We present OBJect-3DIT: a dataset and model for the 3D-aware image editing. 3D-aware image editing is the task of editing an image in a way that is consistent with a corresponding transformation in the image's underlying 3D scene. For example, different from rotating an object in the screen space of an image, a user might want to rotate that object around some axis that exists in the 3D scene. Although only the two-dimesnional image is edited in this task, a 3D-aware editing model must aquire an understanding of the complex interactions between scene objects, light and camera perspective, as well as language in our setting. We allow the user to specify an object to edit with a natural language description, in addition to providing numerical information like an exact rotation angle or a point location on the image. This combination of an intuitive language interface with precise geometric control over the edit yields an editing system that is easy to use yet highly expressive and controllable.

OBJect is a dataset that consists of 3D edits occuring in procedurally generated synthetic scenes. Using the Blender modeling and rendering engine, we generate 100k training examples for four different editing tasks: rotation, removal, insertion and translation. Each scene consists of 1-4 objects, with one of them being transformed in some way depending on the task. The objects are sourced from a 62k subset of Objaverse that has been filtered for geometric quality. Each object of this subset has also been annotated with a category and a descriptive caption written by a human annotator. The four tasks considered are explained below:
Rotation: A specified object is rotated counter-clockwise around the vertical axis passing through the object’s center of mass and perpendicular to the ground by a given angle.
Removal: An object specified with a language description is removed from the scene.
Insertion: An object matching a provided description is added to the scene at a designated x-y location.
Translation: Given the x-y coordinates of a target location, an object specified by a description is moved from its original location in the scene to the target location while preserving its angular pose and surface contact.

The model, 3DIT, is a diffusion model that is conditioned on an initial image and an editing description. Our model is finetuned from Zero123, a diffusion model that can rotate a single object by learning to render it from a new pose. We build on top of their architecture and reintroduce the language-conditioning module from StableDiffusion, because we use language descriptions to identify the edited object.
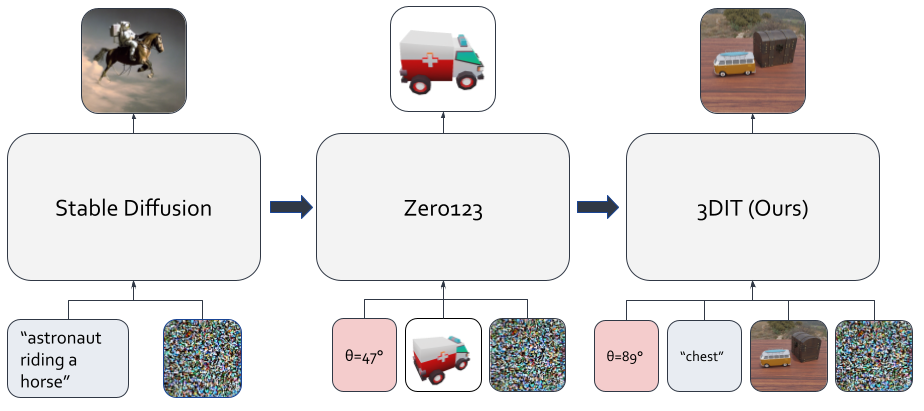

In the paper, we compare to baselines that involve chaining together off-the-shelf models for accomplishing each task. As is evident in the results, this inevitably leads to error propagation and edits that are not consistent with the 3D transformation of the scene.

Here we show that the model has aquired the ability to edit scenes in the real world, even though it was only trained on synthetic data.






