
We introduce Interactive Question Answering (IQA), the task of answering questions that require an autonomous agent to interact with a dynamic visual environment. IQA presents the agent with a scene and a question, like: “Are there any apples in the fridge?” The agent must navigate around the scene, acquire visual understanding of scene elements, interact with objects (e.g. open refrigerators) and plan for a series of actions conditioned on the question. Popular reinforcement learning approaches with a single controller perform poorly on IQA owing to the large and diverse state space. We propose the Hierarchical Interactive Memory Network (HIMN), consisting of a factorized set of controllers, allowing the system to operate at multiple levels of temporal abstraction. To evaluate HIMN, we introduce IQUAD V1, a new dataset built upon AI2-THOR, a simulated photo-realistic environment of configurable indoor scenes with interactive objects. IQUAD V1 has 75,000 questions, each paired with a unique scene configuration. Our experiments show that our proposed model outperforms popular single controller based methods on IQUAD V1.
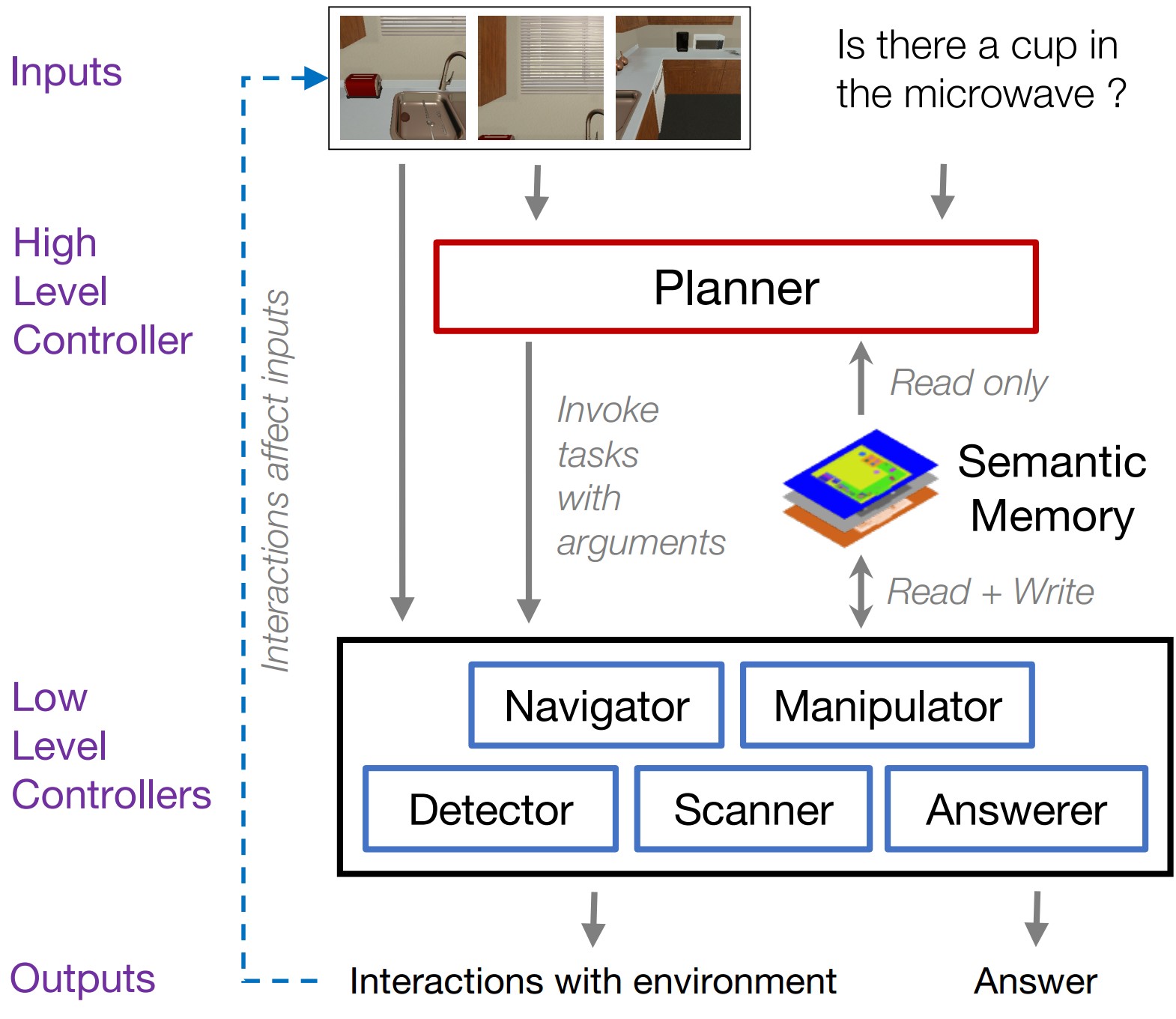
IQA poses several key challenges in addition to the ones posed by VQA. First, the agent must be able to navigate through the environment. Second, it must acquire an understanding of its environment including objects, actions, and affordances. Third, the agent must be able to interact with objects in the environment (such as opening the microwave, picking up books, etc.). Fourth, the agent must be able to plan and execute a series of actions in the environment conditioned on the questions asked of it.
To address these challenges, we propose the Hierarchical Interactive Memory Network (HIMN). Akin to past works on hierarchical reinforcement learning, HIMN is factorized into a hierarchy of controllers, allowing the system to operate, learn, and reason across multiple time scales while simultaneously reducing the complexity of each individual subtask. A high level controller, referred to as the Planner chooses the task to be performed (for example, navigation, manipulation, answering etc.) and generates a command for the chosen task. Tasks specified by the Planner are executed by a set of low level controllers (Navigator, Manipulator, Detector, Scanner and Answerer) which return control to the Planner when a task termination state is reached.
| Train | Test | |
| Existence Questions | 25600 | 1440 |
|---|---|---|
| Counting Questions | 25600 | 1440 |
| Spatial Relationship Questions | 25600 | 1440 |
| Total Questions | 76800 | 4320 |
| Unique Rooms | 25 | 5 |
| Average Number of Objects per Scene | 46 | 41 |
| Average Number of Interactable Objects per Scene | 21 | 16 |
| Vocabulary Size | 70 | 70 |
