Recent multi-modal transformers have achieved tate of the art performance on a variety of multimodal discriminative tasks like visual question answering and generative tasks like image captioning. This begs an interesting question: Can these models go the other way and generate images from pieces of text? Our analysis of a popular representative from this model family - LXMERT - finds that it is unable to generate rich and semantically meaningful imagery with its current training setup. We introduce X-LXMERT, an extension to LXMERT with training refinements. X-LXMERT's image generation capabilities rival state of the art generative models while its question answering and captioning abilities remains comparable to LXMERT.
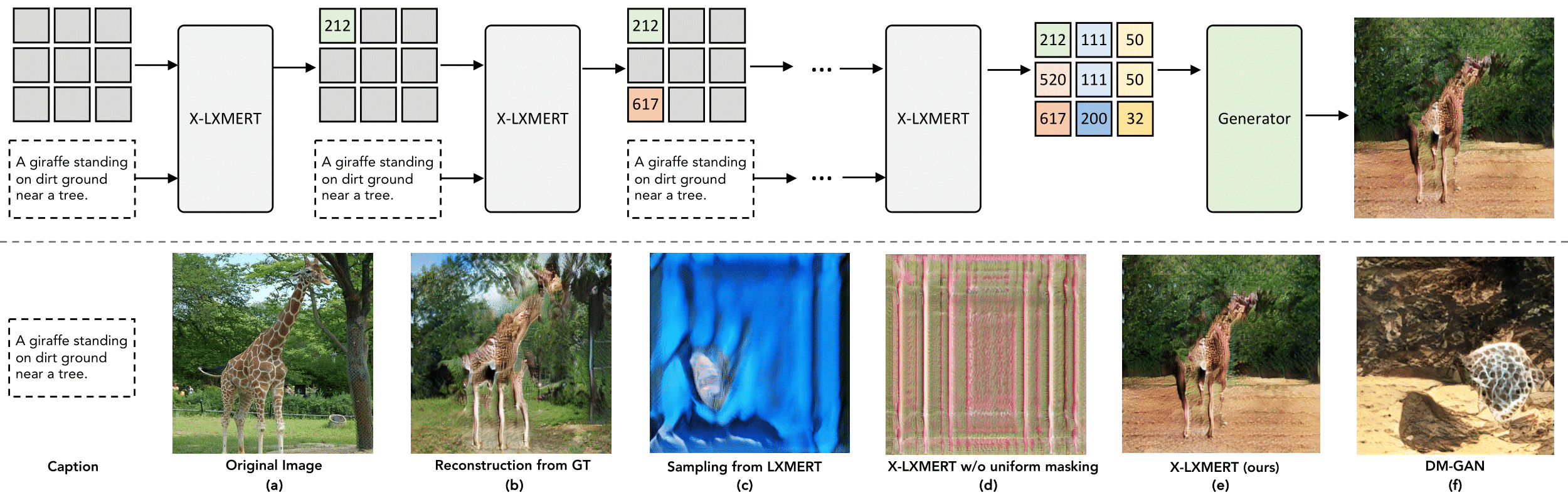
In order to make LXMERT paint, we first modify its input image representation to a N x N grid based features and then pass the set to an image generator. Then, we introduce three key training refinements for LXMERT:
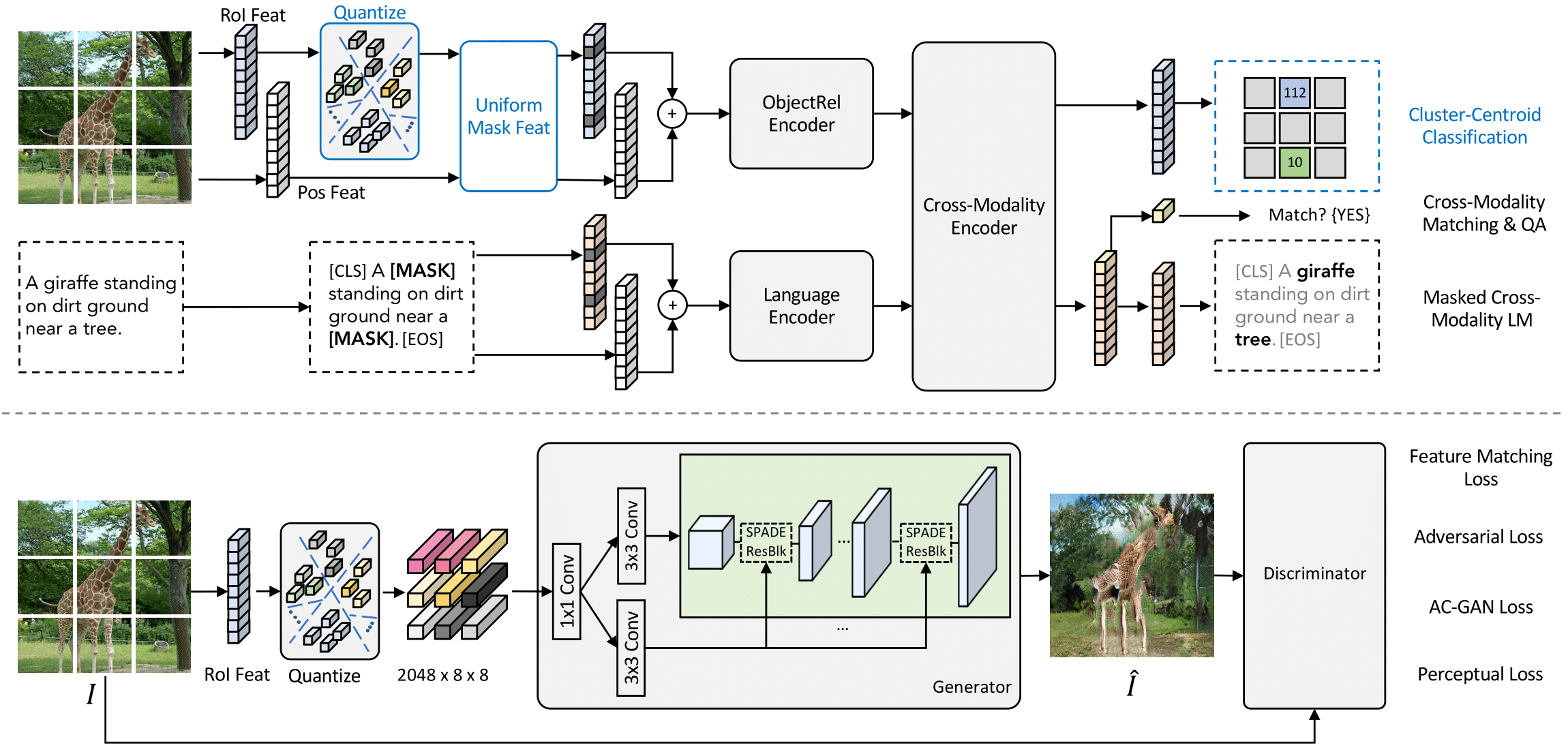
We employ Gibbs sampling to iteratively sample features at different spatial locations. In contrast to text generation, where left-to-right isconsidered a natural order, there is no natural orderfor generating images. We explore different sampling strategies for X-LXMERT.
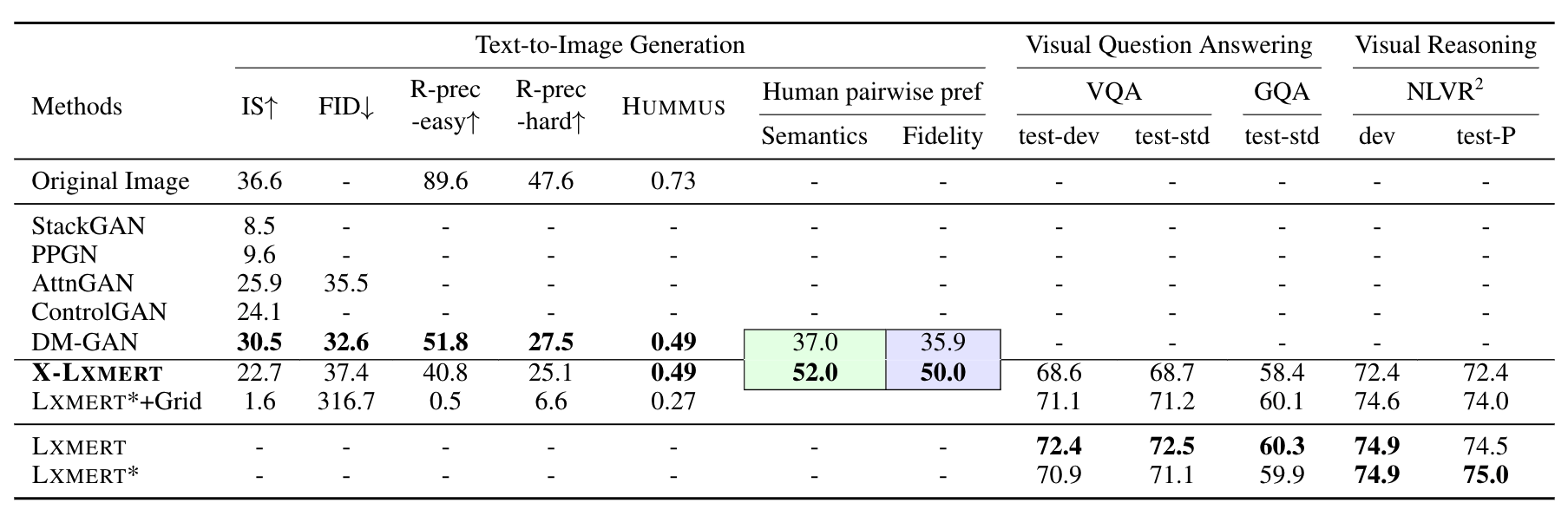
X-LXMERT’s image generation capabilities rival models specialized in image generation. In fact, human annotators prefer the images from X-LXMERT than DM-GAN, a state-of-the-art competitor. In the same time, X-LXMERT retain very competitive performance on isual question answerin and reasoning benchmarks with minimal drop.
The below figures shows some qualitative analysis for text-to-image generation with X-LXMERT. The top and middle row demonstrate how the spatial visual features are gradually updated as the sampling steps proceed. The bottowm row compare X-LXMERT equipped with different sampling strategies with baselines.



Explore text-to-image generation with X-LXMERT in the AI2 Computer Vision Explorer.
Coming soon.