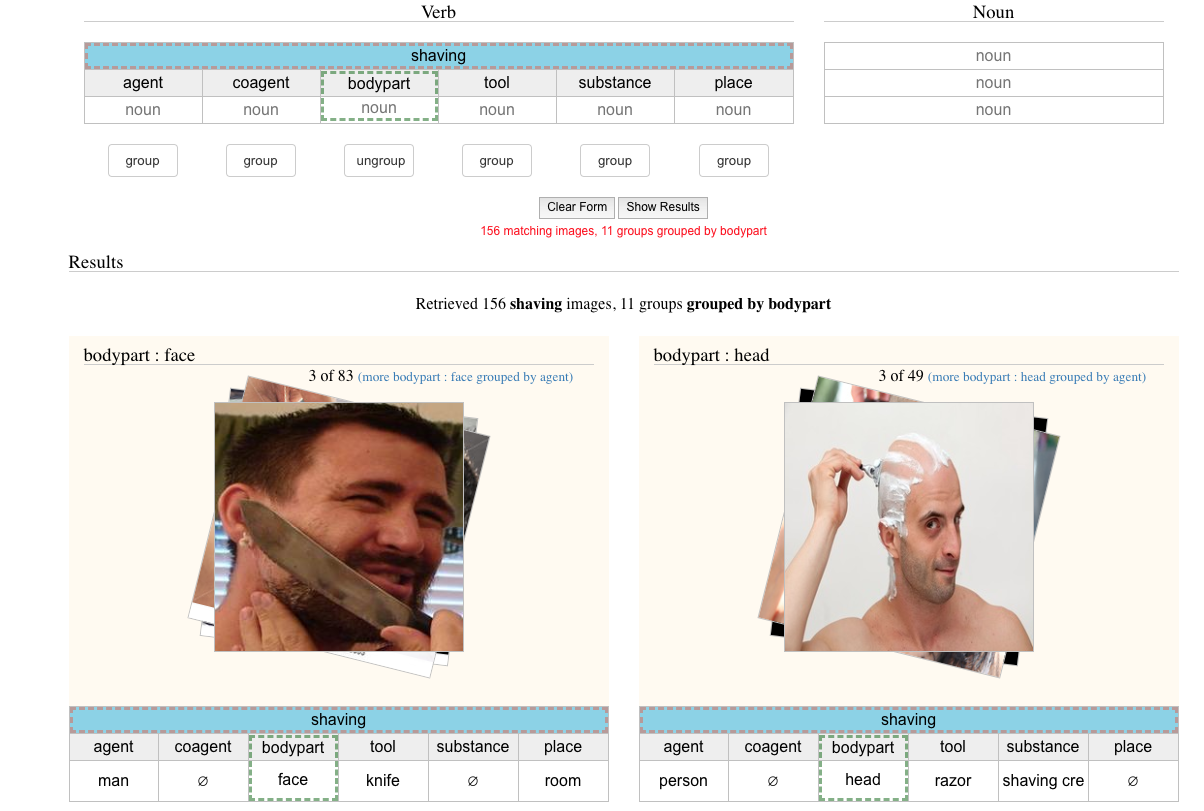
On the Browse page, you can search for images that match by verbs, nouns or both. As you select words, the dropdowns will update based on the number of remaining matching images. You can also browse using the convenient example links.
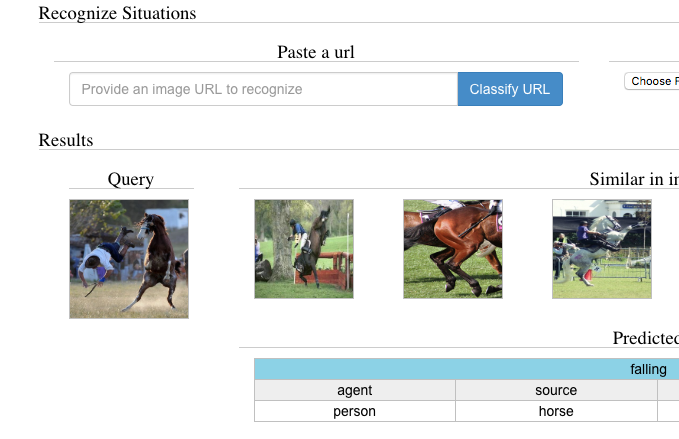
The imSitu demo will predict situations for images of your choice. You can start by clicking on the example images. The demo provides the nearest neighbors in the imSitu training set and a list of predicted situations and associated probability.
The annotations, supporting metadata and python evaluation scripts are hosted on GitHub. To download images you can follow these direct links: