Performing simple household tasks based on language directives is very natural to humans, yet it remains an open challenge for AI agents. The ‘interactive instruction following’ task attempts to make progress towards building agents that jointly navigate, interact, and reason in the environment at every step. To address the multifaceted problem, we propose a model that factorizes the task into interactive perception and action policy streams with enhanced components and name it as MOCA, a Modular Object-Centric Approach. We empirically validate that MOCA outperforms prior arts by significant margins on the ALFRED benchmark with improved generalization. We present extensive analysis and insights that can benefit the general paradigm of instruction following. This code can be found on GitHub.
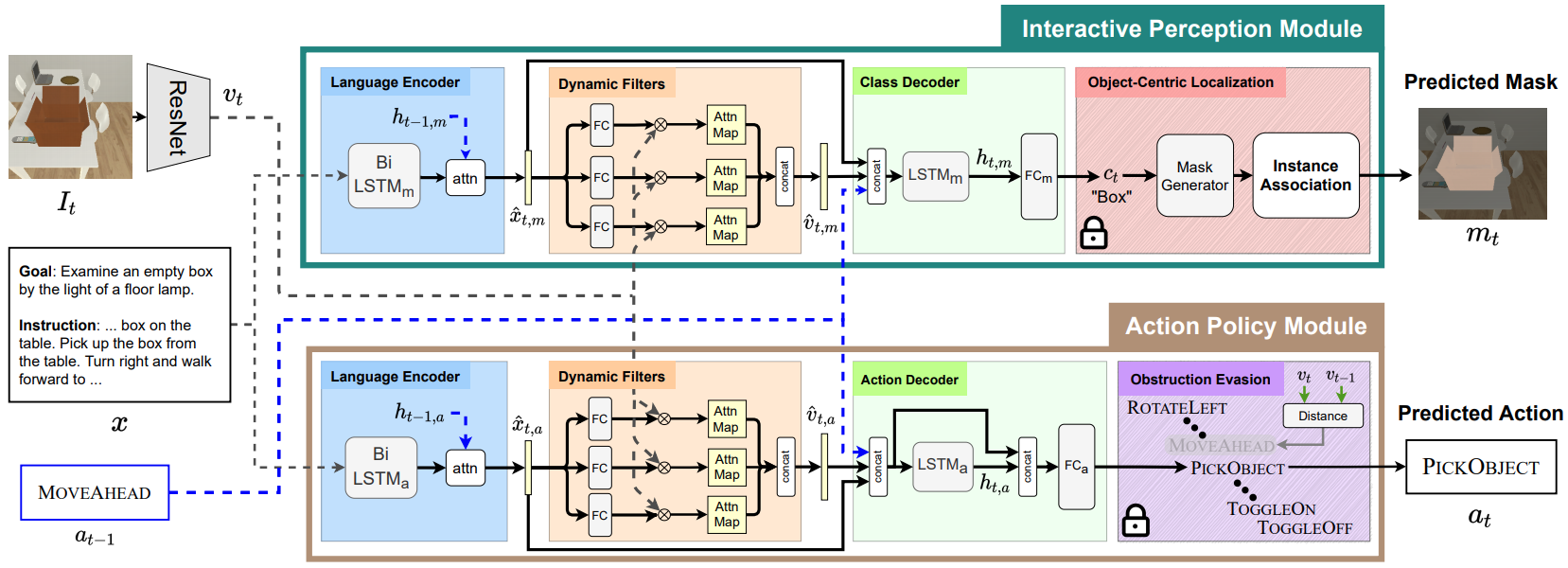
An interactive instruction following agent performs a sequence of navigational steps and object interactions based on egocentric visual observations it receives from the environment. These actions and interactions are based on natural language instructions that the agent must follow to accomplish the task. We approach this by factorizing the model into two streams, i.e. interactive perception and action policy, and train the entire architecture in an end-to-end fashion. Figure above presents a detailed overview of MOCA. For further details, please see our paper here
