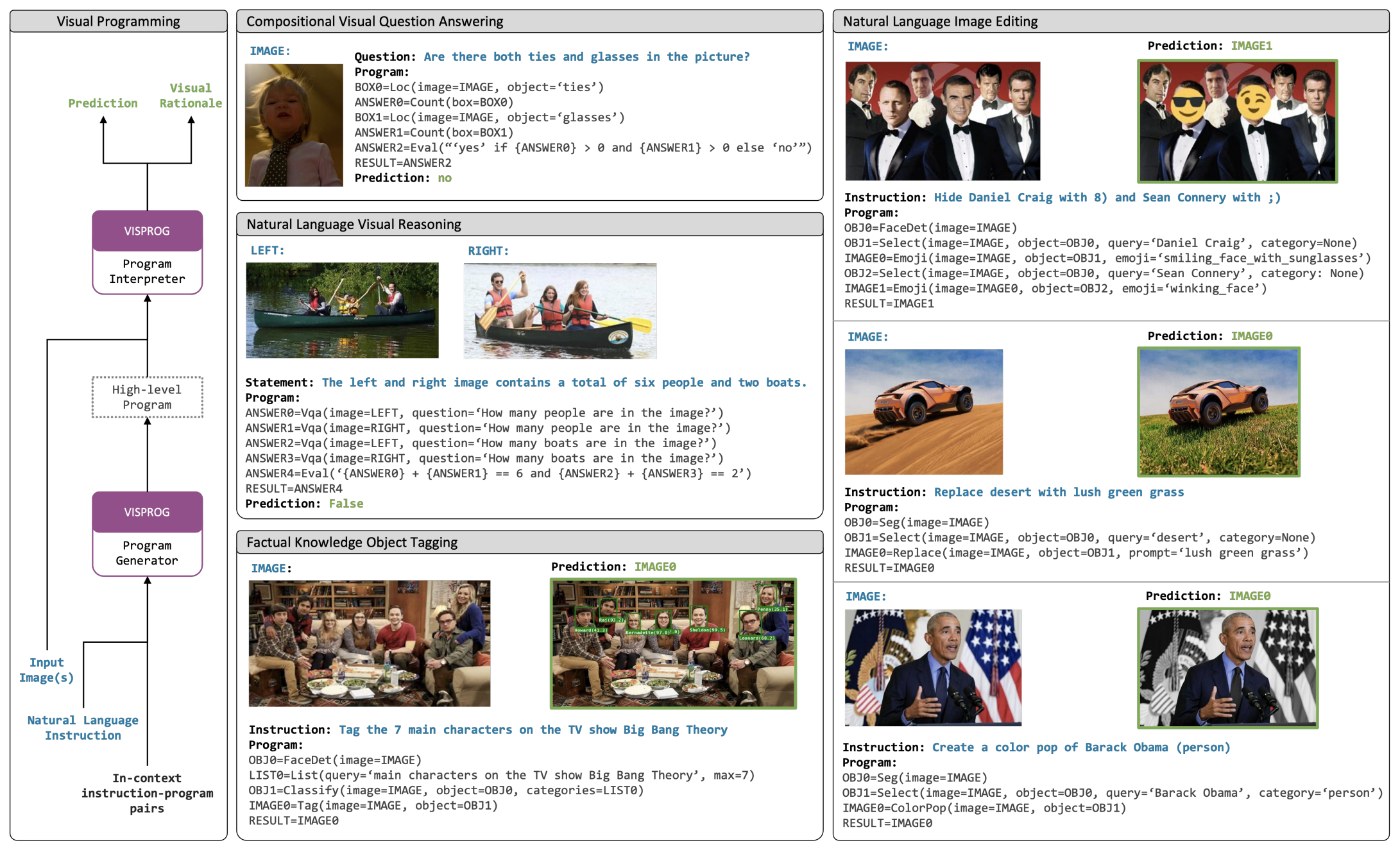
VISPROG is a modular and interpretable neuro-symbolic system for compositional visual reasoning. Given a few examples of natural language instructions and the desired high-level programs, VISPROG generates a program for any new instruction using in- context learning in GPT-3 and then executes the program on the input image(s) to obtain the prediction. VISPROG also summarizes the intermediate outputs into an interpretable visual rationale (Fig. 4). We demonstrate VISPROG on tasks that require composing a diverse set of modules for image understanding and manipulation, knowledge retrieval, and arithmetic and logical operations
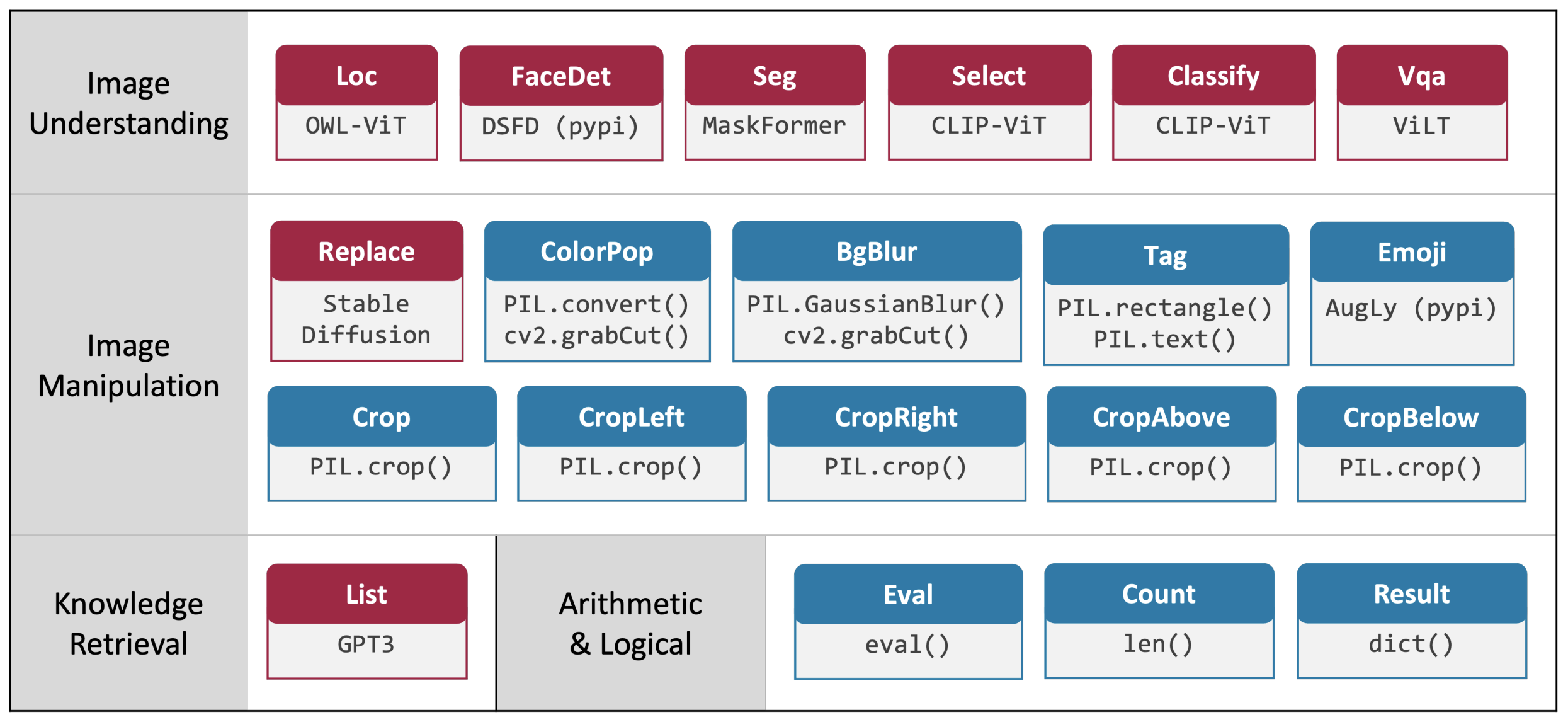
VisProg generates programs by prompting an LLM, GPT-3, with an instruction along with in-context examples consisting of instructions and corresponding programs. Unlike previous approaches like Neural Module Network

Not only does VisProg produce a highly interpretable program, it also generates a visual rationale by stiching together a summary of the inputs and outputs of each step to help understand and the debug the information flow while executing the program. Below are two such visual rationales.


We demonstrate VisProg on a range of complex visual tasks such as compositional visual question answering, zero-shot reasoning about image pairs (using only a single-image VQA model), factual knowledge object tagging, and language-guided image editing. The following figure shows the capabilities of VisProg on object tagging and image editing tasks.

Here are many more qualitiate results along with visual rationales for all tasks. We also include failure cases dues to logical errors in the generated program or due to error in a module's prediction.


