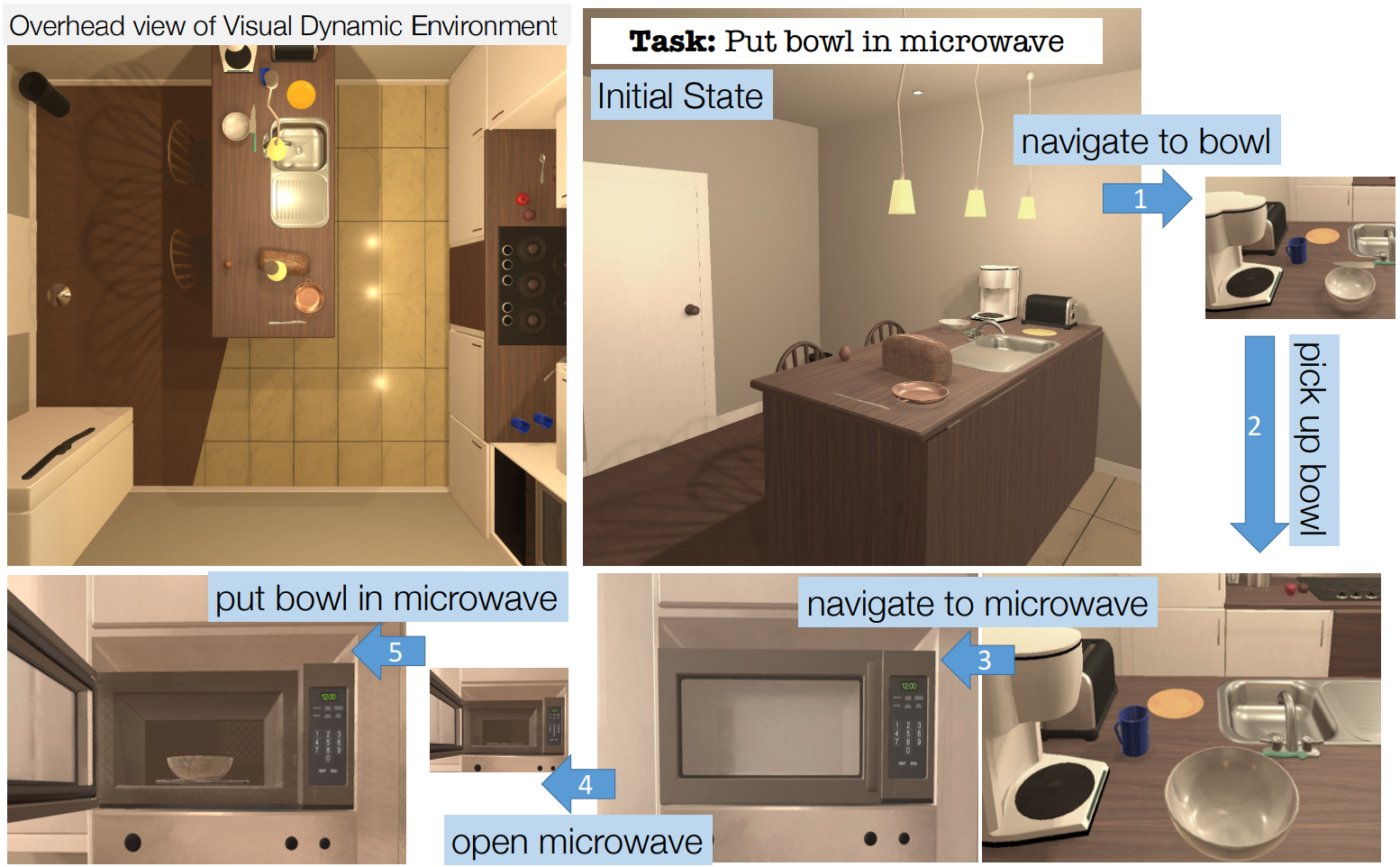
A crucial capability of real-world intelligent agents is their ability to plan a sequence of actions to achieve their goals in the visual world. In this work, we address the problem of visual semantic planning: the task of predicting a sequence of actions from visual observations that transform a dynamic environment from an initial state to a goal state. Doing so entails knowledge about objects and their affordances, as well as actions and their preconditions and effects. We propose learning these through interacting with a visual and dynamic environment. Our proposed solution involves bootstrapping reinforcement learning with imitation learning.