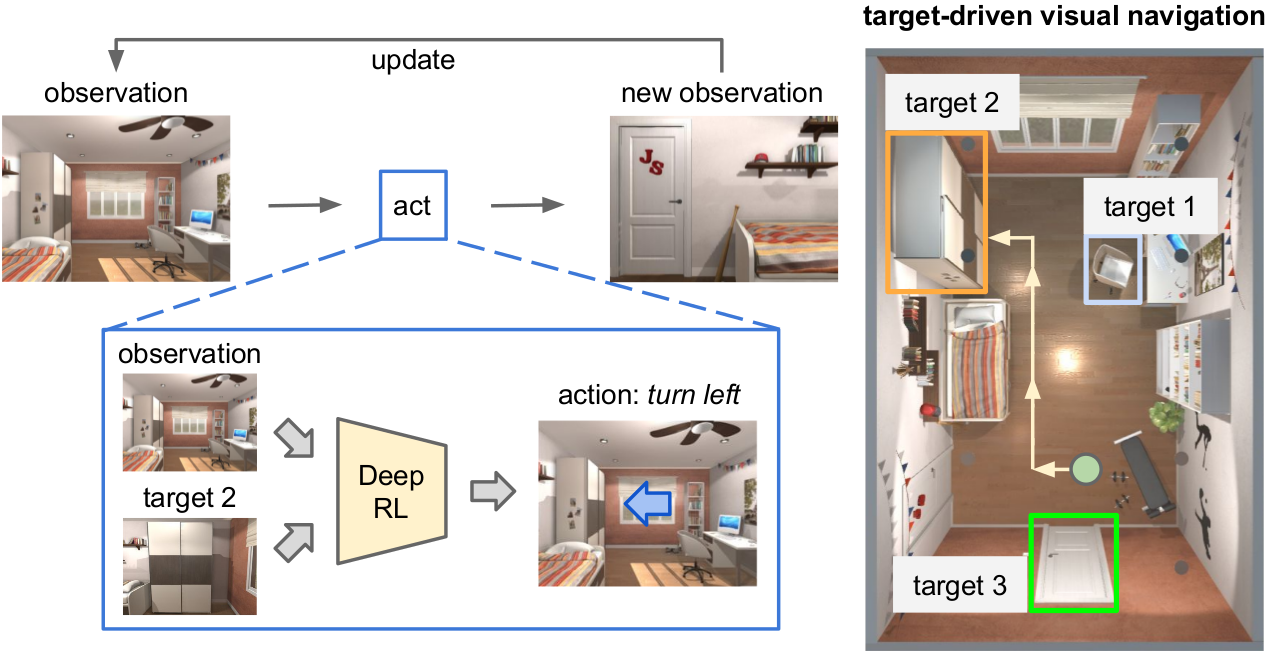
In this project, we tackle the problem of visual navigation using Deep Reinforcement Learning. The agent operates based only on visual input. We show that training can be performed more efficiently using our proposed approach and demonstrate generalization to new targets. We also show that a model that is trained in the virtual environment can generalize to a real world setting with a small amount of fine-tuning.