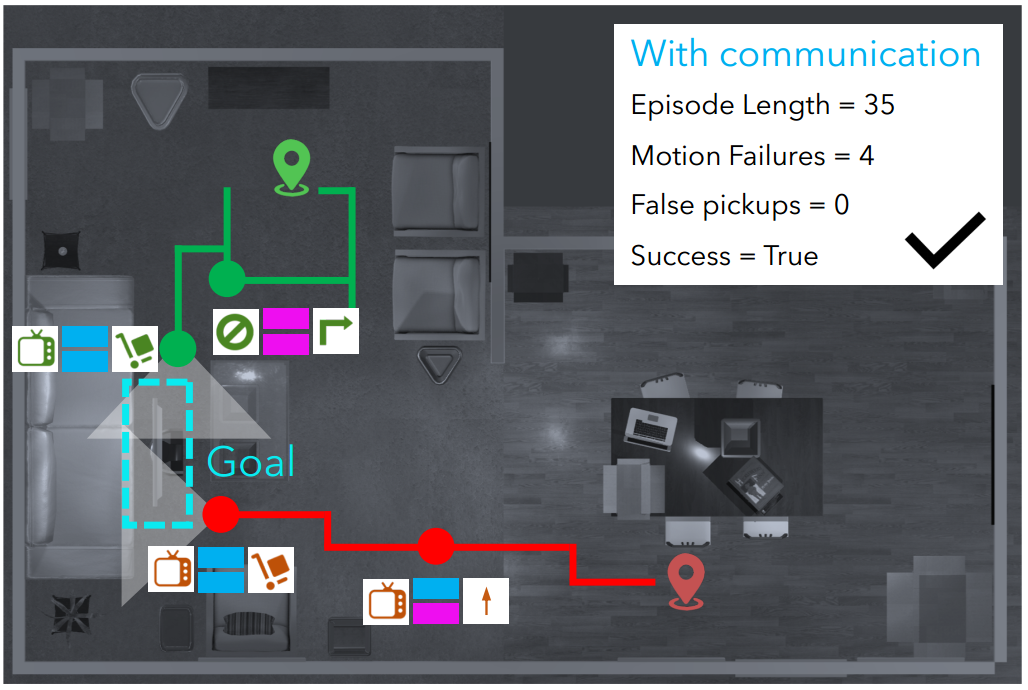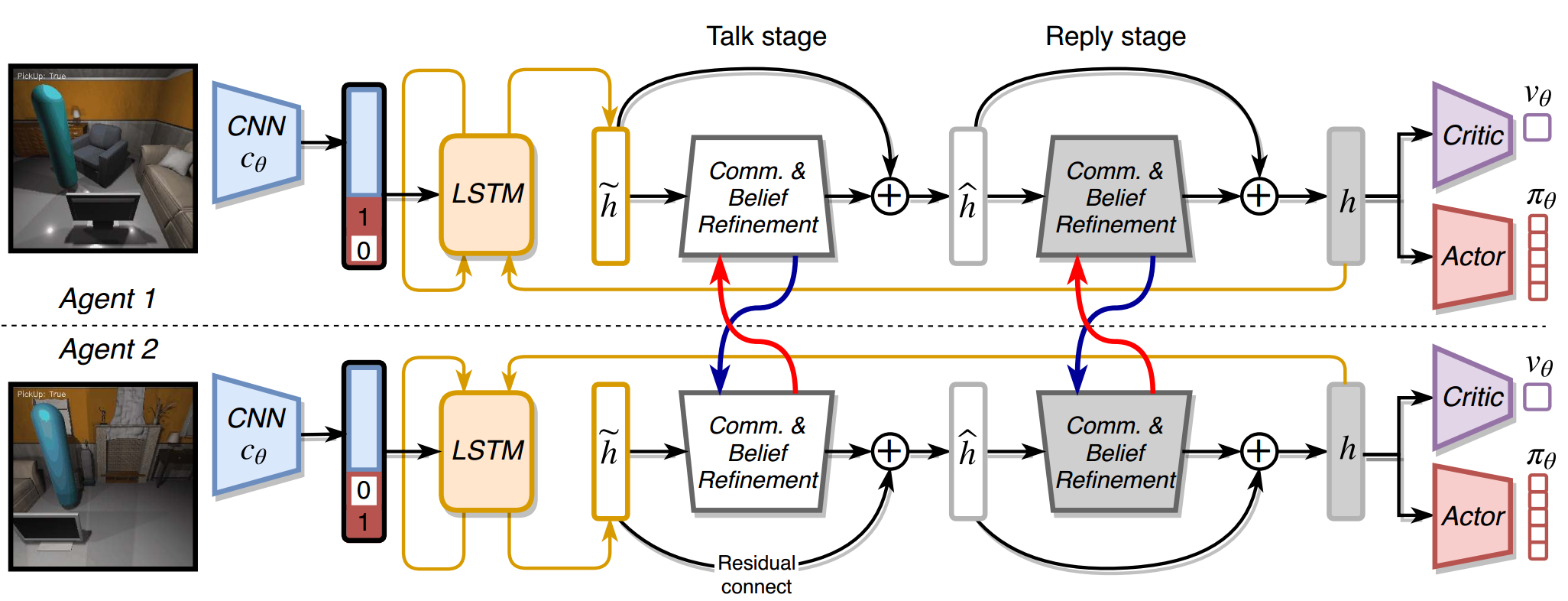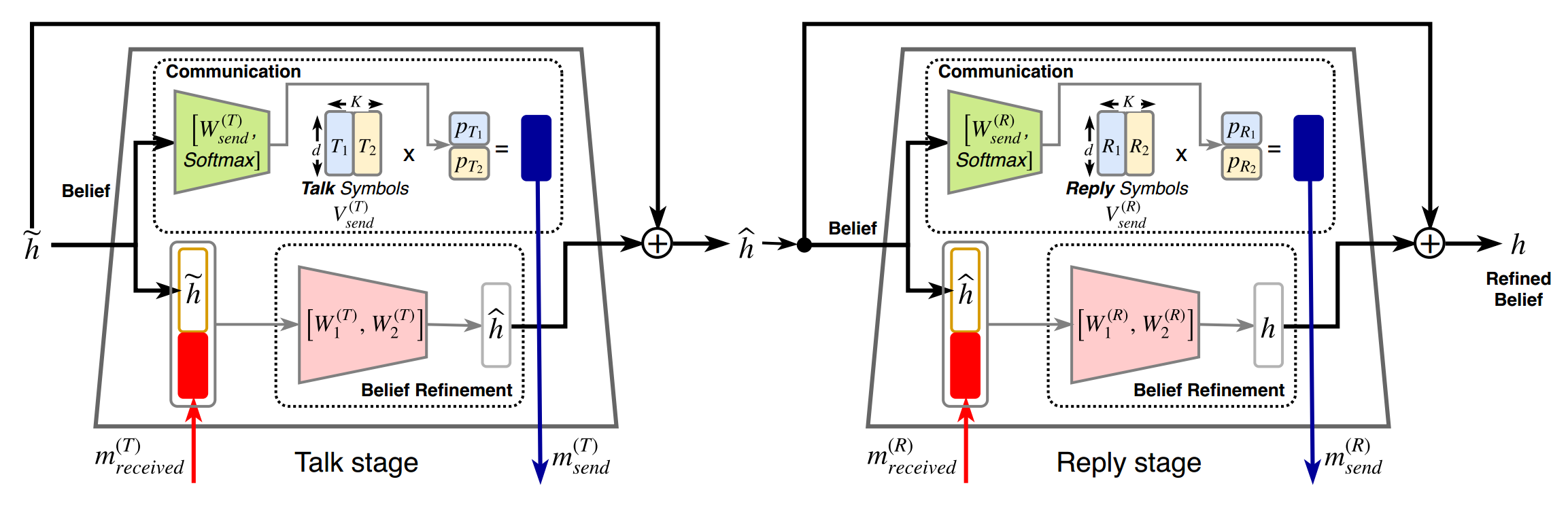
Collaboration is a necessary skill to perform tasks that are beyond one agent's capabilities. Addressed extensively in both conventional and modern AI, multi-agent collaboration has often been studied in the context of simple grid worlds. We argue that there are inherently visual aspects to collaboration which should be studied in visually rich environments. A key element in collaboration is communication that can be either explicit, through messages, or implicit, through perception of the other agents and the visual world. Learning to collaborate in a visual environment entails learning (1) to perform the task, (2) when and what to communicate, and (3) how to act based on these communications and the perception of the visual world. In this paper we study the problem of learning to collaborate directly from pixels in AI2-THOR and demonstrate the benefits of explicit and implicit modes of communication to perform visual tasks.
Metrics
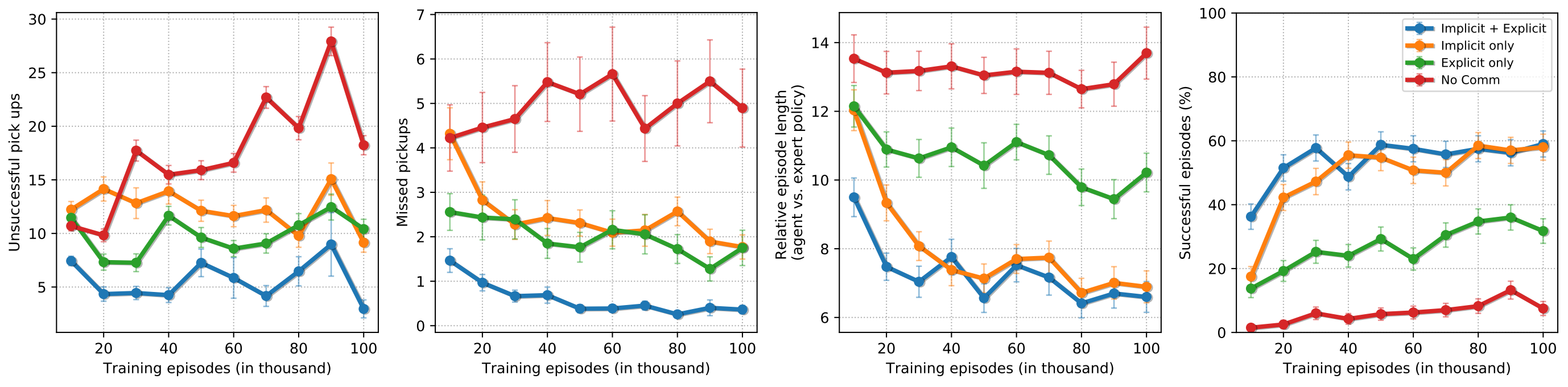
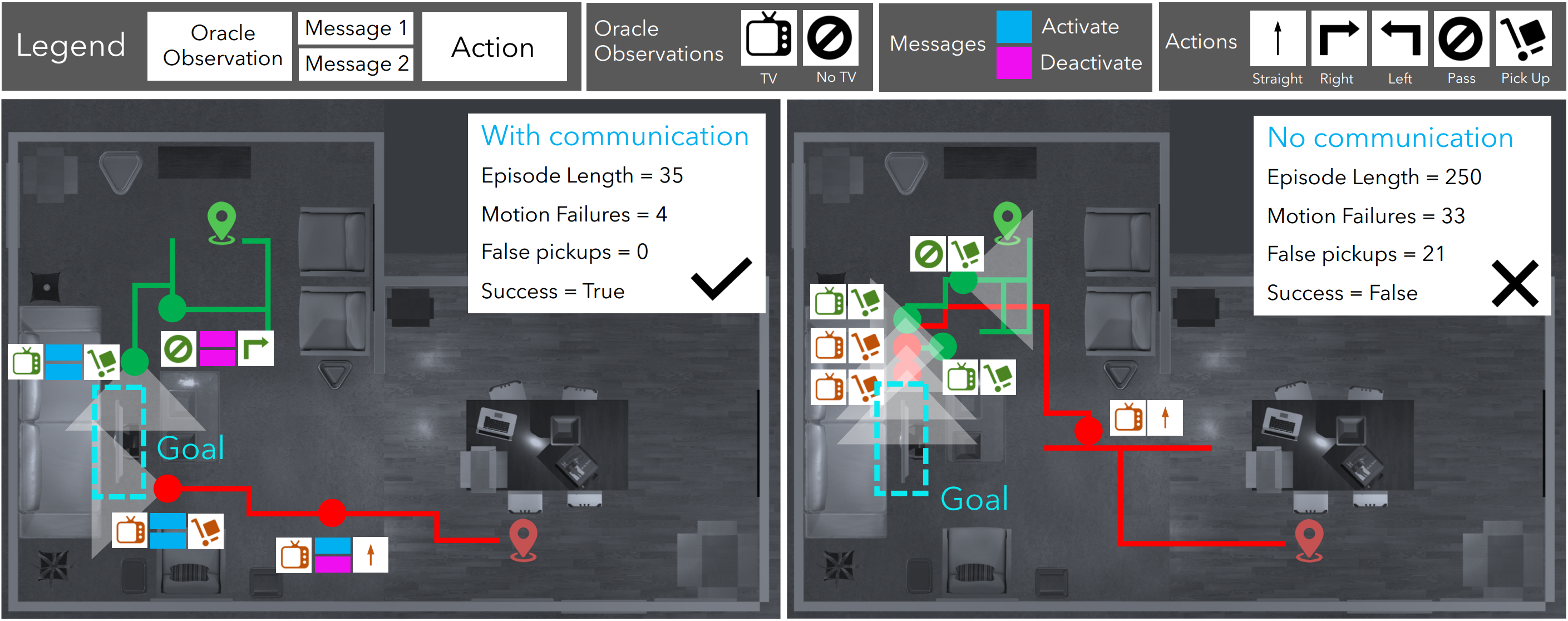
We consider the following metrics:
(1) Reward,
(2) Accuracy: Percentage of successful episodes,
(3) Number of Failed pickups,
(4) Number of Missed pickups: where both agents could have picked up the object but did not,
(5) Relative episode length: relative to an oracle.
These metrics are aggregated over 400 random initializations (Unseen scenes: 10 scenes x 40 inits, Seen scenes: 20 scenes x 20 inits).
Note that accuracy alone isn't revealing enough. Naive agents that wander around and randomly pick up objects will eventually succeed. Also, agents that correctly locate the TV and then keep attempting a pickup in the hope of synchronizing with the other agent will also succeed. Both these cases will however do poorly on the other metrics.