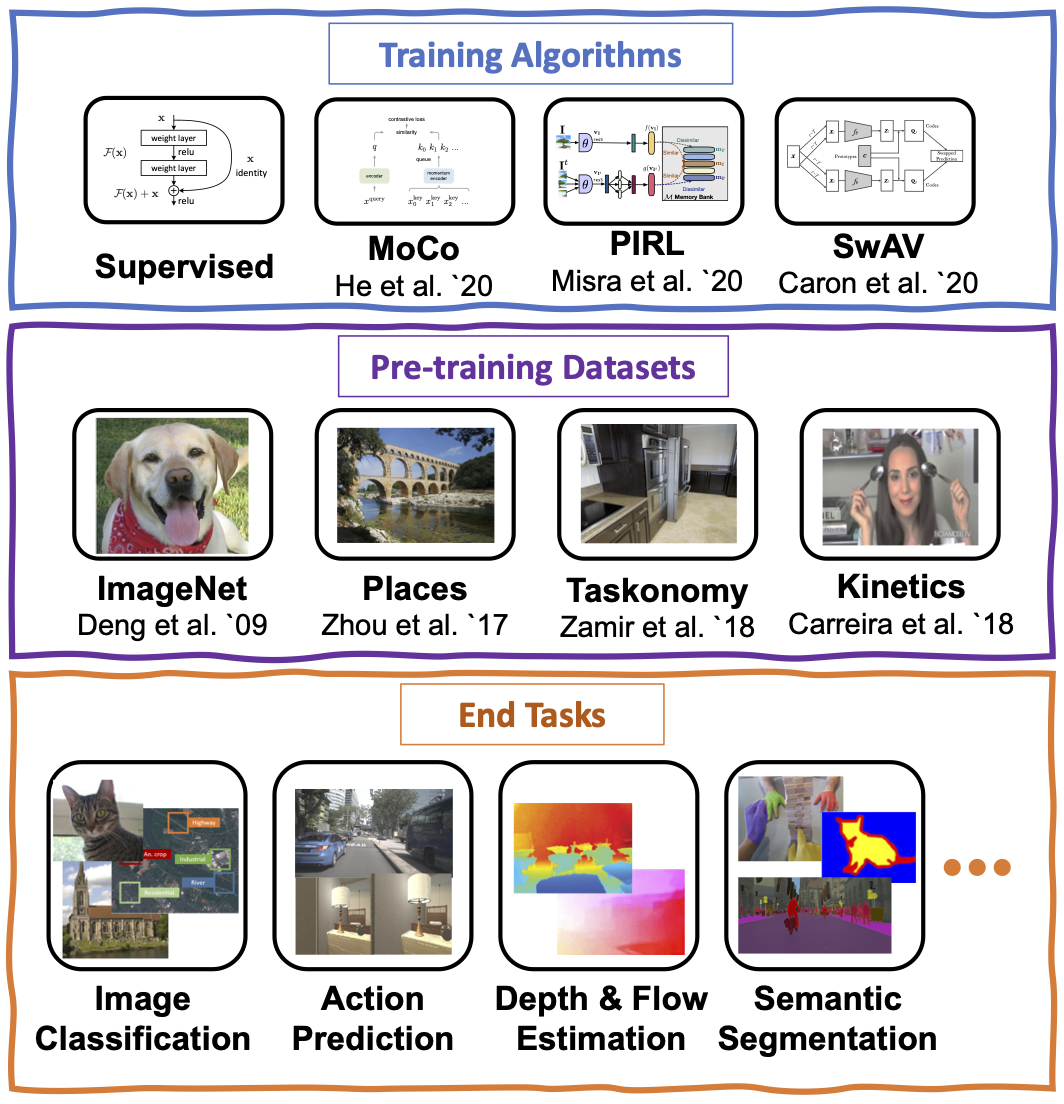
In the past few years, we have witnessed remarkable breakthroughs in self-supervised representation learning. Despite the success and adoption of representations learned through this paradigm, much is yet to be understood about how different training methods and datasets influence performance on downstream tasks. To help us study this domain and promote further research we created an efficient and expansive open sourced benchmarking tool caled ViRB. This code can be found on GitHub.
ViRB is a framework for evaluating the quality of representations learned by visual encoders on a variety of downstream tasks. It is the codebase used by the paper Contrasting Contrastive Self-Supervised Representation Learning Pipelines. As this is a tool for evaluating the learned representations, it is designed to freeze the encoder weights and only train a small end task network using latent representations on the train set for each task and evaluate it on the test set for that task. To speed this process up, the train and test set are pre encoded for most of the end tasks and stored in GPU memory for efficient usage. Fine tuning the encoder is also supported but takes significantly more time. ViRB is fully implemented in pyTorch and automatically scales to as many GPUs as are available on your machine. It has support for evaluating any pyTorch model architecture on a select subset of tasks.

ViRB supports 20 end task that are classified as Image-level or Pixelwise depending on the output modality of the task. Furthermore each task is also classified as either semantic or structural. Above is an illustration of the space of our tasks. For further details please see Contrasting Contrastive Self-Supervised Representation Learning Pipelines.
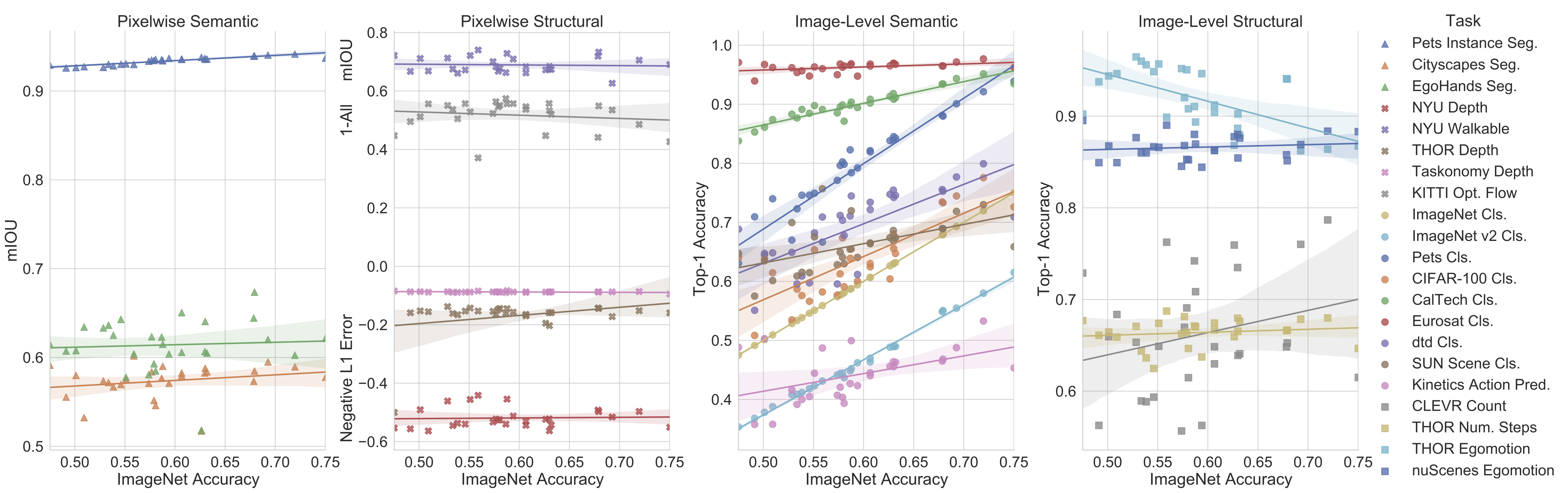
This figure is from the paper Contrasting Contrastive Self-Supervised Representation Learning Pipelines, and it shows the correlation of end task performances with ImageNet classification accuracy. The plots show the end task performance against the ImageNet top-1 accuracy for all end tasks and encoders. Each point represents a different encoder trained with different algorithms and datasets. This reveals the lack of a strong correlation between the performance on ImageNet classification and tasks from other categories. This is one of many interesting trends that we could detect after running over 700 experiments, enabled by the efficiency of ViRB.