
5.7k real-world videos, 75k simulated videos, 3 physical reasoning principles, 3 viewpoints, ~30 objects
The InfLevel benchmark contains thousands of real-world, and simulated, videos designed to test the core physical reasoning abilities of modern AI systems...

10K Interactive Houses, Procedurally Generate Infinitely More Environments
ProcTHOR is a platform to massively scale Embodied AI by procedurally generating realistic, interactive, and diverse simulated 3D houses and environments

77 hours, 35 participants, 10 IMUs, Eye Tracker
The HAVIET contains diverse recordings of participants' observations, movements and gaze while performing variety of diverse tasks.

30 scenes, 72k object locations, 12 object categories
The APND dataset contains diverse set of locations of the objects in the room.
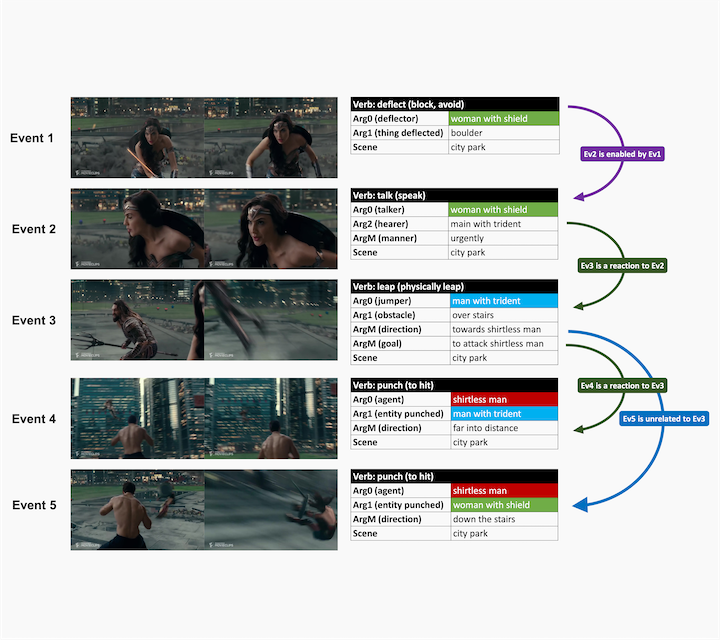
29K 10-second Movie Clips, 145K Events with verbs, semantic role labels, entitycoreferences, and event relations.
VidSitu is a large-scale dataset containing diverse 10-second videos from movies depicting complex situations.

126,102 situations, 278,336 bounding boxes
The SWiG dataset contains situations describing the primary action in the image with groundings for all involved agents/objects.

25K natural language directives
A benchmark for learning a mapping from natural language instructions and egocentric vision to sequences of actions for household tasks.

More than 14000 questions
The OKVQA dataset is composed of questions that require outside knowledge to be answered.

8,290 images, 154,420 pairs, 76,642 annotations
Three part-annotated datasets of images and pairs for a part labeling task.

Images from 11 indoor scenes from AI2-Thor, ~60 objects per scene
A dataset of synthetic occluded objects. This is a synthetic dataset with photo-realistic images and natural configuration of objects in scenes.

380 video clips (24,500 frames) with corresponding joint information
A dataset of ego-centric dog video and joint movements.

7,860 videos, 68,536 temporal annotations, 157 action classes
A dataset of daily indoors activities filmed from third and first person with temporal annotations for various action classes.

75,000 questions, each paired with a unique scene configuration
IQUAD V1 pairs unique scene configurations in the AI2-THOR environment with questions corresponding to those environments.

More than 5,000 images of 10,000 liquid containers in context
COQE contains images of liquid containers labelled with volume, amount of content, bounding box annotation, and 3D CAD models.
1 thousand textbook lessons, 26k questions, 6k images
The TextbookQuestionAnswering (TQA) dataset is drawn from middle school science curricula.
60k figures extracted from 20k papers
Figures from 20k papers annotated as scatterplot, flowchart, etc. Over 600 figures were given futher detailed annotations (i.e., axes, legends, plot data,...
4,903 images
AI2D is a dataset of illustrative diagrams for research on diagram understanding and associated question answering.

126k images, 1.5 million annotations
imSitu is a dataset supporting situation recognition, the problem of producing a concise summary of the situation an image depicts.

Augmented NYUv2 dataset including task-based annotations.

9,850 videos
This dataset guides our research into unstructured video activity recognition and commonsense reasoning for daily human activities.

Interactive dataset of 10,335 scenes
Scenes from the SUN RGB-D dataset rendered synethically with the Blender physics engine allowing for force interaction.

This is the dataset associated with the Newtonian Image Understanding research project.